


20,808
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享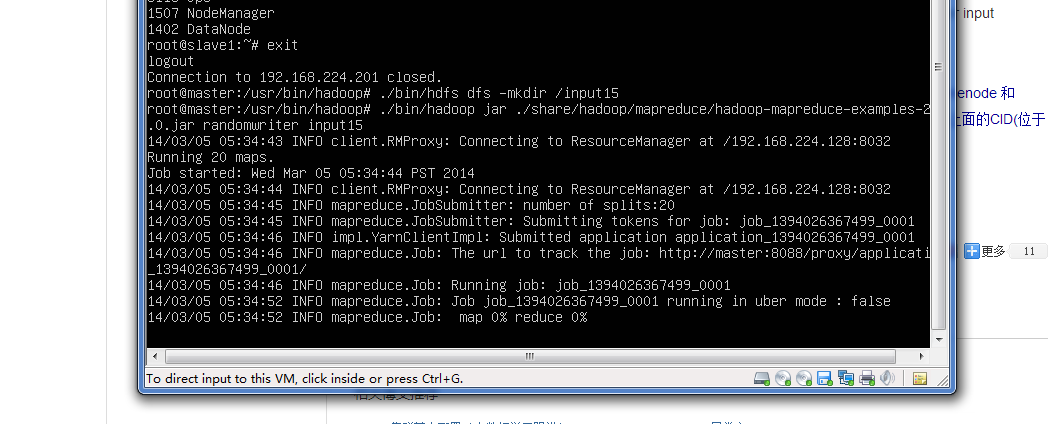
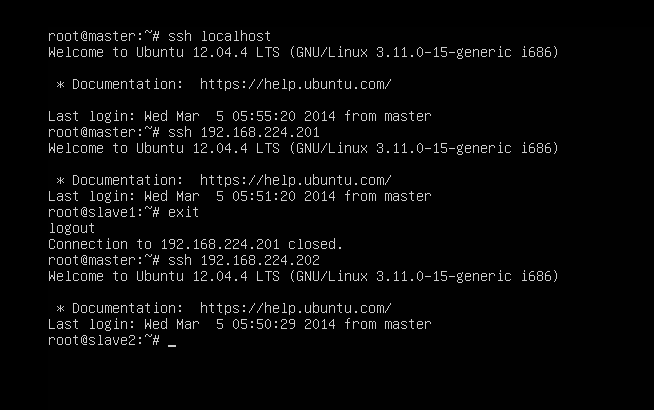
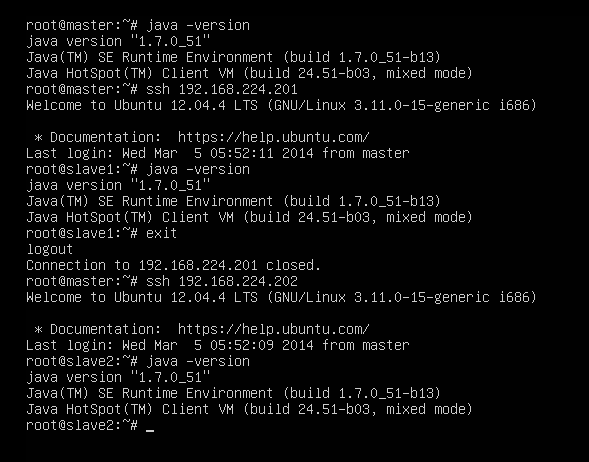
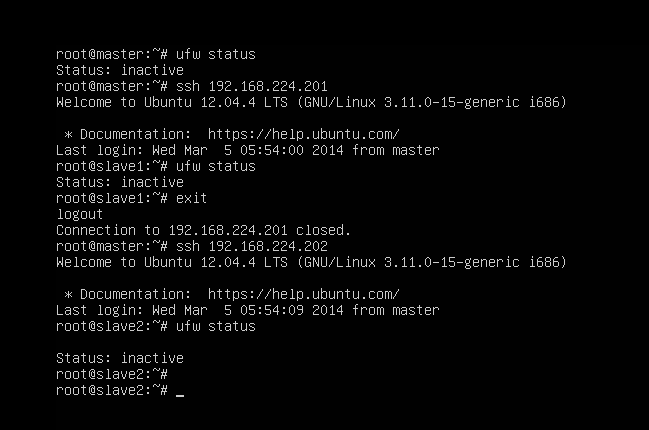
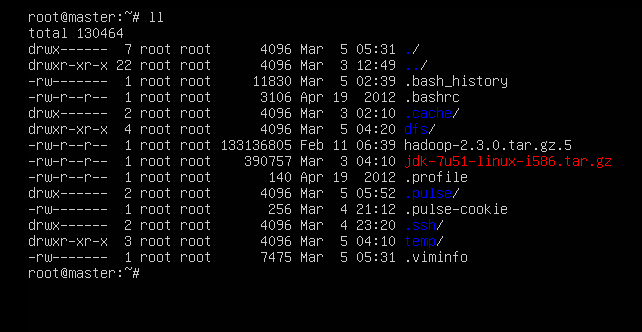


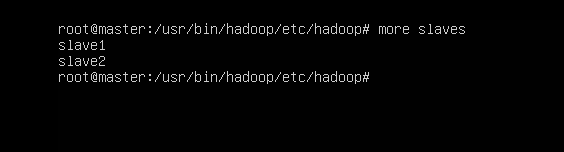
