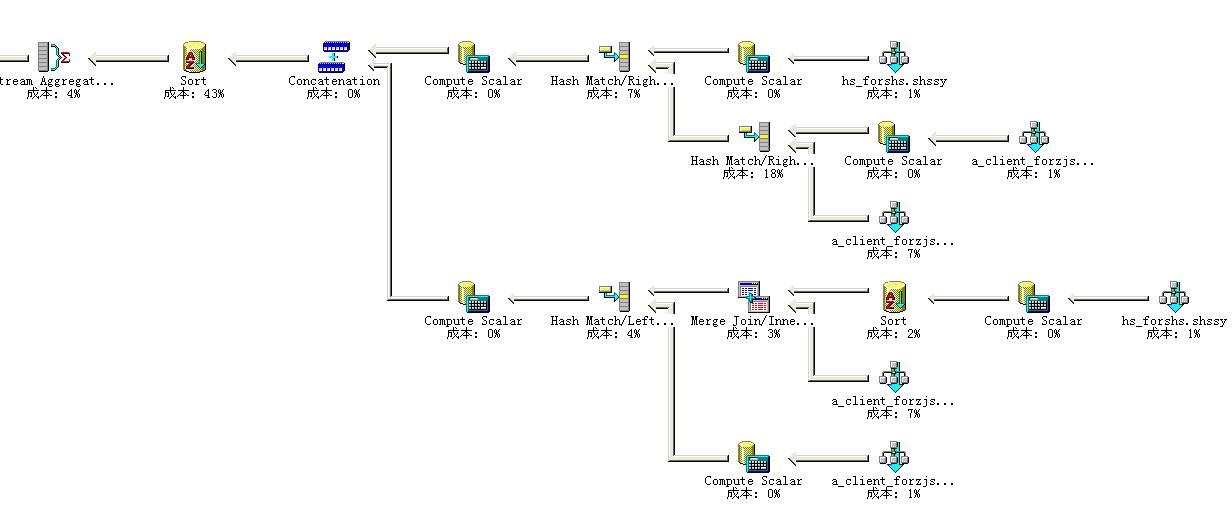
奇怪了,你的每个表只有一个聚集索引,怎么会出现index scan?有几个问题:
1、3个表有isty这列,但是第一个表是int,其他两个表是nvarchar(2),这个有问题,第一个问题是,通常这种命名的都是标识两个值,一个是是,一个是否,原则上不建议作为索引键。如果我的猜想是对的,把这列从索引定义中去掉。第二个问题,类型不同,如果你这个列不需要存储多语言,也就是说只需要存储数字、英文或者简体中文,就换varchar/char,不要用n开头的类型。另外这三个表的这列数据类型统一起来,也就是用同一个数据类型,避免数据类型隐式转换带来的性能问题。
2. 2000我记得索引定义和where条件的列顺序有严格的关系,所以我建议3个表的join的on条件里面,on xx=xx and xx=xx这种,要按照索引的定义顺序来写,也就是f_id=f_id and sampleid=sampleid and zzrq=zzrq这样写,顺序不能边。
3. sapleid、f_id这两个类型,还是类型问题,确保数据类型及其长度完全一样。并且尽可能避免使用n开头的类型。如果纯粹的数字,那么用int或者更小的数据类型即可。
你先做了这些看看效果再做下一步改进吧。另外记得把执行计划贴出来。至于你说的你本机1秒服务器6秒,那应该是数据量的不同导致的,你可以对比一下你本机的执行计划服务器的执行计划



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 。
。