之前在网上看到了一个关于用Kettle的一套流程完成对整个数据库迁移的帖子http://ainidehsj.iteye.com/blog/1735434
但是按照里面的步骤在创建表结构的时候还是出现了问题。
Kettel日志报错如下:
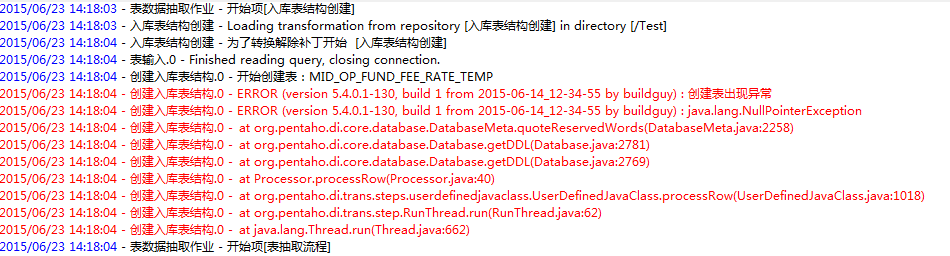
这是入库表结构的Java代码:
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException
{
// First, get a row from the default input hop
//
Object[] r = getRow();
org.pentaho.di.core.database.DatabaseMeta dbmeta = null;
java.util.List list = getTrans().getRepository().readDatabases();//3.x中获取资源库的所有数据库连接信息用getDatabases();
if(list != null && !list.isEmpty())
{
for(int i=0;i<list.size();i++)
{
dbmeta = (org.pentaho.di.core.database.DatabaseMeta)list.get(i);
System.out.println("+++++++++++++++");
System.out.println(dbmeta);
//下面是目标库的数据库连接,大家可根据需要修改
if("ORAC10G-TEST".equalsIgnoreCase(dbmeta.getName()))
{
break;
}
}
}
if(dbmeta!=null)
{
org.pentaho.di.core.database.Database db=new org.pentaho.di.core.database.Database(dbmeta);
try
{
db.connect();
String tablename = getVariable("TABLENAME");
logBasic("开始创建表:" + tablename);
if(tablename!=null && tablename.trim().length()>0)
{
String sql = db.getDDL(tablename, data.inputRowMeta);//${TABLENAME}
db.execStatement(sql.replace(";", ""));
logBasic(sql);
}
}
catch(Exception e)
{
logError("创建表出现异常",e);
}finally{
db.disconnect();
}
}
return false;
}
这个流程的job和trans在上面的链接里头。
求大神帮忙看下问题出在哪里???




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






