34,836
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
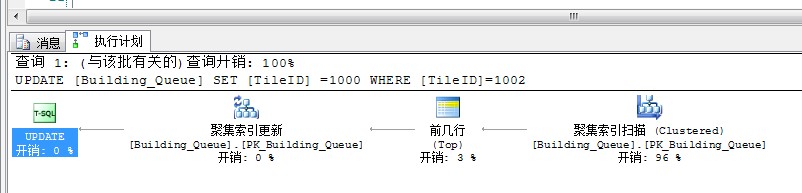





--强制用 PK_BUILDING_QUEUE 索引
select titleID
from building_queue with(index (PK_BUILDING_QUEUE))
where titleID = 1002
--强制用 test_index 索引
select titleID
from building_queue with(index (test_index))
where titleID = 1002
--强制用 PK_BUILDING_QUEUE 索引
select titleID
from building_queue with(index (PK_BUILDING_QUEUE))
where titleID = 1002
--强制用 test_index 索引
select titleID
from building_queue with(index (test_index))
where titleID = 1002
 么?
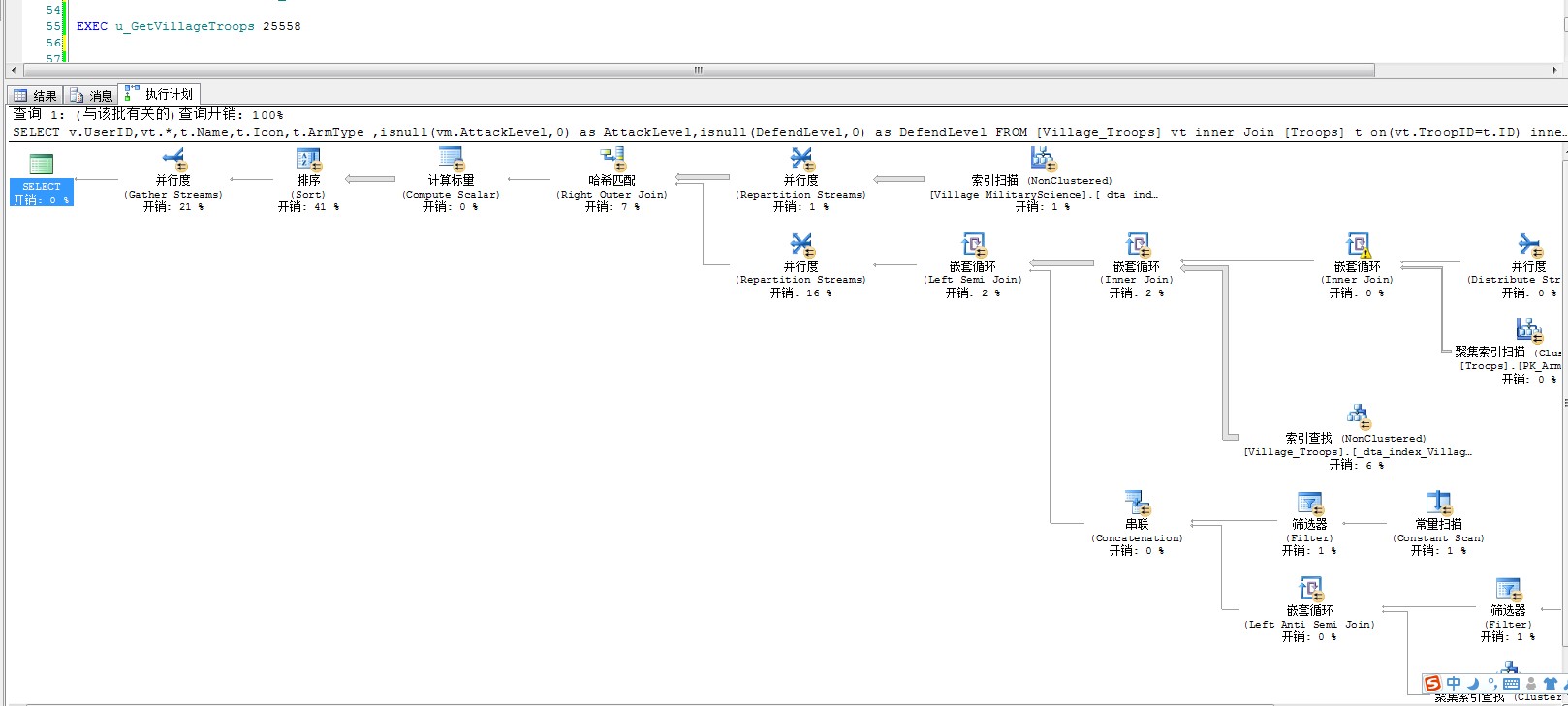
其实大部分把那个“绝对开销”加起来都是百分之百,如果在百分之百的情况下怎么比较呢?[/quote]
其实这个100%,只是对于某一个语句而言的,而且这个具体的开销值,也不一定是准确的
么?
其实大部分把那个“绝对开销”加起来都是百分之百,如果在百分之百的情况下怎么比较呢?[/quote]
其实这个100%,只是对于某一个语句而言的,而且这个具体的开销值,也不一定是准确的
--强制用 PK_BUILDING_QUEUE 索引
select titleID
from building_queue with(index (PK_BUILDING_QUEUE))
where titleID = 1002
--强制用 test_index 索引
select titleID
from building_queue with(index (test_index))
where titleID = 1002
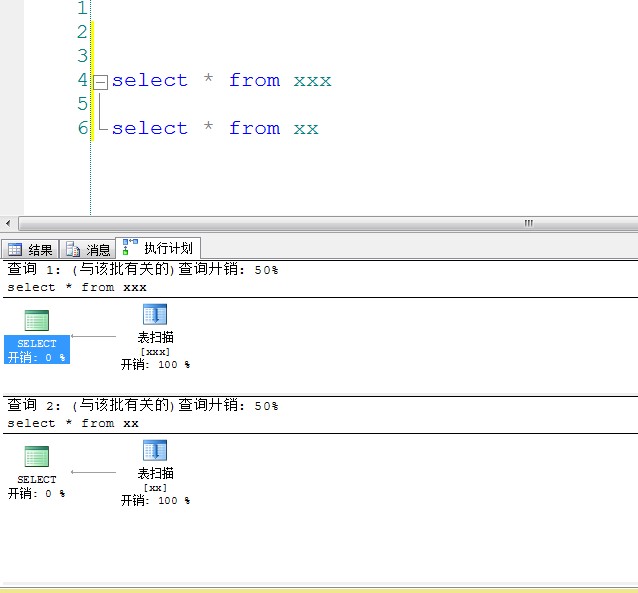
 不过好像大部分都是100%的
不过好像大部分都是100%的