

27,580
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享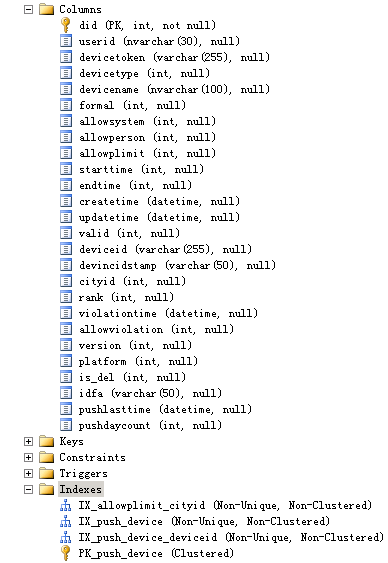



DELETE t
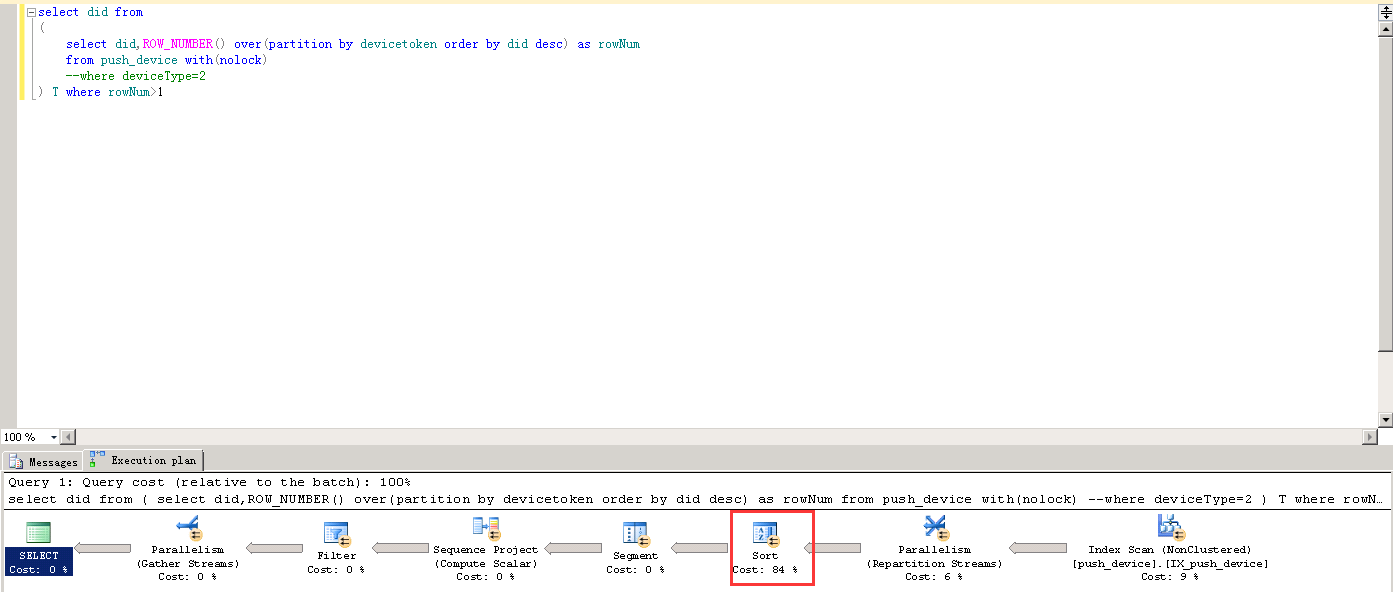
FROM ( SELECT * ,
ROW_NUMBER() OVER ( PARTITION BY DeviceToken ORDER BY did DESC ) AS RN
FROM push_device
) AS t
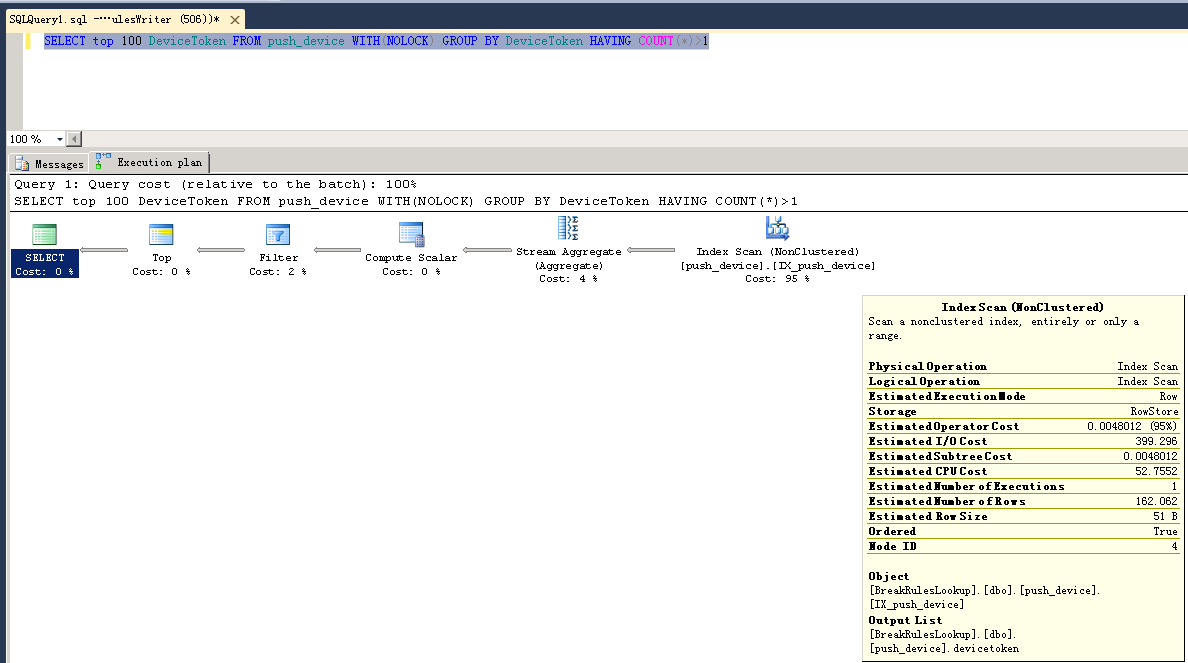
WHERE t.RN > 1;SELECT DeviceToken FROM push_device WITH(NOLOCK) GROUP BY DeviceToken HAVING COUNT(*)>1SELECT did FROM push_device WITH(NOLOCK) GROUP BY did HAVING COUNT(*)>1
