

22,302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享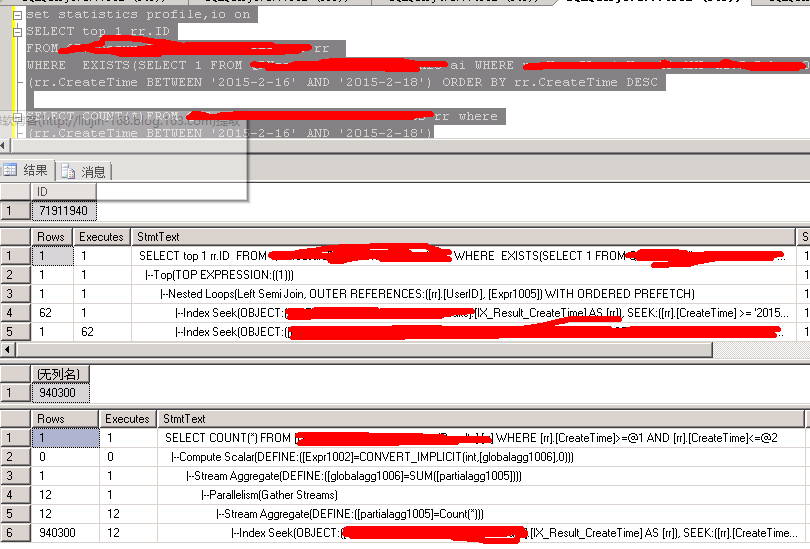
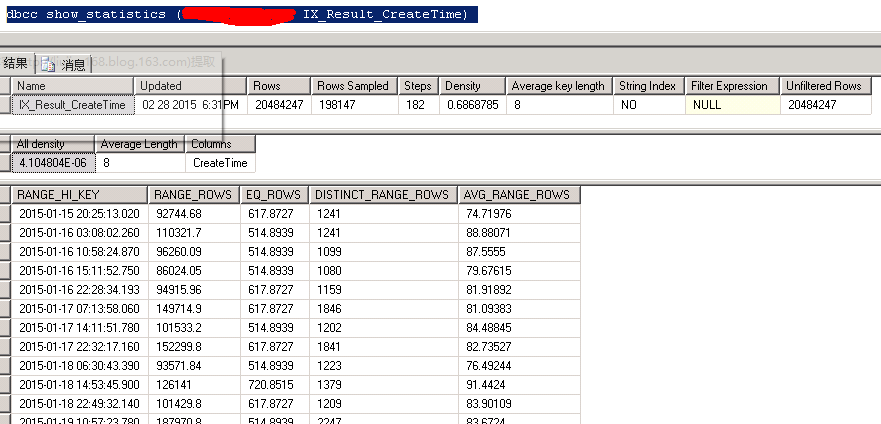
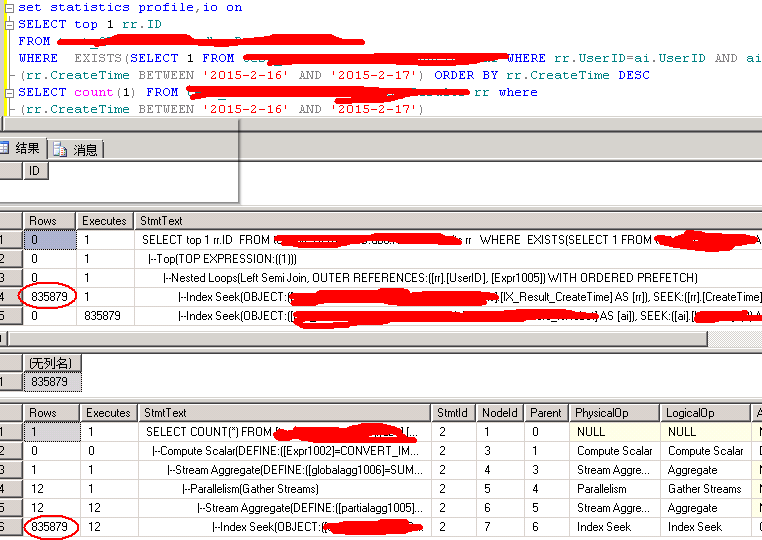
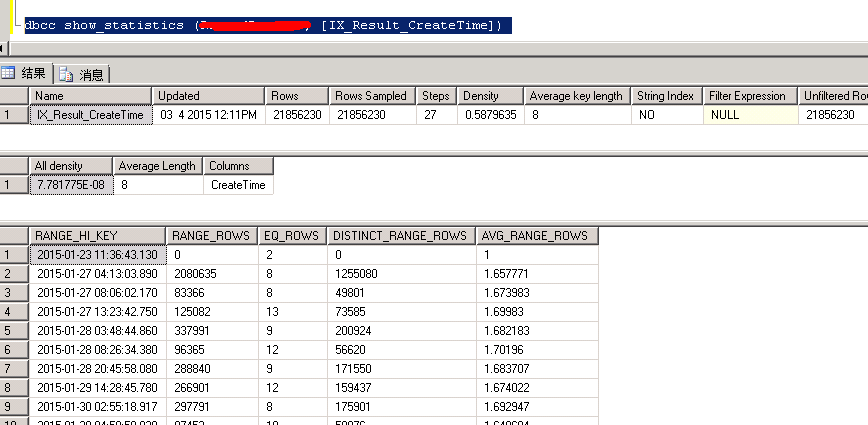