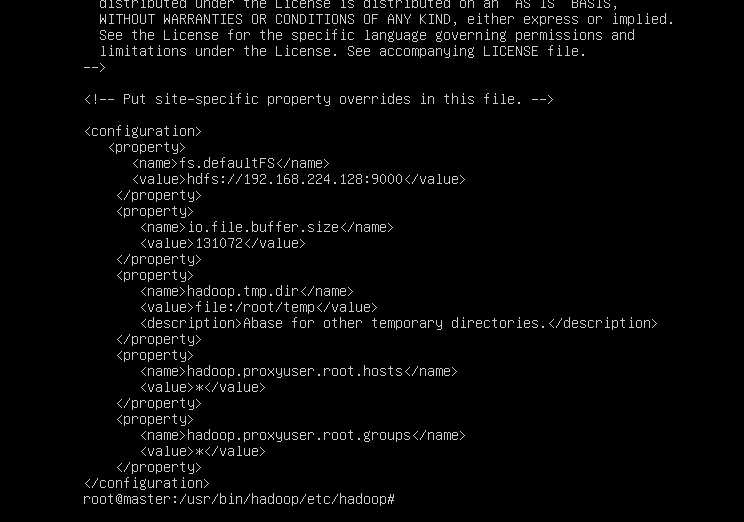
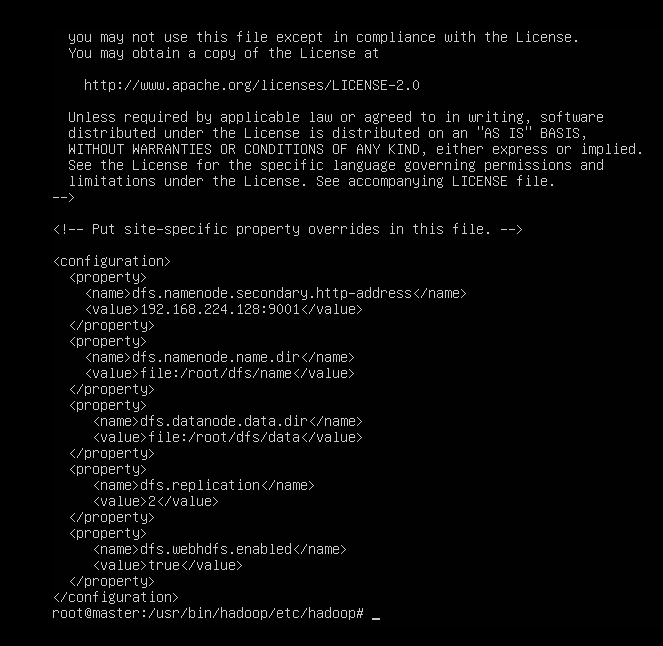
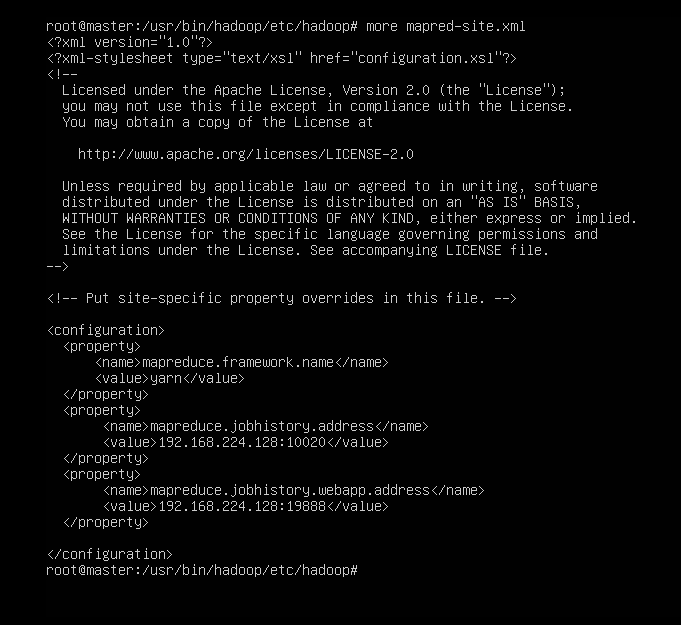
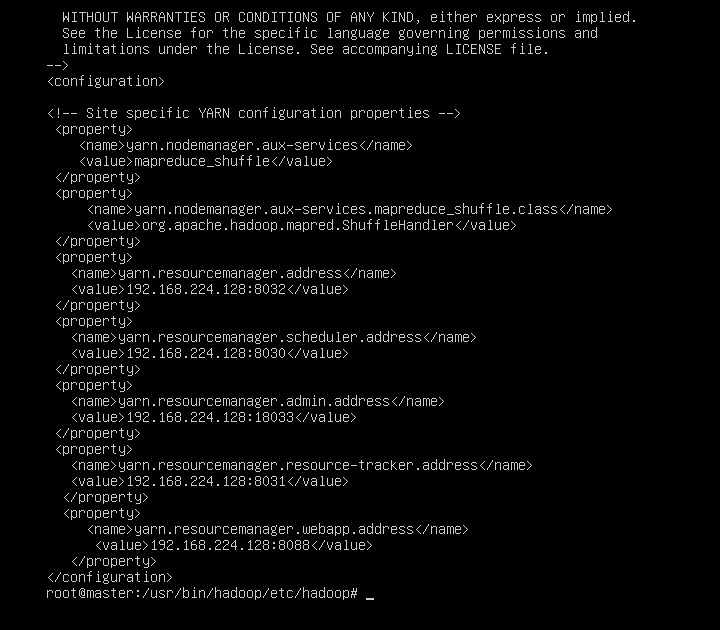

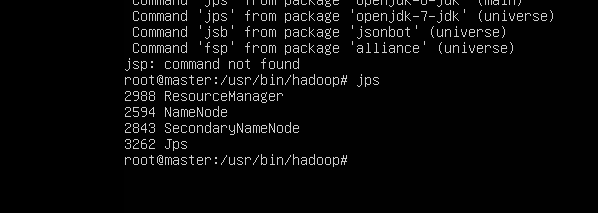
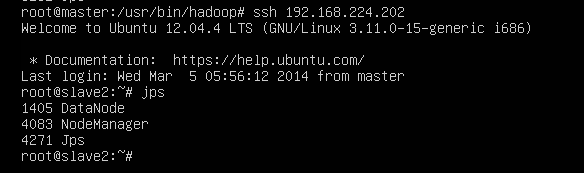
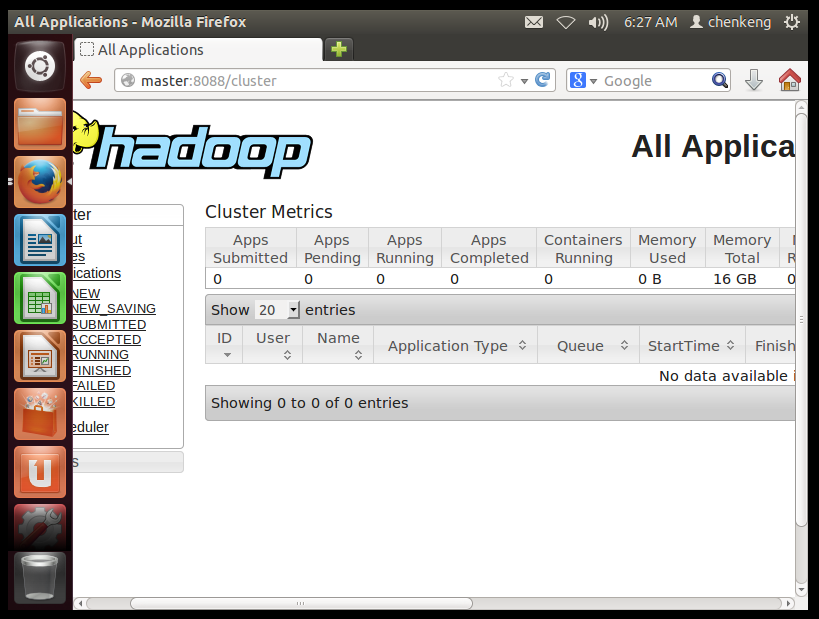

//第248行左右
//int numMapsPerHost = conf.getInt(MAPS_PER_HOST, 10); 把10修改成1
int numMapsPerHost = conf.getInt(MAPS_PER_HOST, 1);
//long numBytesToWritePerMap = conf.getLong(BYTES_PER_MAP,1*1024*1024*1024); 把1G改成 1M
long numBytesToWritePerMap = conf.getLong(BYTES_PER_MAP,1*1024*1024);



