新手上路,最近在学习python,用scrapy框架来爬取数据。
传统静态页面相对容易爬取,于是我尝试着爬取js动态加载的页面。
http://www.itslaw.com/detail?judgementId=3d47dac4-79ed-40e7-99df-a688ec879f5e&area=1&index=1&sortType=2&count=1208&conditions=publishType%2B79%2B2%2B%E5%85%AC%E6%8A%A5%E6%A1%88%E4%BE%8B 该页面是我尝试爬取的页面。下面将我的代码以及爬取的结果贴图展示,请各位大神帮我看看怎么回事:
1.文件夹结构
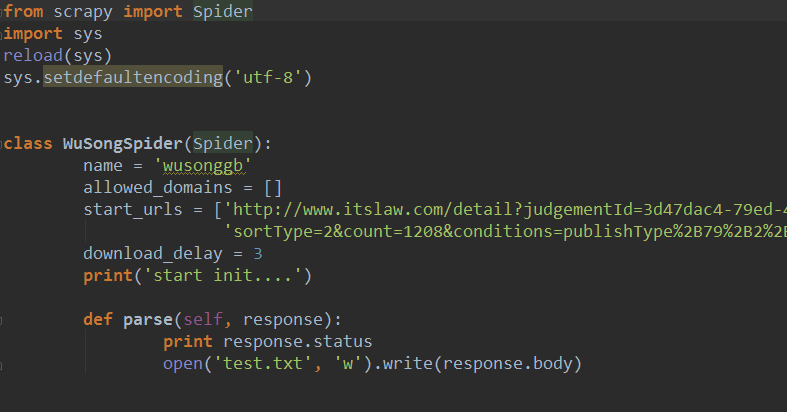
2.WuSongSpider.py(非常简单,就定义了需要爬取的url以及将返回的response.body写入一个test.txt的文本中)
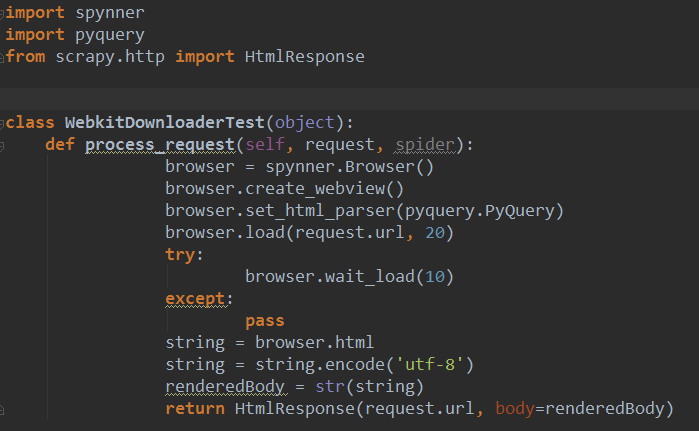
3.woenloadwebkit.py,延迟加载的中间件
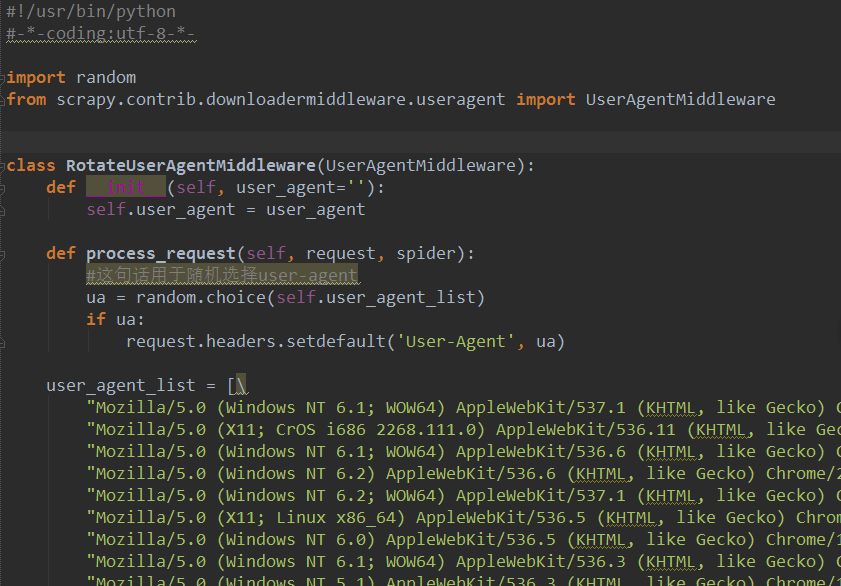
4.rotateuseragent.py,用于在useragent池中随机选择一个
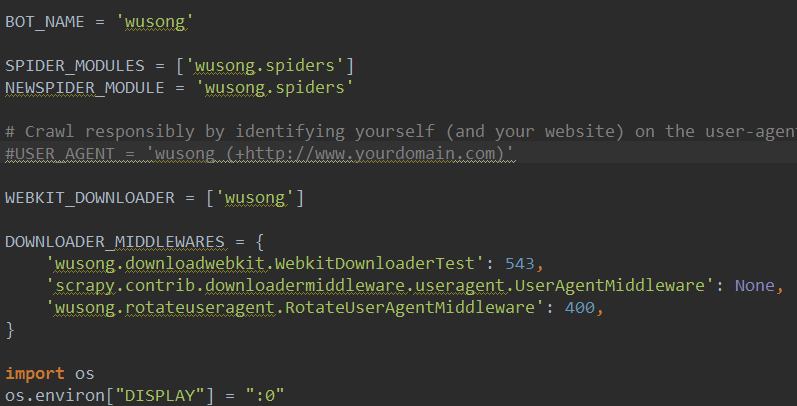
5.settings.py
6.test.txt,返回的结果(即response.body)
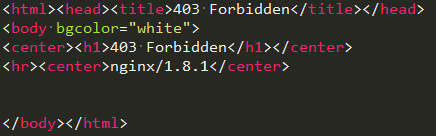
猜测应该是服务器端采取了什么反爬机制,请各位大神出手相助,谢谢!


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


