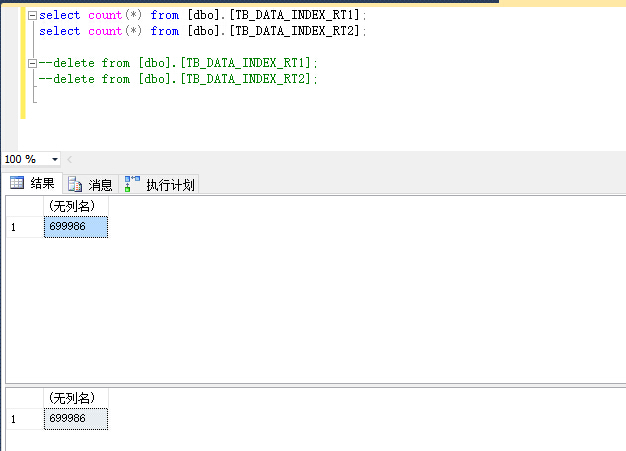
6,129
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享CREATE TABLE [dbo].[TB_DATA_INDEX_RT1]
(
[DATA_ID] [bigint] IDENTITY(1,1) NOT NULL,
[INDEX_CODE] [int] NOT NULL,
[INDEX_VALUE] [float] NOT NULL,
[RTIME] [datetime2](3) NOT NULL,
[VALUE_STATUS] [tinyint] NOT NULL,
PRIMARY KEY NONCLUSTERED HASH
(
[DATA_ID]
