测试方法:并发下判断数据是否存在,存在则插入
说明:
这种问题有很多种写法,其他的我都测试过了,
这里只讨论这两种方式,其他方式也能达到目的,但是不在本帖讨论范围
--建表
create table tb_1 (id int,a varchar(50),dt datetime default getdate())
go
--表tb_1上没有任何索引,采用updlock,serializable锁提示
begin tran
declare @i int
set @i=RAND()*10000
if not exists (select * from tb_1 with(updlock,serializable) where id=@i)
begin
insert tb_1 (id,a) values (@i,NEWID())
end
commit tran
serializable等同于 HOLDLOCK。保持共享锁直到事务完成,使共享锁更具有限制性;
而不是无论事务是否完成,都在不再需要所需表或数据页时立即释放共享锁。
1,
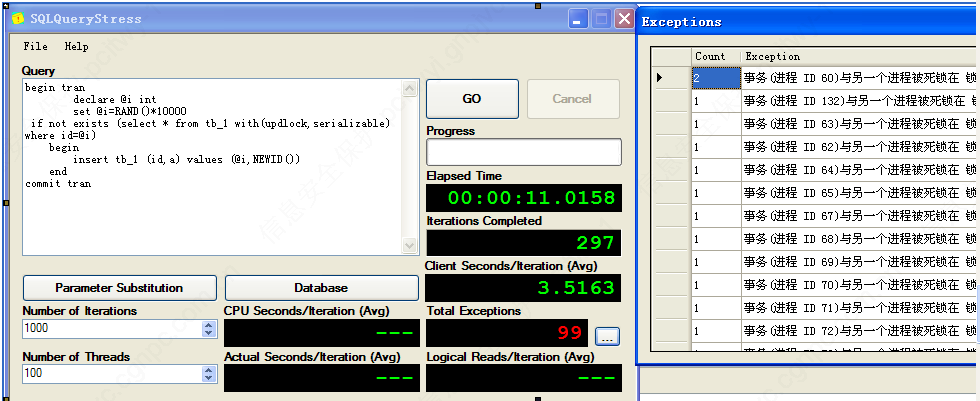
加updlock,serializable提示 为什么会出现死锁,
不知道可不可以这样理解死锁:
对于updlock,在查询执行时,先在记录上添加共享锁,找到记录后再添加排它锁,
这个过程中,可能存在多个会话添加共享锁,随后共享锁都不释放,再请求第二步的排它锁
然后就出现在同一个资源上,不同的会话占用了同一个资源上的共享锁,同时又请求排它锁,
所以会造成死锁的情况
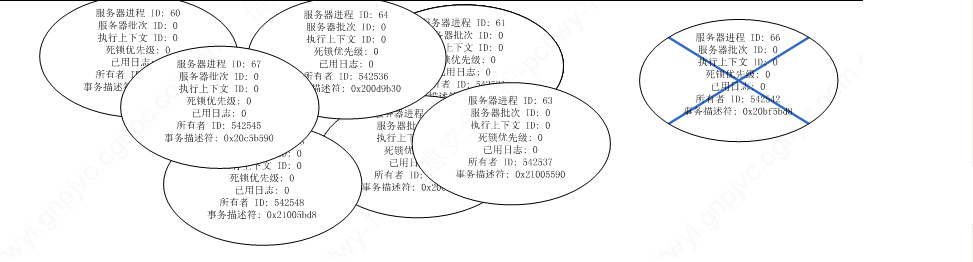
从死锁图中也可以看到,不是那种对不同资源的相互请求造成的,而是对同一个资源的请求造成的
 但是好似乎有点矛盾
但是好似乎有点矛盾
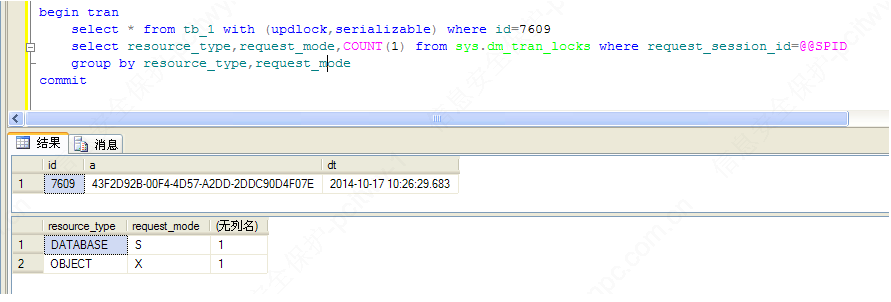
事实上,加updlock,serializable提示的时候,
直接在表上加了排它锁,表级的排它锁,那么所有回话之前就不会死锁了啊
比如我这个查询语句
2,updlock,仅仅只添加updlock提示的时候,没有出现死锁的问题,但是会出现重复数据
这个就比较容易理解了,
因为仅仅添加updlock提示的时候,可能存在多个会话去查询同一条数据的情况,
如果都没有查到,那么就要同时(即便不是“同时”插入,也要执行插入的sql,总是逻辑走到插入这里了)插入数据
所以就会出现重复数据的情况
当在表tb_1上添加索引的时候(create index index_1 on tb_1(id))
1,对于updlock,serializable就不会出现死锁了,这又是为什么呢?
2,对于updlock提示,依然会出现重复数据
这个跟上面没有索引时是一样的,会出现重复数据
感谢您的讨论!



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




 学习了
学习了







