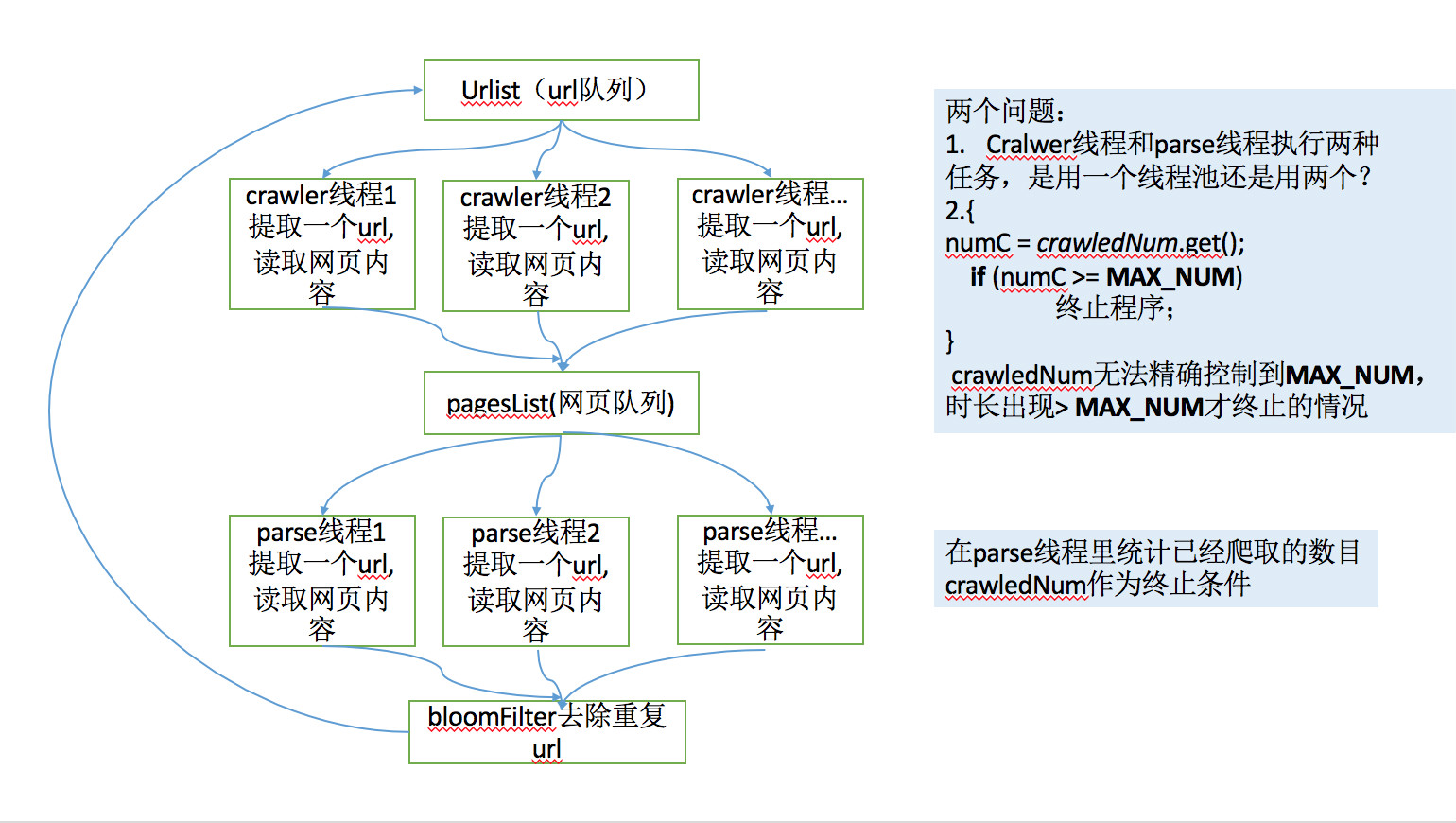
51,408
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
URL url = new URL(sUrl);
HttpURLConnection connection = (HttpURLConnection) url.openConnection(); //建立连接
package Modify;
import wxy.Utils.MyBloomFilter;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.concurrent.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author delia
* @create 2016-06-28 下午7:55
*/
public class MyCrawler2 {
private String sUrl = null;
private int MAX_NUM = 1;
public static MyBloomFilter mb = new MyBloomFilter();
public static BlockingQueue<String> urlist = new LinkedBlockingQueue<String>();
//public static AtomicInteger crawledNum = new AtomicInteger(0);
private static long crawlNum = 0;
public static BlockingQueue<PageInfo> pagesList = new LinkedBlockingQueue<PageInfo>();
private String filePath = null;
private FileWriter fileWriter = null;
private BufferedWriter bufferedWriter = null;
public long startTime = 0;
private long endTime = 0;
ExecutorService cachedTPool_GetPage;
ExecutorService cachedTPool_ParsePage;
private int offSet = 1;
public MyCrawler2(String sUrl, int maxNUm, String filePath) {
this.sUrl = sUrl;
this.MAX_NUM = maxNUm;
this.filePath = filePath;
}
public static void main(String[] args) {
int MAX_NUM = 100;
String filePath = "/Users/delia/Documents/workspace/Crawler/out/urlResult.txt";//存储结果
MyCrawler2 mc = new MyCrawler2("url-1",MAX_NUM,filePath);
mc.startTime = System.currentTimeMillis();
mc.crawl();
}
//爬取方法
public void crawl() {
try {
this.fileWriter = new FileWriter(filePath);
} catch (IOException e) {
e.printStackTrace();
}
this.bufferedWriter = new BufferedWriter(fileWriter);
cachedTPool_GetPage = Executors.newFixedThreadPool(100);
cachedTPool_ParsePage = Executors.newFixedThreadPool(10);
