社区
软件水平考试
帖子详情
编译原理中的文法的产生式的括号有什么用?
TheBigBangWOW
2015-11-30 10:46:38
下图中的产生式P中
最后一个F→(E)I id,为什么E要加上括号?不加好像也可以的啊,前面的E→T的T也没加,T→F的F也没加,为什么这里的E要加上括号呢?
...全文
892
3
打赏
收藏
编译原理中的文法的产生式的括号有什么用?
下图中的产生式P中 最后一个F→(E)I id,为什么E要加上括号?不加好像也可以的啊,前面的E→T的T也没加,T→F的F也没加,为什么这里的E要加上括号呢?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
jackyBlithe
2015-12-07
打赏
举报
回复
应该是使的语句有结束符号,符合某一些条件
TheBigBangWOW
2015-12-02
打赏
举报
回复
支持一个,支持支持支持。
TheBigBangWOW
2015-12-02
打赏
举报
回复
支持一个,支持支持支持
编译原理
课后答案
很全的
编译原理
课后答案,可以在写作业时参考一下。
编译原理
期末试题(8套含答案+大题集)(53页一起)
《
编译原理
》期末试题(一) 一、是非题(请在
括号
内,正确的划√,错误的划×)(每个2分,共20分) 1.编译程序是对高级语言程序的解释执行。(× ) 2.一个有限状态自动机
中
,有且仅有一个唯一的终态。(×) 3.一个算符优先
文法
可能不存在算符优先函数与之对应。 (√ ) 4.语法分析时必须先消除
文法
中
的左递归 。 (×) 5.LR分析法在自左至右扫描输入串时就能发现错误,但不能准确地指出出错地点。 (√) 6.逆波兰表示法表示表达
式
时无须使用
括号
。 (√ )
编译原理
第二版 答案 保证是全的
第三章 L(G[S])={ abc } L(G[N])={ n位整数或空字符串 | n>0 } G[E]:E—>E+D | E-D | D D—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 L(G[Z])={ anbn | n>0 } (1) 考虑不包括“0”的情况 G[S]:S—>0S | ABC | 2 | 4| 6 | 8 A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 B—>AB | 0B | ε C—>0 | 2 | 4 | 6 | 8 考虑包括“0”的情况: G[S]:S—>AB | C B—>AB | C A—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 C—>0 | 2 | 4 | 6 | 8 (2)方法1: G[S]:S—> ABC | 2 | 4 | 6 | 8 A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 B—>AB | 0B | ε C—>0 | 2 | 4 | 6 | 8 方法2: G[S]:S—>AB | C B—> AB | 0B | C | 0 A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 C—>2 | 4 | 6 | 8 设为E,为T,为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i (4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i (6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I 是有二义性的,因为句子abc有两棵语法树(或称有两个最左推导或有两个最右推导) 最左推导1:S => Ac => abc 最左推导2:S => aB => abc (1) (2) 该
文法
描述了变量a和运算符+、*组成的逆波兰表达
式
10、(1) 该
文法
描述了各种成对圆
括号
的语法结构 (2) 是有二义性的,因为该
文法
的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()() 最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S => ()S(S)S => ()(S)S => ()()S => ()() 11、(1) 因为从
文法
的开始符E出发可推导出E+T*F,推导过程如下: E => E+T => E+T*F ,所以E+T*F是句型。 从子树和短语之间的关系可知: E+T*F是句型E+T*F相对于E的短语; T*F是句型E+T*F相对于T的短语,也是简单短语和句柄。 13、(1) 最左推导:S => ABS => aBS => aSBBS => aBBS => abBS => abbS => abbAa => abbaa (2) S—>ABS | Aa |ε A—>a B—>SBB | b (3) 首先为了区别句子abbaa
中
的a和b,把它写成a1b1b2a2a3 该句子的短语有:a1b1b2a2a3,b1b2,a2a3,a1,a2,b1,b2,ε 直接短语有:a1,a2,b1,b2,ε 句柄:a1 14、(1) G[S]:S—>AB A—>aAb |ε B—>aBb |ε (2) G[S]:S—>1S0 | A A—>0A1 |ε (3) G[S]:S—>0S0 | aSa | a 16、(1) G[A]:A—>aA |ε (2)G[A]:A—> aA | aB B—> bB | b (3)G[A]:A—>aA | B B—> bB | C C—>cC |ε 17、习题6、习题7和习题7
中
的
文法
所描述的语言都是由变量i、+、-、*、/、(和)组成算术表达
式
,因此它们之间是等价的。
编译原理
——
中
缀表达
式
转后缀表达
式
先写词法分析的源文件,用正则表达
式
表示出需要识别的字符,例如数字,乘法,加法和
括号
,如果识别到其他非法字符需要报错,用flex生成lex.yy.c文件。语法分析用LR方法进行语法分析,LR方法需要先根据
文法
构造自动机然后构造LR分析表,分析表用两个数组进行保存,在程序进行归约处理的时候执行给定的语义动作,将lex.yy.c作为头文件添加到语法分析程序LR.c
中
,最后进行调试运行测试。
编译原理
-算符优先
文法
分析器
java写的算符优先
文法
分析器 包括
括号
匹配,进出栈操作……
软件水平考试
2,948
社区成员
22,580
社区内容
发帖
与我相关
我的任务
软件水平考试
就计算机等级考试、软件初、中、高级不同级别资格考试相关话题交流经验,共享资源。
复制链接
扫一扫
分享
社区描述
就计算机等级考试、软件初、中、高级不同级别资格考试相关话题交流经验,共享资源。
c1认证
c4java
c4前端
技术论坛(原bbs)
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
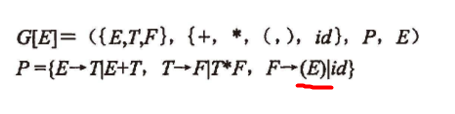


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