)WITH ( BUCKET_COUNT = 33554432)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO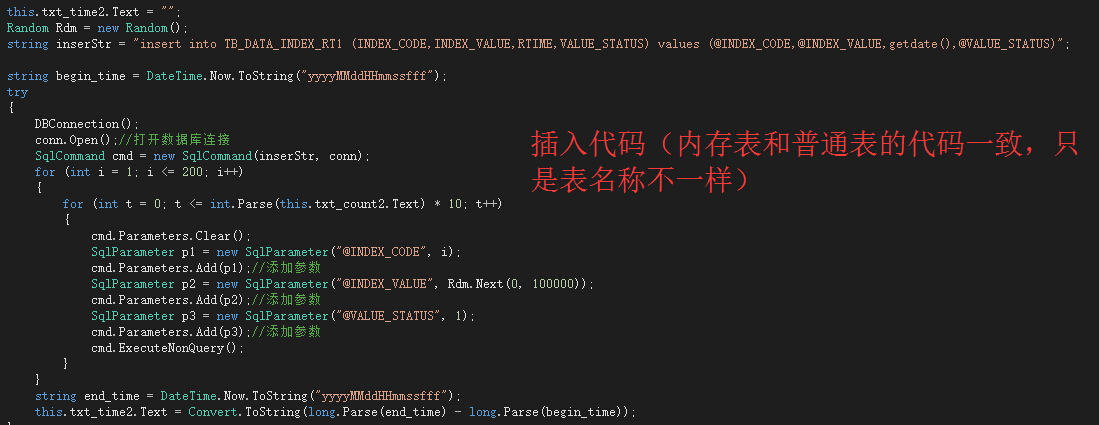
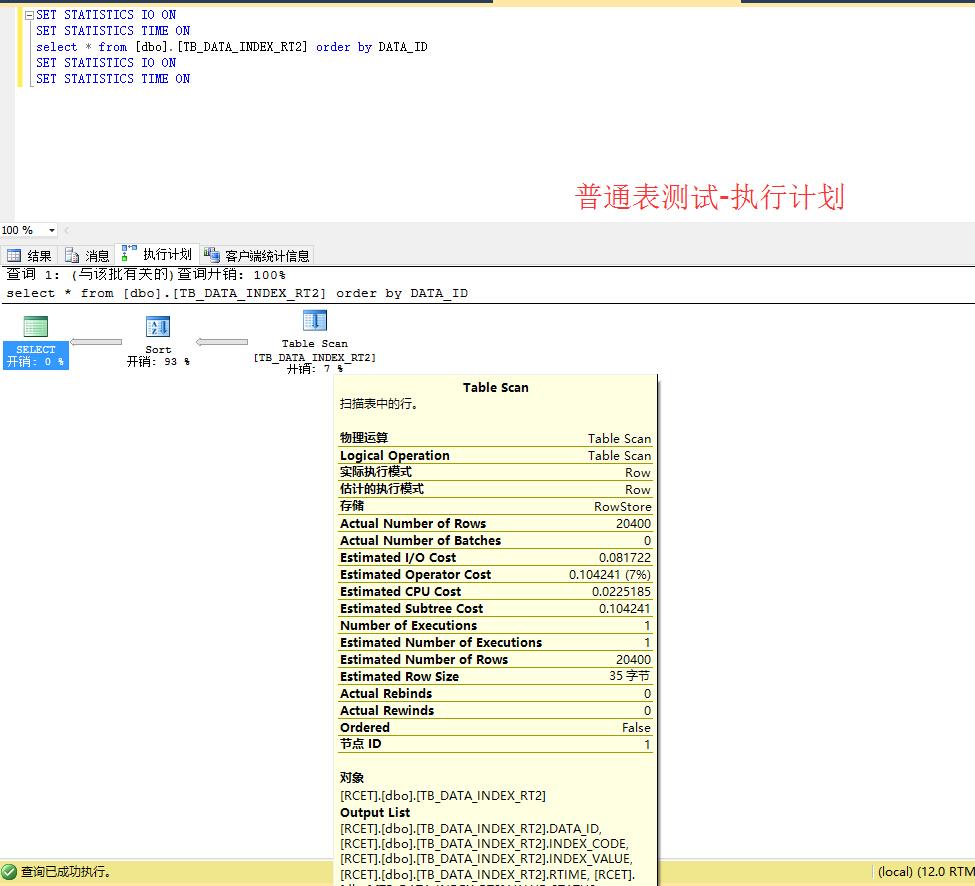
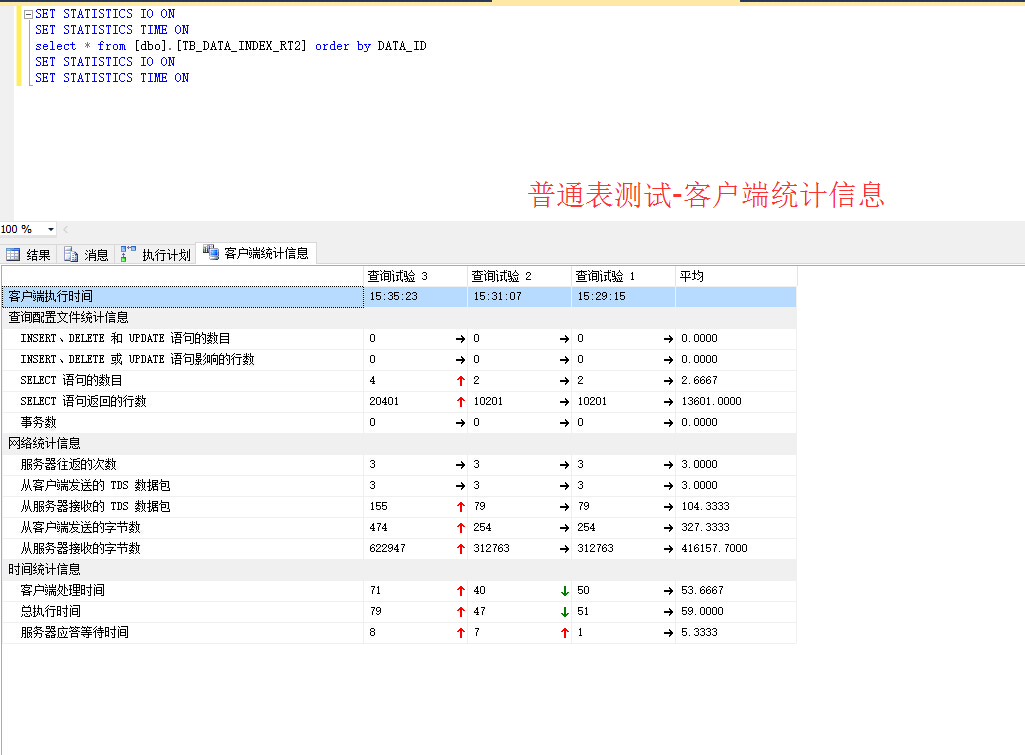