try {
System.out.println("爬虫开始!入口url为:"+sUrl);
urlist.put(sUrl);
cachedTPool_GetPage.submit(new TaskCrawlPages());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 抓取页面线程
class TaskCrawlPages implements Runnable {
@Override
public void run() {
//System.out.println(Thread.currentThread().getName() + "crawler网页");
crawlPage();//抓取网页
}
}
//分析页面线程
class TaskParsePages implements Runnable {
@Override
public void run() {
//System.out.println(Thread.currentThread().getName() + "parse网页");
parsePage();//分析网页,提取url
}
}
public void crawlPage() {
try {
String sUrl = urlist.take();
/*sUrl,下载网页代码,对响应码为200的url,保存其网页等信息,存入队列
* sUrl:当前爬取的url
* sHtml:网页内容
* len:网页长度
*/
TimeUnit.MILLISECONDS.sleep((int)(Math.random()*100));//模拟执行时间
String sHtml = "本应获取的网页内容;";
PageInfo pageInfo = new PageInfo(sUrl, sHtml.toString(), 0);
pagesList.put(pageInfo);
cachedTPool_ParsePage.submit(new TaskParsePages());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void parsePage() {
PageInfo pageInfo = null;
String sHtml = null;
String sCrawlUrl = null;
synchronized (TaskCrawlPages.class) {
if (crawlNum >= MAX_NUM) {
cachedTPool_GetPage.shutdownNow();
cachedTPool_ParsePage.shutdownNow();
endTime = System.currentTimeMillis();
System.out.println("======================已爬取 " + crawlNum + " 个,程序终止,执行时间:" + (endTime - startTime) / 1000.0 + "s");
try {
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}else{
try {
pageInfo = pagesList.take();
sCrawlUrl = pageInfo.getsUrl();
sHtml = pageInfo.getsHtml();
crawlNum ++;
System.out.print("当前分析第"+crawlNum+"个,网址为:"+sCrawlUrl+" ");
bufferedWriter.write(crawlNum+ " "+ sCrawlUrl + "\n");
} catch (Exception e) {
e.printStackTrace();
return;
}
}
}
try {
/*
*本应从sHtml中提取url,并用bloomFilter过滤器去除重复url并加入队列
*此处省略,模拟分析到了若干个url.
