我们很容易在网上找到这样一段话,这段话其实是来自于《深入理解linux内核》
Linux分页机制:
作为一个通用的操作系统,Linux需要兼容各种硬件体系,包括不同位数的CPU。对64位的CPU来说,两级页表仍然太少,一个页表会太大,这会占用太多宝贵的物理内存。Linux采用了通用的四级页表。实际采用几级页表则具体受硬件的限制。
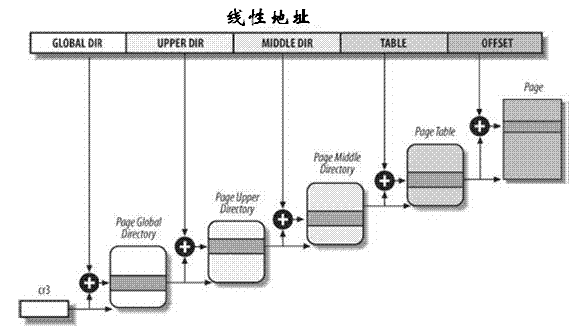
四种页表分别称为: 页全局目录、页上级目录、页中间目录、页表。对于32位x86系统,两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,彻底取消了页上级目 录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在32位系统和64位系统下都能使用。
/******************************************************************************************/
很明显这段话是很难理解的,最难理解的地方是:“Linux通过使“页上级目录”位和“页中间目录”位全为0”,我曾经对这段话产生两种理解:
我的第一个理解,大概是和这个帖子类似的:
http://www.linuxdiyf.com/viewarticle.php?id=183360

pud和pmd全为0,那该是什么样子啊?这样的话,一个虚拟地址岂不是有一部分必须为0,那么linux内核岂不是不能寻址到4G空间,为了解释我内心的矛盾,我善意的将pud和pmd理解为只有1位,并且这一位为0,于是就是这个样子。