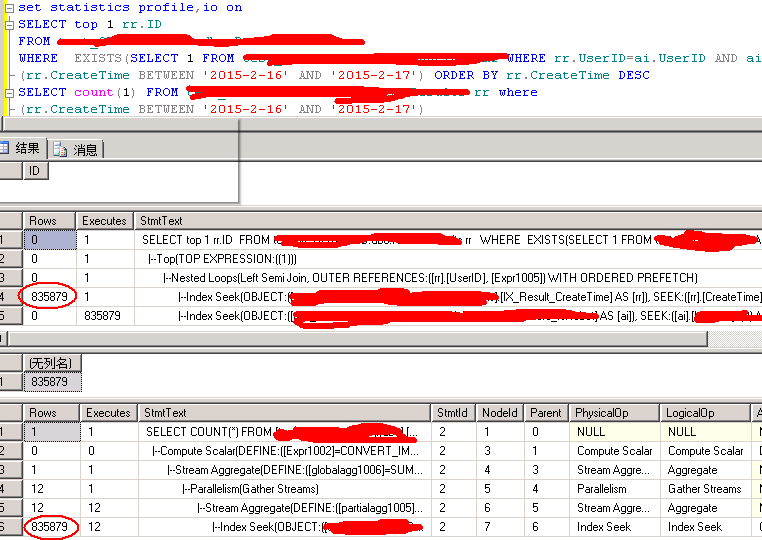

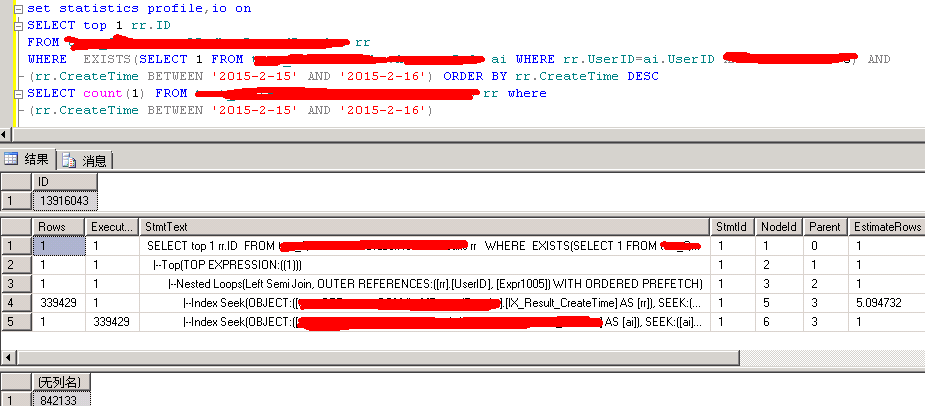


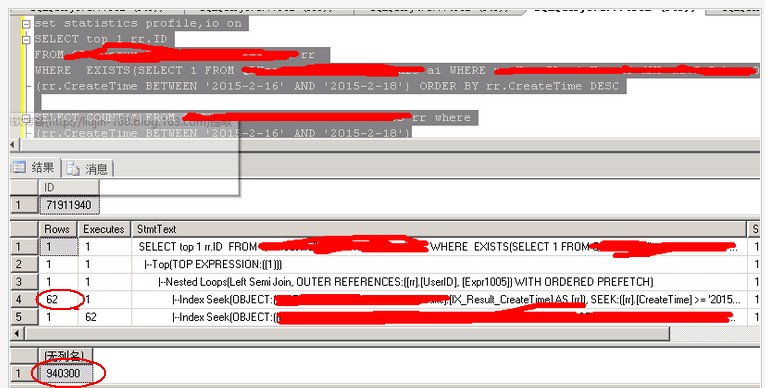

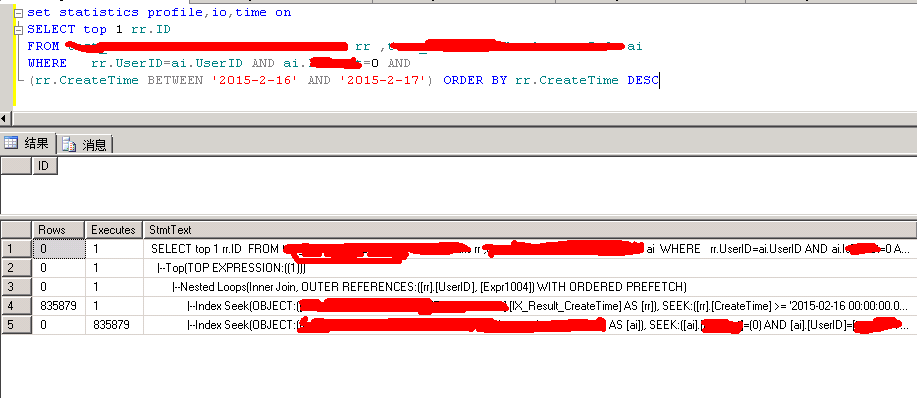


select top 1 rr.id
from rr,ai
where rr.createtime between '2015-2-15' and '2015-2-16' and rr.userid=ai.userid and ai.a='nice'
order by rr.createtime desc
select top 1 rr.id
from rr,ai
where rr.userid=ai.userid and rr.createtime between '2015-2-15' and '2015-2-16'
order by rr.createtime desc