*/
TimeUnit.MILLISECONDS.sleep((int)(Math.random()*100));//模拟执行时间
int urlNum = (int)((Math.random()*10+1));
System.out.println("爬取到url个数:"+urlNum);
for (int i = 1; i <= urlNum; i++) {
String url = sCrawlUrl.replaceAll("^(\\D+)\\d+$", "$1") + (Integer.valueOf(sCrawlUrl.replaceAll("^\\D+", "")) + i);
//System.out.println("分析出网址:"+url);
urlist.put(url);
cachedTPool_GetPage.submit(new TaskCrawlPages());
}
}catch (Exception e){}
}
class PageInfo {
String sUrl;//当前爬取的url
String sHtml;//网页内容
int contentLen;//网页长度
public PageInfo(String sUrl, String sHtml,int len) {
this.sUrl = sUrl;
this.sHtml = sHtml;
this.contentLen = len;
}
public String getsUrl() {
return sUrl;
}
public void setsUrl(String sUrl) {
this.sUrl = sUrl;
}
public String getsHtml() {
return sHtml;
}
public void setsHtml(String sHtml) {
this.sHtml = sHtml;
}
public int getContentLen() {
return contentLen;
}
public void setContentLen(int contentLen) {
this.contentLen = contentLen;
}
}
public void judgeUrl(String sCrawlUrl,String sHtml){
String regex = "<a.*?/a>";//任意字符任意次,尽可能少的匹配
Pattern pt = Pattern.compile(regex);
Matcher mt = pt.matcher(sHtml);
while (mt.find()) {
Matcher title = Pattern.compile(">.*?</a>").matcher(mt.group());
Matcher myurl = Pattern.compile("href=[ ]*\".*?\"").matcher(mt.group());
while (myurl.find()) {
String sUrl = myurl.group().replaceAll("href=|>", "").trim();
int lenUrl = sUrl.length();
sUrl = sUrl.substring(1, lenUrl - 1).replaceAll("\\s*", "");
if (sUrl != null && sUrl.length() != 0) {
if (checkUrl(sCrawlUrl, sUrl) == null) {
//说明不是真正的url
}else{
//添加到url队列
}
}
}
}
}
public String checkUrl(String absolutePath, String sUrl) {
if (sUrl == null)
return absolutePath;
if (sUrl.contains("javascript:") || sUrl.contains("<%=") || sUrl.indexOf("'") == 0 || sUrl.length() <= ("https://".length() + 1))
return null;
if (!sUrl.contains("http://") && !sUrl.contains("https://")) {
if (sUrl.indexOf("/") == 0 || sUrl.indexOf("../") == 0 || sUrl.indexOf("./") == 0) {
URL absoluteUrl, parseUrl;
try {
absoluteUrl = new URL(absolutePath);
parseUrl = new URL(absoluteUrl, sUrl);
return parseUrl.toString();
} catch (MalformedURLException e) {
e.printStackTrace();
}
} else {
return "http://" + sUrl;
}
}
return sUrl;
}
}

import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test{
public static void main(String[] args){
String url = "<a target='_blank' src1='value1' href='http://www.baidu.com' src2='value2' src3=\"value3\"> 点击前往百度 </a>";
String regex = "<a(?:\\s+\\S+\\s*=\\s*(['\"]).*?\\1)*\\s+href\\s*=(['\"])(?<url>.*?)\\2(?:\\s+\\S+\\s*=\\s*(['\"]).*?\\4)*\\s*>(?<title>[^<]+)</a>";
Matcher matcher = Pattern.compile(regex).matcher(url);
if(matcher.find()){
System.out.printf("url:'%s'\n",matcher.group("url"));
System.out.printf("title:'%s'\n",matcher.group("title").trim());
}
}
}

while(true){
if(i++ >= 10){
break;
}
....other code...
}
executor.shutdown();
import java.util.concurrent.Callable;
import java.util.concurrent.Executors;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.ArrayList;
/*
*注:ParseTask.call()方法获取页面URL未实现..
*/
public class Test{
public static void main(String[] args){
int poolSize = 2;
String initURL = "url 1";//设置初始url
TaskManager manager = new TaskManager(poolSize,initURL);
manager.showResults();
}
}
class ParseTask implements Callable<ArrayList<String>>{
public ParseTask(String url){
this.url = url;
}
@Override
public ArrayList<String> call(){
ArrayList<String> urls = new ArrayList<>();
//process to get the in urls in page(url)
/*
*这里需要实现. To be continue ...
