社区
community_281
帖子详情
如何使用Https访问Fusion Manager系统管理平台
lv_Angle
2015-06-30 07:16:33
如何使用Https访问Fusion Manager系统管理平台
...全文
379
1
打赏
收藏
如何使用Https访问Fusion Manager系统管理平台
如何使用Https访问Fusion Manager系统管理平台
复制链接
扫一扫
分享
转发到动态
举报
AI
作业
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Mind_Hacks
2015-07-01
打赏
举报
回复
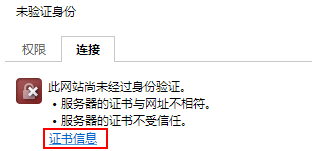
步骤 1 生成证书。
如图未验证身份
2 单击“证书信息”。
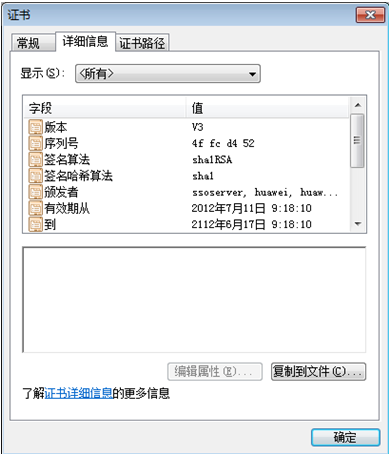
3 选择“详细信息”页签,单击“复制到文件(C)…”,如图所示。
4 单击“下一步”,格式选择“DER 编码二进制 X.509(.CER)(D)”。
5 单击“下一步”,生成证书。
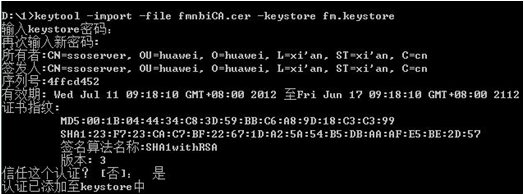
步骤 2 把证书导入至“fm.keystore”文件中。
1 打开DOS窗口,执行keytool -import -file fmnbiCA.cer -keystore fm.keystore命令,进入证书“fmnbiCA.cer”所在路径,如图所示。
导入证书
2 输入密码,密码详见步骤 3中的代码。
3 系统提示“信任这个认证?”,选择“是”。
步骤 3 将生成的“fm.keystore”文件放至工程的resources下。
关于设置https连接、获取keystore的密码和https的端口号,具体代码如下:
UserService userService = null;
ClientProviderBean bean = new ClientProviderBean();
bean.setServerIp("191.100.186.124");// 10.66.110.160
//端口号 http默认是8190 ,https默认是8195
bean.setServerPort("8195");
bean.setiDCAccessID("yyl");
bean.setHttpType("https");
//生成keystore的密码,明文填写即可
bean.setKeyStorePsw("changeit");
userService = ServiceFactory.getService(UserService.class, bean);
userService.userLogin("yyl", "Huawei@1234");
Fus
ion
Insight HD大数据产品维护.pdf
Fus
ion
Insight HD大数据产品维护.pdf
Fus
ion
Compute安装流程
华为
Fus
ion
Compute 8.0.0版本的安装流程,其中有安装CNA,VRM 操作步骤,服务器配置要求,本地PC安装
Fus
ion
Compute安装包过程等
(多媒体)
Fus
ion
Compute 8.0.0 软件安装 (X86) 01.zip
(多媒体)
Fus
ion
Compute 8.0.0 软件安装 (X86) 01.zip
基于
Fus
ion
Compute搭建小型企业私有云实训报告.docx
基于
Fus
ion
Compute搭建小型企业私有云实训报告-服务器虚拟化
Fus
ion
InsightHD华为大数据
平台
.pdf
Fus
ion
InsightHD华为⼤数据
平台
华为
Fus
ion
Insight HD是⼀个分布式数据处理系统,对外提供⼤容量的数据存储、分析查询和实时流式数据处 理分析能⼒。 安全 架构安全、认证安全、⽂件系统层加密 可靠 所有管理节点组件均实现HA(High Availability) 集群异地灾备 数据备份恢复 易⽤ 统⼀运维管理 易集成 易开发 系统架构
Manager
作为运维系统,为
Fus
ion
Insight HD提供⾼可靠、安全、容错、易⽤的集群管理能⼒,⽀持⼤规模集群的安装部署、监控、告警、⽤ 户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等。
