

22,298
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
select top 20 a.列,b.列,c.列 from 表 A a left join B b on a.id=b.id left join C c on c.id=a.id;
select top 20 a.列 from A a;
select b.列 from B b where b.id=刚刚取出的A的id;
select c.列 from C c where c.id=刚刚取出的A的id;




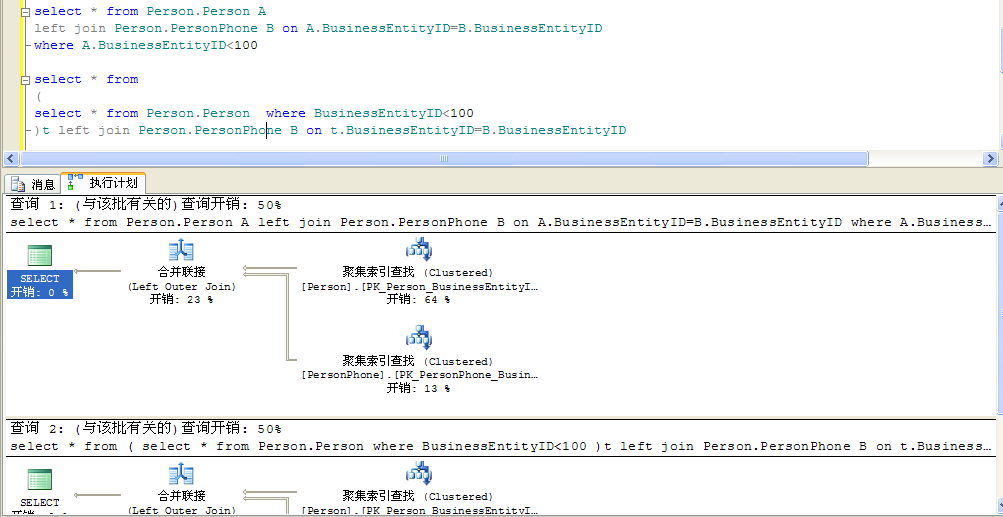
select * from Person.Person A
left join Person.PersonPhone B on A.BusinessEntityID=B.BusinessEntityID
where A.BusinessEntityID<100
select * from
(
select * from Person.Person where BusinessEntityID<100
)t left join Person.PersonPhone B on t.BusinessEntityID=B.BusinessEntityID



