DECLARE @I INT
SET @I = 1;
INSERT INTO [dbo].[A]
VALUES
(
'NAME',
'PWS'
)
WHILE @I <= 20
BEGIN
INSERT INTO [dbo].[A]
SELECT [username],
[pwd]
FROM [dbo].[A]
SET @I = @I + 1;
END
GO
UPDATE [dbo].[A]
SET [username] = [username] + CAST([ID] AS VARCHAR)
GO
ALTER TABLE A ADD CONSTRAINT pk_id PRIMARY KEY NONCLUSTERED(id)
CREATE CLUSTERED INDEX idx_username ON A(username)
CREATE TABLE [dbo].[B](
[ID] [int] NOT NULL,
[username] [varchar](50) NULL,
[score] [nchar](10) NULL
) ON [PRIMARY]
GO
INSERT INTO [dbo].[B] SELECT id,
[username],
CASE WHEN ID%2=1
THEN 81 ELSE 79 END FROM [dbo].[A]
GO
ALTER TABLE B ADD CONSTRAINT pk_id PRIMARY KEY NONCLUSTERED(ID)
CREATE CLUSTERED INDEX idx_b_score ON B(score)
CREATE NONCLUSTERED INDEX idx_b_username ON B(username)
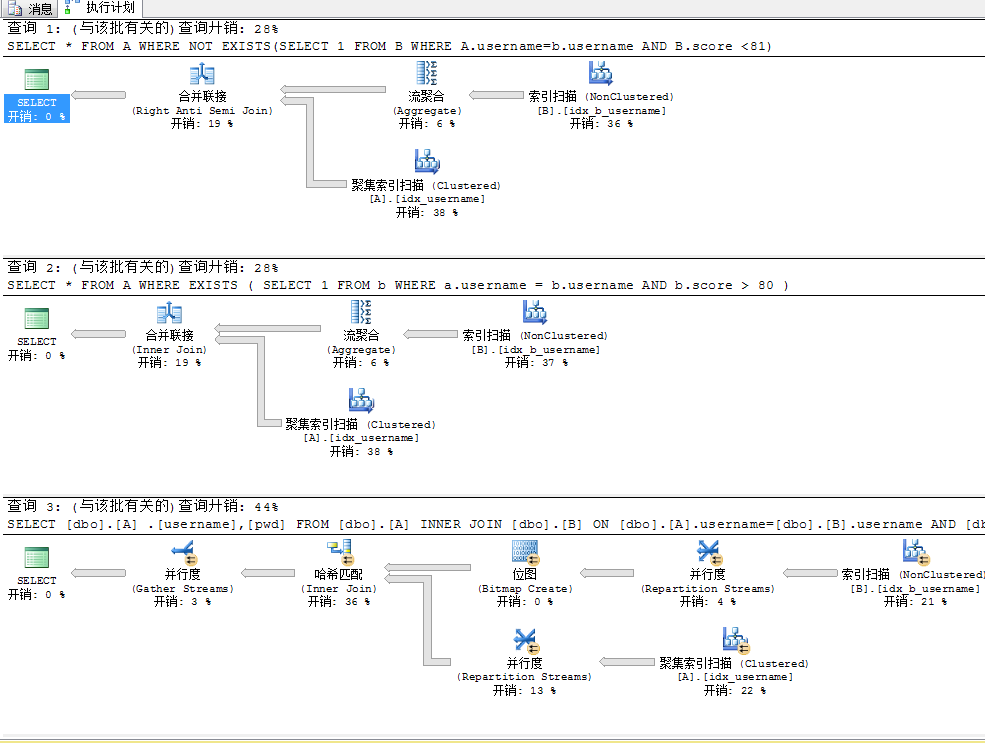
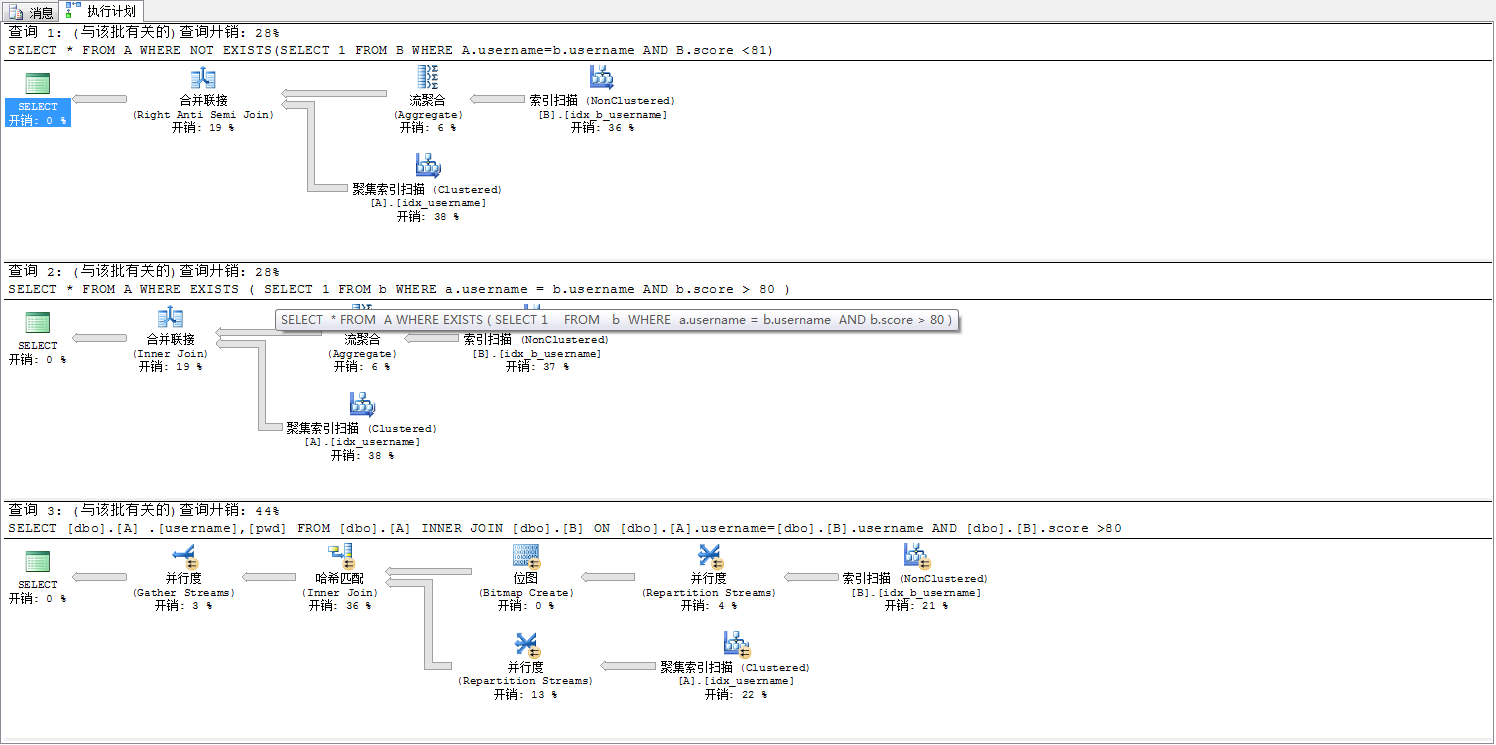
SELECT * FROM A WHERE NOT EXISTS(SELECT 1 FROM B WHERE A.username=b.username AND B.score <81)
SELECT * FROM A WHERE EXISTS ( SELECT 1 FROM b WHERE a.username = b.username AND b.score > 80 )
SELECT [dbo].[A] .[username],[pwd] FROM [dbo].[A]
INNER JOIN [dbo].[B] ON [dbo].[A].username=[dbo].[B].username AND [dbo].[B].score >80



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享








 。
。

 都是高手啊.!
都是高手啊.!