这样的话,pud和pmd都占有两位,并且pud和pmd都会占一页,并且只用了这一页的第一项,巨大的浪费啊,我那时如此感叹。
我产生的第二种理解是,pud和pmd所指向的页表的内容全部为0,把上面的那张图略微p一下,来解释我是怎么理解的。
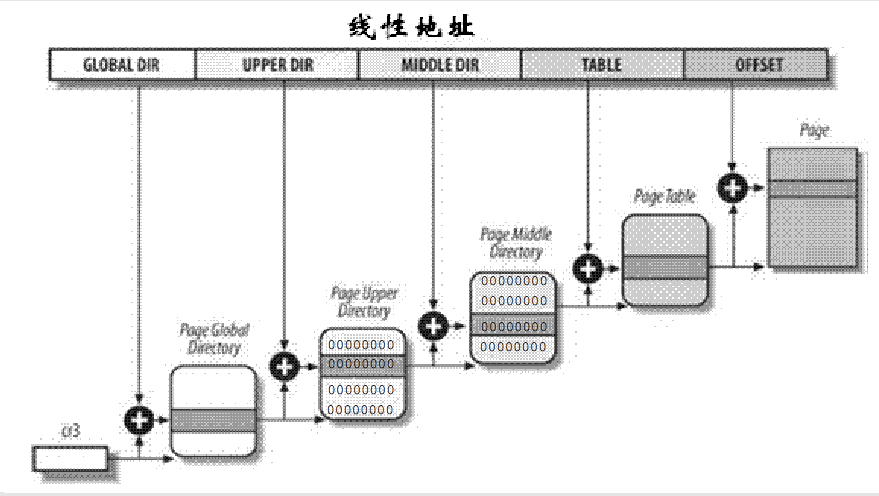
我以为那个页全部为0 ,那么所有的pmd其实寻找的都是物理地址为0的页了,而物理地址为0的页的每一项都是0。
但是等等,所有的虚拟地址都会经过物理地址0来寻找页,怎么可能,我很快知道了我这种想法的错误。
后来我诞生了第三种想法,和第一种想法类似,pud和pmd不在虚拟地址中占位,但是它们的值默认为0,pgd找到一页后,会取这一页(pud)的第一项继续找,找到一页(pmd)再用这一页的第一项找pte,虽然这种情况下,还是多占用了两个页,但是至少不占地址空间了,大概如下面这位仁兄这么想。
http://bbs.chinaunix.net/thread-1919185-1-1.html
/*************************************************************************************************************************************/
再也不能忍受这种情况了,我决定去内核源代码里去寻找。
相关的头文件为:include/asm-generic/ pgtable.h pgtable-nopmd.h pgtable-nopud.h
源代码在: arch/x86/mm/pgtable.c
当然必要时肯定要参照其他架构下的代码。
首先假设给我们一个虚拟地址,我们自己的想法是什么呢?
1. 根据address的golbale_dir+a3,得到pud_offset
2. pud_offset + upper_dir 得到pmd_offset
3. pmd_offset + middle_dir 得到pte_offset
4. pte_offset+ table 得到页表
5.page_table+offset得到这个地址的这个字节。
内核源代码也是这个流程,除去错误处理,代码如下:
pud = pud_offset(pgd, address);
pmd = pmd_offset(pud, address);
pte = pte_offset_kernel(pmd, address);
下面的没有了,我猜测是因为要做大页小页,或者其他情况的区分,不过我们可以自己猜测,继续下去是这个样子。
//pg = pg_offset(pte,address);
//pa = paddr(pg,address);
我们不管这两个我臆造的函数,看看前面三个函数都做了些什么。
在有全部四级分页的情况下,pud_offset pmd_offset pte_offset_kernel的代码如下:
static inline pud_t *pud_offset(pgd_t *pgd, unsigned long address)
{
return (pud_t *)pgd_page_vaddr(*pgd) + pud_index(address);
}
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{
return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
static inline pte_t *pte_offset_kernel(pmd_t *pmd, unsigned long address)
{
return (pte_t *)pmd_page_vaddr(*pmd) + pte_index(address);
}
可以说,这三个函数没有任何出乎我们意料,或者难以理解的部分,就是按照我们的想法走的。
然后在nopud和nopmd的时候,是什么样子的呢?
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd;
}
static inline pmd_t * pmd_offset(pud_t * pud, unsigned long address)
{
return (pmd_t *)pud;
}
这样一来,两级分页的时候,虚拟地址还是被分成了三个部分,pgd,pg,offset,根本没有pgd和pmd好吗!!!!
pud = pud_offset(pgd, address);
pmd = pmd_offset(pud, address);
pte = pte_offset_kernel(pmd, address);
上面这样的流程,直接变成了
pte = pte_offset_kernel(pgd,address);了。
那么现在在理解作者的那句话,全部置为0 ,就是说根本没有了。
有意思的是我在pgtable_nommu.h里看到pmd_offset的宏定义如下:
#define pmd_offset(a, b) ((void *)0)
那么我猜想,其实这是让虚拟地址直接对应物理地址了,说是转换了,其实没转换。
/---------------------------------------------------------------------------------------------------------------------------------/
其实,这么分析下来,我最大的疑问是:内核里为什么会有这样的代码?这些代码什么情况下被调用。
我的意思是说,难道一个虚拟地址到物理地址的转换难道不是硬件完成的吗?难到cpu遇到一个访问内存的指令,就说啊哈,要访问内存了,
怎么把虚拟地址变成物理地址呢?我们执行内核里上面的代码吧。
这可能吗?上面的代码被编译后也是指令,难道为了执行一条指令每次都要执行这些指令才能得到物理地址?(注意这些并不是缺页异常的处理程序。)
我知道肯定不是这样的,内核之所以会拥有这些代码,是因为或许有某种需求需要内核显式的管理内存,或者需要感知整个内存的使用情况时才需要调用这些函数,
说白了是为了内核的管理功能(尽管我不知道是什么),而不是一个程序的执行过程中的
虚拟到物理的转换要执行这些代码。
我的理解对吗?
/*****************************************************************************************************************************************/




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