Fus
ion
Insight
Manager
由OMS和OMA组成: OMS:操作维护系统的管理节点,OMS⼀般有两个,互为主备。 OMA:操作维护系统中的被管理节点,⼀般有多个。 Hue Hue提供了
Fus
ion
Insight HD应⽤的图形化⽤户界⾯。Hue⽀持展⽰多种组件,⽬前⽀持HDFS、Hive、YARN/MapReduce、 Oozie、Solr、ZooKeeper以及Spark。 Hue是建⽴在Django Python的Web框架上的Web应⽤程序,采⽤了MTV(模型M-模板T-视图V)的软件设计模式。(Django Python 是开放源代码的Web应⽤框架。)Hue由"Supervisor Process"和"WebServer"构成。"Supervisor Process"是Hue的核⼼ 进程,负责应⽤进程管理。"Supervisor Process"和"WebServer"通过"THRIFT/REST"接⼝与WebServer上的应⽤进⾏交 互,如图所⽰。 Loader 实现
Fus
ion
Insight HD与关系型数据库、⽂件系统之间交换数据和⽂件的数据加载⼯具;同时也可以将数据从关系型数据库或者⽂件 服务器导⼊到
Fus
ion
Insight HD的HDFS/HBase中,或者反过来从HDFS/HBase导出到关系型数据库或者⽂件服务器中。同时提供 REST API接⼝,供第三⽅调度
平台
调⽤。 Loader模型主要由Loader Client和Loader Server组成: - Flume ⼀个分布式、可靠和⾼可⽤的海量⽇志聚合系统,⽀持在系统中定制各类数据发送⽅,⽤于收集数据;同时,Flume提供对数据进⾏简 单处理,并写⼊各种数据接受⽅(可定制)的能⼒。 - FTP-Server FTP-Server是⼀个纯Java的、基于现有开放的FTP协议的FTP服务。FTP-Server⽀持FTP、FTPS协议,每个服务都⽀持PORT、 PASSIVE数据通信协议。⽤户或业务组件可通过通⽤的FTP客户端、传输协议提供对HDFS⽂件系统进⾏基本的操作,例如:⽂件上 传、⽂件下载、⽬录查看、⽬录创建、⽬录删除、⽂件权限修改等。 FTP-Server服务由多个FTP-Server进程或FTPS-Server进程组成。 FTP-Server服务可以部署在多个节点上,每个节点上只有⼀个FTP-Server实例,每个实例只有⼀个FTP Server进程。 Hive 建⽴在Hadoop基础上的开源的数据仓库,提供⼤数据
平台
批处理计算能⼒,能够对结构化/半结构化数据进⾏批量分析汇总完成数据 计算。提供类似SQL的Hive Query Language语⾔操作结构化数据存储服务和基本的数据分析服务。其基本原理是将HQL语⾔⾃动转 换成MapReduce任务,从⽽完成对Hadoop集群中存储的海量数据进⾏查询和分析。 Hive为单实例的服务进程,提供服务的原理是将HQL编译解析成相应的MapReduce或者HDFS任务,下图为Hive的结构概图。 Mapreduce 提供快速并⾏处理⼤量数据的能⼒,是⼀种分布式数据处理模式和执⾏环境。MapReduce是⼀种简化并⾏计算的编程模型,名字源于 该模型中的两项核⼼操作:Map和Reduce。Map将⼀个作业分解成为多个任务,Reduce将分解后多个任务处理的结果汇总起来,得 出最终的分析结果。 如图所⽰,MapReduce通过实现YARN的Client和Applicat
ion
Master接⼝集成到YARN中,利⽤YARN申请计算所需资源。 Storm 提供分布式、⾼性能、⾼可靠、容错的实时计算
平台
,可以对海量数据进⾏实时处理。CQL(Continuous Query Language)提供 的类SQL流处理语⾔,可以快速进⾏业务开发,缩短业务上线时间。 Spark 基于内存进⾏计算的分布式计算框架。在迭代计算的场景下,数据处理过程中的数据可以存储在内存中,提供了⽐MapReduce⾼10到 100倍的计算能⼒。Spa
community_281
672
社区成员
253,711
社区内容
发帖
与我相关
我的任务
community_281
提出问题
复制链接
扫一扫
分享
社区描述
提出问题
其他
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享