

579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享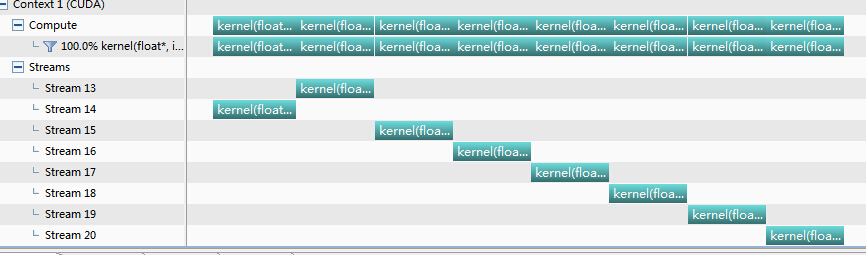




#include <pthread.h>
#include <stdio.h>
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
void *launch_kernel(void *dummy)
{
float *data;
cudaMalloc(&data, N * sizeof(float));
kernel<<<1, 64>>>(data, N);
cudaStreamSynchronize(0);
return NULL;
}
int main()
{
const int num_threads = 8;
pthread_t threads[num_threads];
for (int i = 0; i < num_threads; i++) {
if (pthread_create(&threads[i], NULL, launch_kernel, 0)) {
fprintf(stderr, "Error creating threadn");
return 1;
}
}
for (int i = 0; i < num_threads; i++) {
if(pthread_join(threads[i], NULL)) {
fprintf(stderr, "Error joining threadn");
return 2;
}
}
cudaDeviceReset();
return 0;
}

