


3,882
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享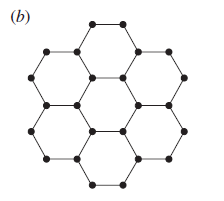
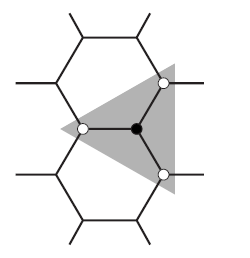




 [/quote]
老师 好厉害。。貌似就看懂这个[/quote]
感觉还需要补充一下:
例如(3,3)周围三个点的坐标是{(2,3),(3,2),(3,4)},{(3,2),(3,4)}这两个点比较容易得出,但是不看图的话如何判断出另一个点是(2,3)还是(4,3)?
根据图形规则,没行的点其实有的是向上有的是向下,如果加上向上或者向下标识的话就能比较容易的获取第三个点的位置。
例如(上,3,3),他周围的三个点必然是{(下,2,3),(下,3,2),(下,3,4)}[/quote]
如果用数组这种方法的话 对我帮助有限。举例:我需要通过id为25的节点,就能得到他的3个邻居,比如说player[24][0]是它的第一个邻居的id,player[24][1]是第二个邻居,player[24][2]为第三个邻居。如果用数组的话,操作方面并没有方便。觉着还是应该找规律
[/quote]
老师 好厉害。。貌似就看懂这个[/quote]
感觉还需要补充一下:
例如(3,3)周围三个点的坐标是{(2,3),(3,2),(3,4)},{(3,2),(3,4)}这两个点比较容易得出,但是不看图的话如何判断出另一个点是(2,3)还是(4,3)?
根据图形规则,没行的点其实有的是向上有的是向下,如果加上向上或者向下标识的话就能比较容易的获取第三个点的位置。
例如(上,3,3),他周围的三个点必然是{(下,2,3),(下,3,2),(下,3,4)}[/quote]
如果用数组这种方法的话 对我帮助有限。举例:我需要通过id为25的节点,就能得到他的3个邻居,比如说player[24][0]是它的第一个邻居的id,player[24][1]是第二个邻居,player[24][2]为第三个邻居。如果用数组的话,操作方面并没有方便。觉着还是应该找规律
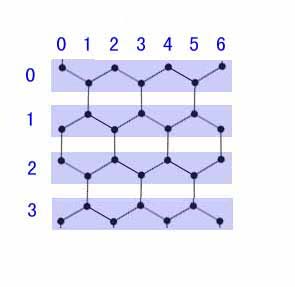

 [/quote]
老师 好厉害。。貌似就看懂这个[/quote]
感觉还需要补充一下:
例如(3,3)周围三个点的坐标是{(2,3),(3,2),(3,4)},{(3,2),(3,4)}这两个点比较容易得出,但是不看图的话如何判断出另一个点是(2,3)还是(4,3)?
根据图形规则,没行的点其实有的是向上有的是向下,如果加上向上或者向下标识的话就能比较容易的获取第三个点的位置。
例如(上,3,3),他周围的三个点必然是{(下,2,3),(下,3,2),(下,3,4)}[/quote]
回答问题可以得吧。
[/quote]
老师 好厉害。。貌似就看懂这个[/quote]
感觉还需要补充一下:
例如(3,3)周围三个点的坐标是{(2,3),(3,2),(3,4)},{(3,2),(3,4)}这两个点比较容易得出,但是不看图的话如何判断出另一个点是(2,3)还是(4,3)?
根据图形规则,没行的点其实有的是向上有的是向下,如果加上向上或者向下标识的话就能比较容易的获取第三个点的位置。
例如(上,3,3),他周围的三个点必然是{(下,2,3),(下,3,2),(下,3,4)}[/quote]
回答问题可以得吧。