

51,402
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
package com.zql.lucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import com.chenlb.mmseg4j.analysis.MMSegAnalyzer;
/**
* lucene创建索引
* @author yh
* @version 3.5.0
* @date 2016-12-21
*/
public class IndexCreate {
/**索引存储位置*/
private static final String PATH = "E://workspaces/lucene/index35";
/**需要索引的文档的位置*/
private static final String TXT_PATH = "E://workspaces/lucene/txt";
private static String dicURL = IndexCreate.class.getClassLoader().getResource("data").getPath();
/**
* 创建索引
*/
public void createIndex(){
try {
//存储路径
Directory directory = FSDirectory.open(new File(PATH));
//Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_35);
Analyzer analyzer = new MMSegAnalyzer(dicURL);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_35, analyzer);
IndexWriter writer = new IndexWriter(directory, config);
File files = new File(TXT_PATH);
//把文件存入索引
for(File file:files.listFiles()){
Document document = new Document();
//文档中添加域
document.add(new Field("filename", file.getName(),Store.YES,Index.ANALYZED_NO_NORMS));
document.add(new Field("path", file.getAbsolutePath(), Store.YES, Index.ANALYZED_NO_NORMS));
document.add(new Field("content", new FileReader(file)));
//添加文档到索引中
writer.addDocument(document);
}
/***保存中文的文本索引能够检索到中文**/
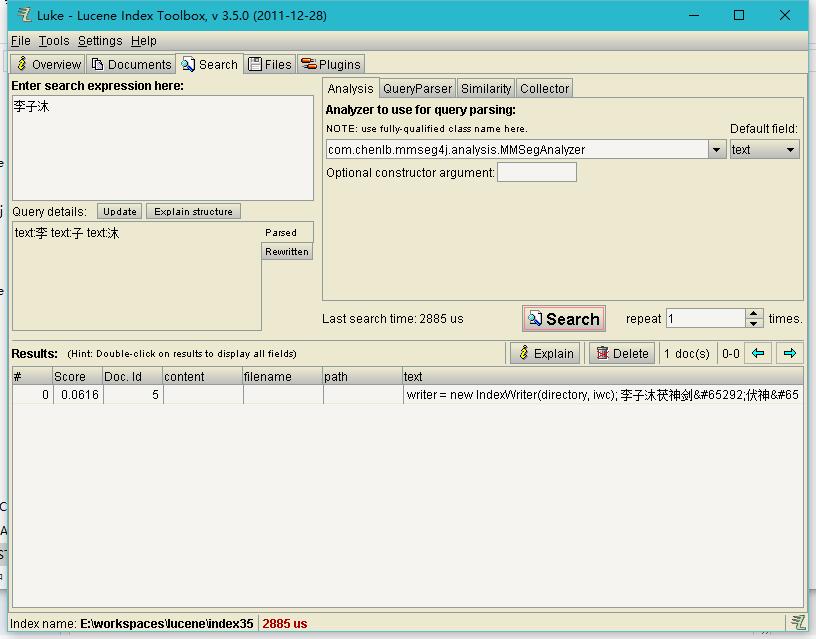
String txt = "writer = new IndexWriter(directory, iwc); 李子沐茯神剑,伏神,伏生、辛紫月留梦剑,留梦";
Document doc = new Document();
doc.add(new Field("text", txt, Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
writer.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 查询索引
* @param field 域
* @param value 域对应的值
