37,721
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享import pandas as pd
#读取数据,更换列表名
data = pd.read_table( 'u.data' )
datafeilds = ['user id', 'item id', 'rating', 'timestamp']
data.columns = datafeilds
#将文件中需要的数据分别存入两个列表
user_id = []
gender = []
userfile = open('u.user')
contents = userfile.readlines()
userfile.close()
for i in range(0,len(contents)):
line = contents[i].split('|')
user_id.append( line[0] )
gender.append( line[2] )
#存入数据,为dataframe类型
dictuser = {'user id':user_id, 'gender':gender}
user = pd.DataFrame(dictuser)
rating = pd.merge( data, user, on = 'user id')
print rating

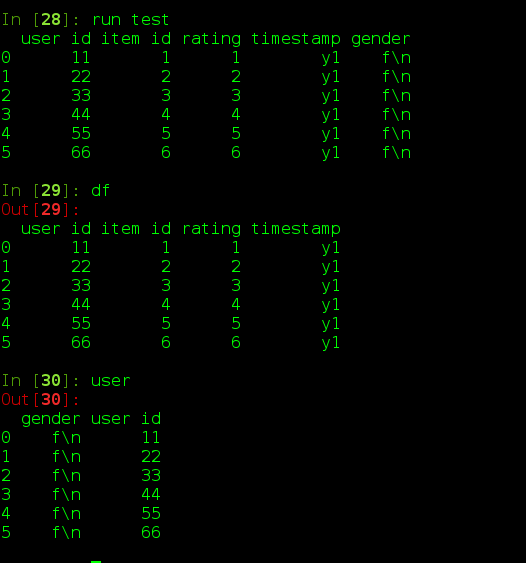
df = pd.DataFrame(data,columns=datafeilds)data = np.loadtxt('u.data',delimiter = " ", dtype=str)
datafeilds = ['user id', 'item id', 'rating', 'timestamp']
sline = []
for line in data:
sline.append( line.split('\t') )
array = np.array(sline)
df = pd.DataFrame(array,columns=datafeilds)
print data.columns[0], user.columns[1]
print type(data.columns[0]), type(user.columns[1])#!/usr/bin/python
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
#读取数据,更换列表名
data = np.loadtxt('u.data',delimiter = " ", dtype=str)
#data = pd.read_table( 'u.data' )
datafeilds = ['user id', 'item id', 'rating', 'timestamp']
#data.columns = datafeilds
df = pd.DataFrame(data,columns=datafeilds)
#将文件中需要的数据分别存入两个列表
user_id = []
gender = []
userfile = open('u.user')
contents = userfile.readlines()
userfile.close()
for i in range(0,len(contents)):
line = contents[i].split('|')
user_id.append( line[0] )
gender.append( line[2] )
#存入数据,为dataframe类型
dictuser = {'user id':user_id, 'gender':gender}
user = pd.DataFrame(dictuser)
rating = pd.merge( df, user, on = 'user id')
print rating11 1 1 y1
22 2 2 y1
33 3 3 y1
44 4 4 y1
55 5 5 y1
66 6 6 y111|m|f
22|f|f
33|m|f
44|m|f
55|f|f
66|f|f