*这里放置获取页面url的代码,并添加到urls中
*
*/
//以下代码模拟每个页面获取到一个区别于results列表中元素的新url
urls.add(url.replaceAll("^(\\D+)\\d+$","$1") + (Integer.valueOf(url.replaceAll("^\\D+","")) + 1));
synchronized(ParseTask.class){
ArrayList<String> results = TaskManager.getResults();
for(String url : urls){
//将该页面获取到的url过滤并放入results中.
if(!results.contains(url)){
results.add(url);
}
}
//通知TaskManager继续生产ParseTask线程并放入执行器中
ParseTask.class.notifyAll();
}
return urls;
}
private String url;
}
class TaskManager{
public TaskManager(int poolSize,String initURL){
executor = Executors.newFixedThreadPool(poolSize);
task = new ParseTask(initURL);
try{
results = executor.submit(task).get();
}catch(InterruptedException|ExecutionException e){
e.printStackTrace();
System.exit(1);
}
}
private void start(){
ArrayList<ParseTask> tasks = null;
for(int crawledTime = 0 ; crawledTime < MAXCRAWLEDTIME ;){
//假设最终results.size() > MAXCRAWLEDTIME
//执行MAXCRAWLEDTIME次爬虫任务
if(crawledTime == results.size()){
//当解析到results最后一个元素的时候等待.
synchronized(ParseTask.class){
try{
ParseTask.class.wait();
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
}
}
tasks = new ArrayList<>();
for(; crawledTime < results.size() && crawledTime < MAXCRAWLEDTIME; crawledTime ++){
tasks.add(new ParseTask(results.get(crawledTime)));
}
try{
executor.invokeAll(tasks);
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
}
executor.shutdown();
}
public void showResults(){
//用于执行完毕后显示结果.
start();
try{
executor.awaitTermination(1,TimeUnit.DAYS);
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
for(String url : results){
System.out.println(url);
}
}
public static ArrayList<String> getResults(){
return results;
}
private ExecutorService executor;
private ParseTask task;
private static ArrayList<String> results = new ArrayList<>();
private static final int MAXCRAWLEDTIME = 1000;
}
import java.util.concurrent.Callable;
import java.util.concurrent.Executors;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.ArrayList;
/*
*注:ParseTask.call()方法获取页面URL未实现..
*/
public class Test{
public static void main(String[] args){
int poolSize = 2;
String initURL = "";//设置初始url
TaskManager manager = new TaskManager(poolSize,initURL);
manager.showResults();
}
}
class ParseTask implements Callable<ArrayList<String>>{
public ParseTask(String url){
this.url = url;
}
@Override
public ArrayList<String> call(){
ArrayList<String> urls = new ArrayList<>();
//process to get the in urls in page(url)
/*
*这里需要实现. To be continue ...
*这里放置获取页面url的代码,并添加到urls中
*
*/
synchronized(ParseTask.class){
ArrayList<String> results = TaskManager.getResults();
for(String url : urls){
//将该页面获取到的url过滤并放入results中.
if(!results.contains(url)){
results.add(url);
}
}
//通知TaskManager继续生产ParseTask线程并放入执行器中
ParseTask.class.notifyAll();
}
return urls;
}
private String url;
}
class TaskManager{
public TaskManager(int poolSize,String initURL){
executor = Executors.newFixedThreadPool(poolSize);
task = new ParseTask(initURL);
try{
results = executor.submit(task).get();
}catch(InterruptedException|ExecutionException e){
e.printStackTrace();
System.exit(1);
}
}
private void start(){
ArrayList<ParseTask> tasks = null;
for(int crawledTime = 0 ; crawledTime < MAXCRAWLEDTIME ;){
//假设最终results.size() > MAXCRAWLEDTIME
//执行MAXCRAWLEDTIME次爬虫任务
if(crawledTime == results.size()){
//当解析到results最后一个元素的时候等待.
synchronized(ParseTask.class){
try{
ParseTask.class.wait();
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
}
}
tasks = new ArrayList<>();
for(; crawledTime < results.size() && crawledTime < MAXCRAWLEDTIME; crawledTime ++){
tasks.add(new ParseTask(results.get(crawledTime)));
}
try{
executor.invokeAll(tasks);
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
}
executor.shutdown();
}
public void showResults(){
//用于执行完毕后显示结果.
start();
try{
executor.awaitTermination(1,TimeUnit.DAYS);
}catch(InterruptedException e){
e.printStackTrace();
System.exit(1);
}
for(String url : results){
System.out.println(url);
}
}
public static ArrayList<String> getResults(){
return results;
}
private ExecutorService executor;
private ParseTask task;
private static ArrayList<String> results;
private static final int MAXCRAWLEDTIME = 1000;
}