*/
public void searchIndex(String field,String value){
try {
Directory directory = FSDirectory.open(new File(PATH));
IndexReader reader = IndexReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new MMSegAnalyzer(dicURL);
QueryParser parser = new QueryParser(Version.LUCENE_35, field, analyzer);
Query query = parser.parse(value);
System.out.println(query.toString());
TopDocs topDocs = searcher.search(query, 10);
System.out.println("匹配了【"+topDocs.totalHits+"】条数据");
ScoreDoc[] docs = topDocs.scoreDocs;
for(ScoreDoc doc:docs){
System.out.println("文档ID【"+doc.doc+"】:路径【"+searcher.doc(doc.doc).get("path")+"】");
}
searcher.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
public void deleteIndex(){
try {
Directory directory = FSDirectory.open(new File(PATH));
Analyzer analyzer = new MMSegAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_35, analyzer);
IndexWriter writer = new IndexWriter(directory, conf);
writer.deleteAll();
directory.close();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package com.zql.test;
import org.junit.Test;
import com.zql.lucene.IndexCreate;
/**
* 测试索引的类
* @author yh
* @date 2016-12-21
*/
public class TestIndexCreate {
@Test
public void testIndexCreate(){
IndexCreate index = new IndexCreate();
index.createIndex();
}
@Test
public void testSeacher(){
IndexCreate index = new IndexCreate();
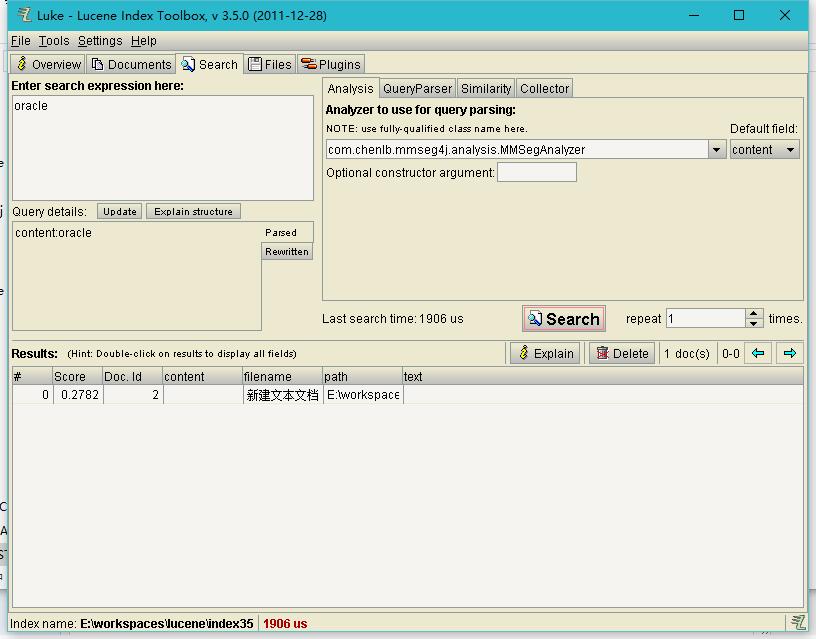
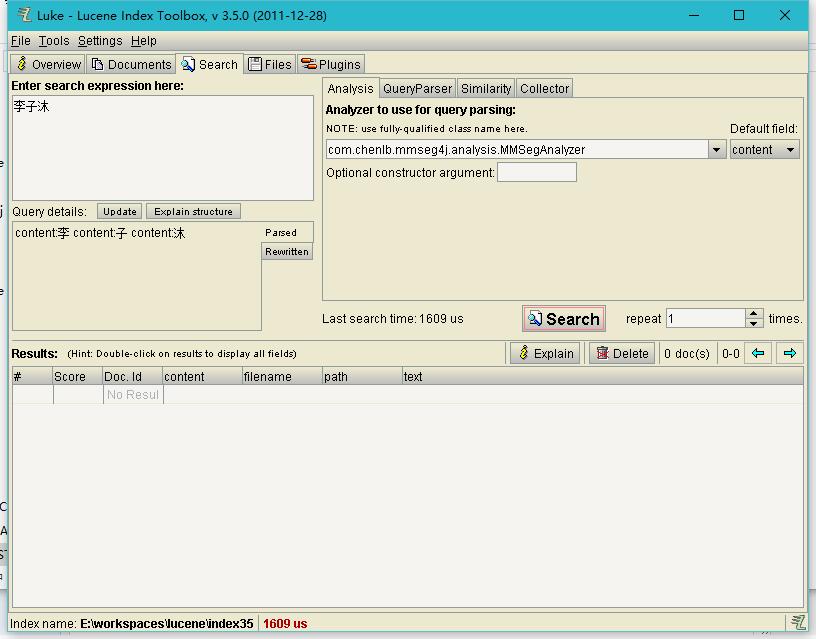
index.searchIndex("content","李子沐");
}

//document.add(new Field("content", FileUtil.readFilebyLine(file),Store.YES,Index.ANALYZED));
document.add(new Field("content", new InputStreamReader(new FileInputStream(file),"GBK")));


