

111,111
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
Dictionary<Type, Dictionary<string, RegistObjectContext>()> dic;
if(!dic.ContainsKey(key)){
dic.Add(key, new Dictionary<string, RegistObjectContext>());
}
cDic = dic[key];
try
{
cDic = dic[pType];
}
catch (KeyNotFoundException)
{
dic.Add(pType, new Dictionary<string, RegistObjectContext>());
cDic = dic[pType];
}

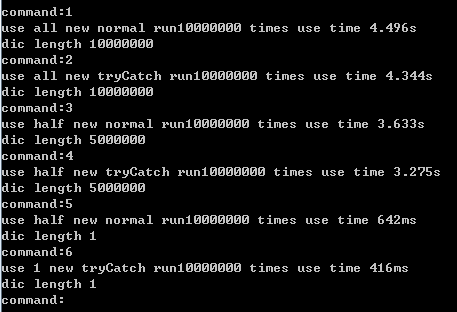
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace TryCatchTest
{
class Program
{
private static string[] strUnit = { "bytes", "kb", "mb", "gb" };
private static string[] strDateUnit = { "ms", "s", "m", "h" };
private string readCommand()
{
Console.Write("command:");
var command = Console.ReadKey();
Console.WriteLine();
return command.KeyChar.ToString();
}
static void Main(string[] args)
{
Program program = new Program();
Console.WriteLine("Please input howmany times to run");
int count = int.Parse(Console.ReadLine());
Console.WriteLine("Please enter command...");
Console.WriteLine("1. run all new normal");
Console.WriteLine("2. run all new tryCatch");
Console.WriteLine("3. run half new normal");
Console.WriteLine("4. run half new tryCatch");
Console.WriteLine("0. exit");
var command = program.readCommand();
Dictionary<string, string> dic;
try
{
while (command != "0")
{
switch (command)
{
case "1":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = p.ToString();
if (!dic.ContainsKey(key))
{
dic.Add(key, key);
}
else
{
dic[key] = key;
}
}, "all new normal");
break;
case "2":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = p.ToString();
try
{
dic[key] = key;
}
catch (KeyNotFoundException)
{
dic.Add(key, key);
}
}, "all new tryCatch");
break;
case "3":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = (p / 2).ToString();
if (!dic.ContainsKey(key))
{
dic.Add(key, key);
}
else
{
dic[key] = key;
}
}, "half new normal");
break;
case "4":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = (p / 2).ToString();
try
{
dic[key] = key;
}
catch (KeyNotFoundException)
{
dic.Add(key, key);
}
}, "half new tryCatch");
break;
case "5":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = "1";
if (!dic.ContainsKey(key))
{
dic.Add(key, key);
}
else
{
dic[key] = key;
}
}, "half new normal");
break;
case "6":
dic = new Dictionary<string, string>();
program.run(count, p =>
{
string key = "1";
try
{
dic[key] = key;
}
catch (KeyNotFoundException)
{
dic.Add(key, key);
}
}, "1 new tryCatch");
break;
default:
dic = new Dictionary<string, string>();
break;
}
Console.WriteLine("dic length {0}", dic.Count.ToString());
command = program.readCommand();
}
}
catch (OutOfMemoryException ex)
{
Console.WriteLine("create too many instance, please minus the instace count, press enter to quit");
Console.ReadLine();
}
}
private void run(int count, Action<int> func, string methodName)
{
var sDate = DateTime.Now;
var originUse = GC.GetTotalMemory(false);
for (var i = 0; i < count; i++)
{
func(i);
}
var currentUse = GC.GetTotalMemory(false);
var eDate = DateTime.Now;
double use = currentUse - originUse;
var dateDiff = eDate - sDate;
int index = 0;
var unit = strUnit[index];
var dateUnit = strDateUnit[index];
while (Math.Abs(use) > 1024)
{
use = use / 1024;
index++;
unit = strUnit[index];
}
index = 0;
double ms = dateDiff.TotalMilliseconds;
while (ms > 1000)
{
ms = ms / 1000;
index++;
dateUnit = strDateUnit[index];
}
Console.WriteLine("use {1} run{0} times use time {2}{3}", count, methodName, ms, dateUnit);
}
}
}










