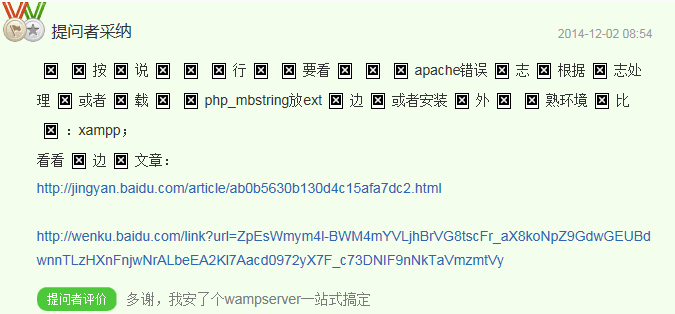
21,890
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
<?php
$url = "http://zhidao.baidu.com/link?url=pTwcJotQ02pjg-mjCnc-fkw8ONOY9x8q0ESrCFhdVJy47agZnDnCb-BCAtngRGDt9yi0TvleSS_w0aPj8Vsk0atVkVhNYdZADN0kv0BzNau";
echo fopen_url($url);
function fopen_url($url)
{
if (function_exists('curl_init'))
{
$curl_handle = curl_init();
curl_setopt($curl_handle, CURLOPT_URL, $url);
curl_setopt($curl_handle, CURLOPT_CONNECTTIMEOUT,2);
curl_setopt($curl_handle, CURLOPT_RETURNTRANSFER,1);
curl_setopt($curl_handle, CURLOPT_FAILONERROR,1);
curl_setopt($curl_handle, CURLOPT_TIMEOUT,2);
$file_content = curl_exec($curl_handle);
$encode = mb_detect_encoding($file_content, array("ASCII","UTF-8","GB2312","GBK","BIG5"));
if($encode != "UTF-8")
{
$file_content = mb_convert_encoding($file_content, "UTF-8", $encode);
//$file_content = iconv($encode,'utf-8//IGNORE',$file_content);
}
curl_close($curl_handle);
}
else
{
$file_content = '';
}
return $file_content;
}
?>