社区
Hadoop生态社区
帖子详情
mahout训练贝叶斯模式分类准确率不高
编程原理
2013-10-22 09:43:09
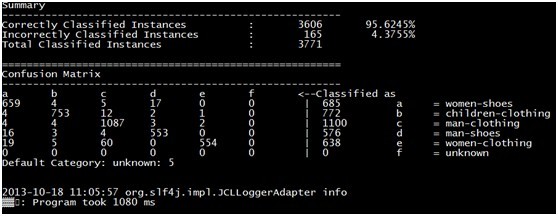
mahout训练贝叶斯模式分类准确率不高,如下图,在剔除一个训练样本数据后,准确率提升两个百分点,证明剔除掉的一个样本对其他样本分类产生影响,有什么办法提高贝叶斯模型分类的准确率呢?
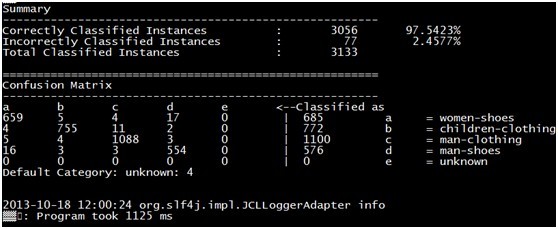
剔除样本women-clothing样本后的训练结果如下图:
...全文
612
5
打赏
收藏
mahout训练贝叶斯模式分类准确率不高
mahout训练贝叶斯模式分类准确率不高,如下图,在剔除一个训练样本数据后,准确率提升两个百分点,证明剔除掉的一个样本对其他样本分类产生影响,有什么办法提高贝叶斯模型分类的准确率呢? 剔除样本women-clothing样本后的训练结果如下图:
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
beowulf2005
2013-11-01
打赏
举报
回复
几千个数据动用hadoop,嗯,杀鸡用牛刀,费电不? 你这数据量乘以10的6次方以后再整hadoop吧。
spmydl
2013-11-01
打赏
举报
回复
能问问 您在 20-news的基础上做了哪些改动
编程原理
2013-10-23
打赏
举报
回复
增加测试数据后结果一样的,增加样本会增加其词频出现的不确定性,主要是现在样本是用庖丁词库分词的,对于服装领域庖丁分词不够精致,造成构造训练样本的时候分类不够精准,所以训练出来的模型总会有误差,现在关键要能得到训练模型的日志,在分类的时候能够找出分错位置的样本文本,这样把错误的文本剔除掉应该就能提高模型的准确率了,问题就在,怎么找出分错位置的文本
kissstefani
2013-10-22
打赏
举报
回复
学习,下个月会用到。
撸大湿
2013-10-22
打赏
举报
回复
1、增加样本数据量,感觉你的样本量太少 2、增加测试次数
Hadoop海量网络数据处理平台的关键技术
最后通过实验证明,基于
分类
器联合的分布式异常流量检测算法可以快速有效地对海量网络数据流进行检测,并保持较高的检测
准确率
和较低的误报率。该算法可以有效地提高云平台的安全性,是对云平台网络安全防御体系的有效...
Mahout
实践:
Mahout
分类
算法-11
本实验在Hadoop集群已经部署的前提下,使得
mahout
运行local
模式
下,然后做
mahout
的
分类
算法分析。 实验时长:45分钟 主要步骤: 打开hadoop集群 数据准备 修改
mahout
相关环境变量 数据预处理
训练
分类
器 测试
分类
器...
大数据机器学习实战
本课程从数据挖掘介绍及工具安装开始,逐步讲解数据挖掘建模及多种常用算法编程实践。通过详尽的理论讲解及细致入微的操作演示,让学员充分理解与掌握数据分析挖掘的每一个操作细节,以便快速掌握数据分析挖掘的工作...
mahout
bayesian
Bayesian算法是一种利用概率统计知识进行
分类
的算法,在许多场合,朴素
贝叶斯
的
分类
算法可以与决策树和神经网络
分类
算法相媲美,该算法能运用到大型数据库中,且方法简单、
分类
准确率
高、速度快。这个算法是在
贝叶斯
...
【大数据分析与挖掘技术】
Mahout
分类
算法
分类
是使用特定信息从一个预定义的潜在回应列表中做出单一选择的过程。本篇文章介绍
分类
的概念,和一些在
Mahout
中的常见的
训练
分类
器的算法。
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