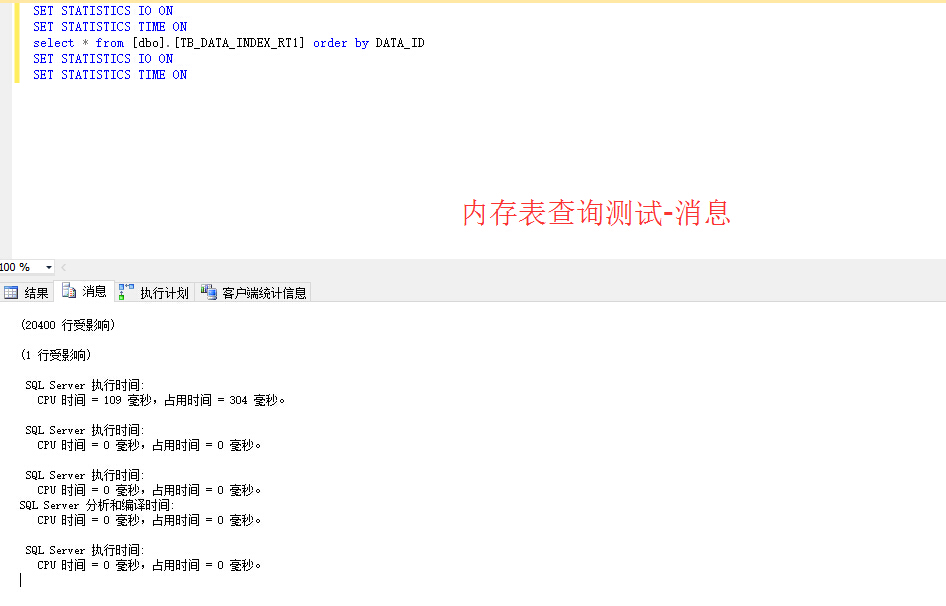
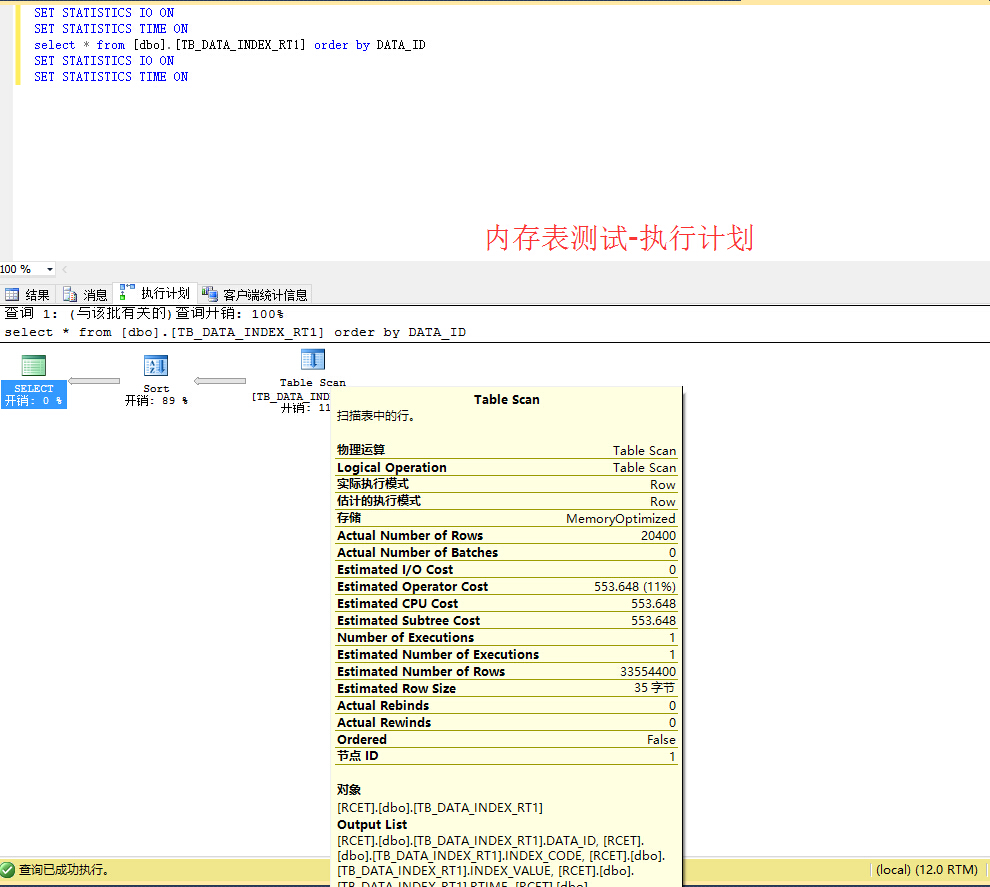
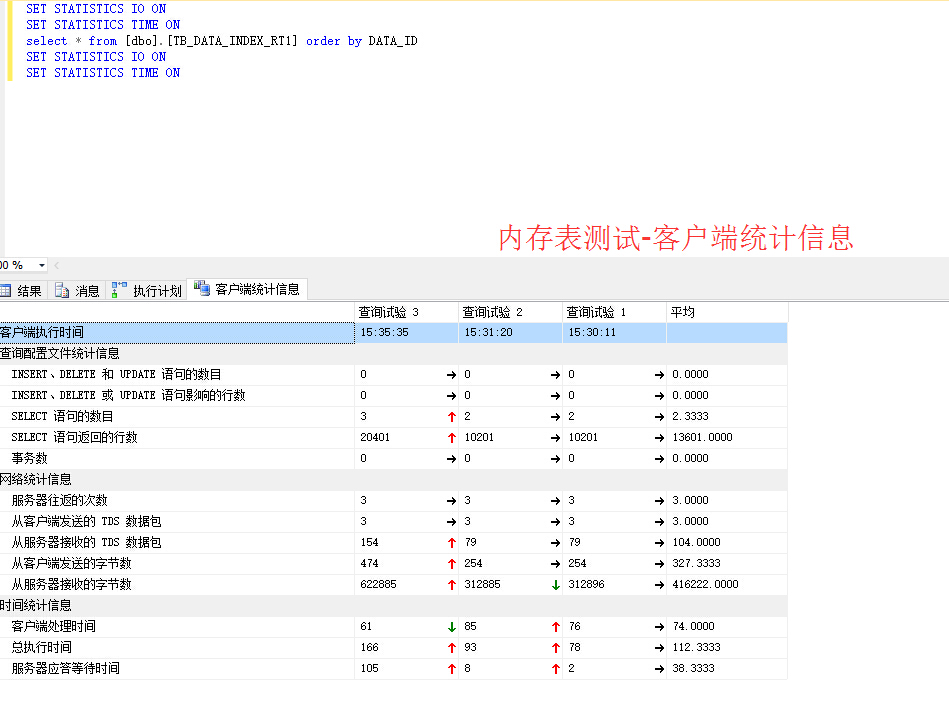




 [/quote]
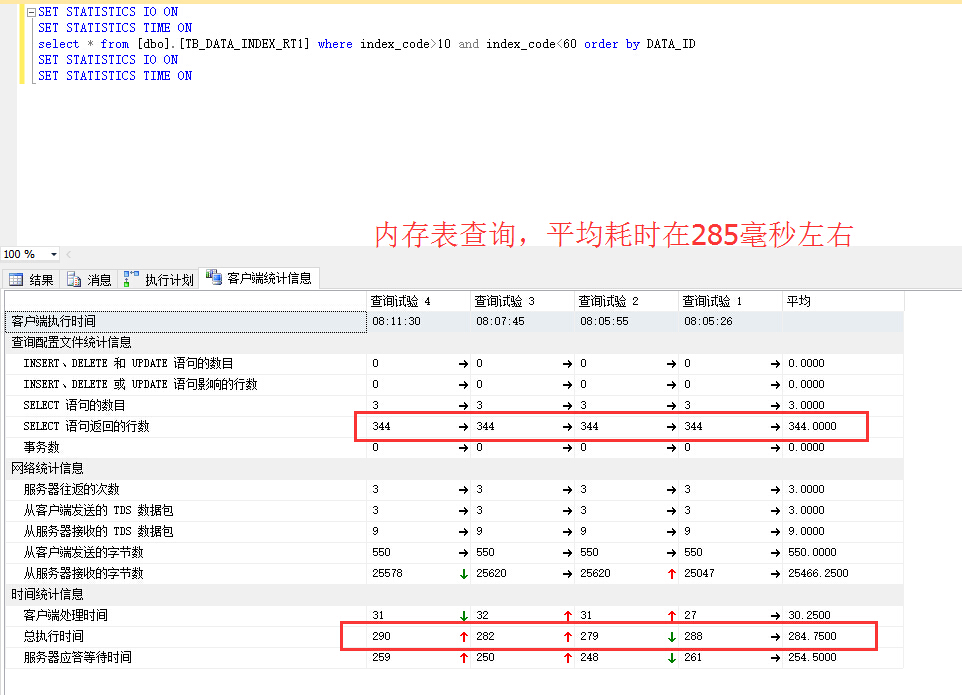
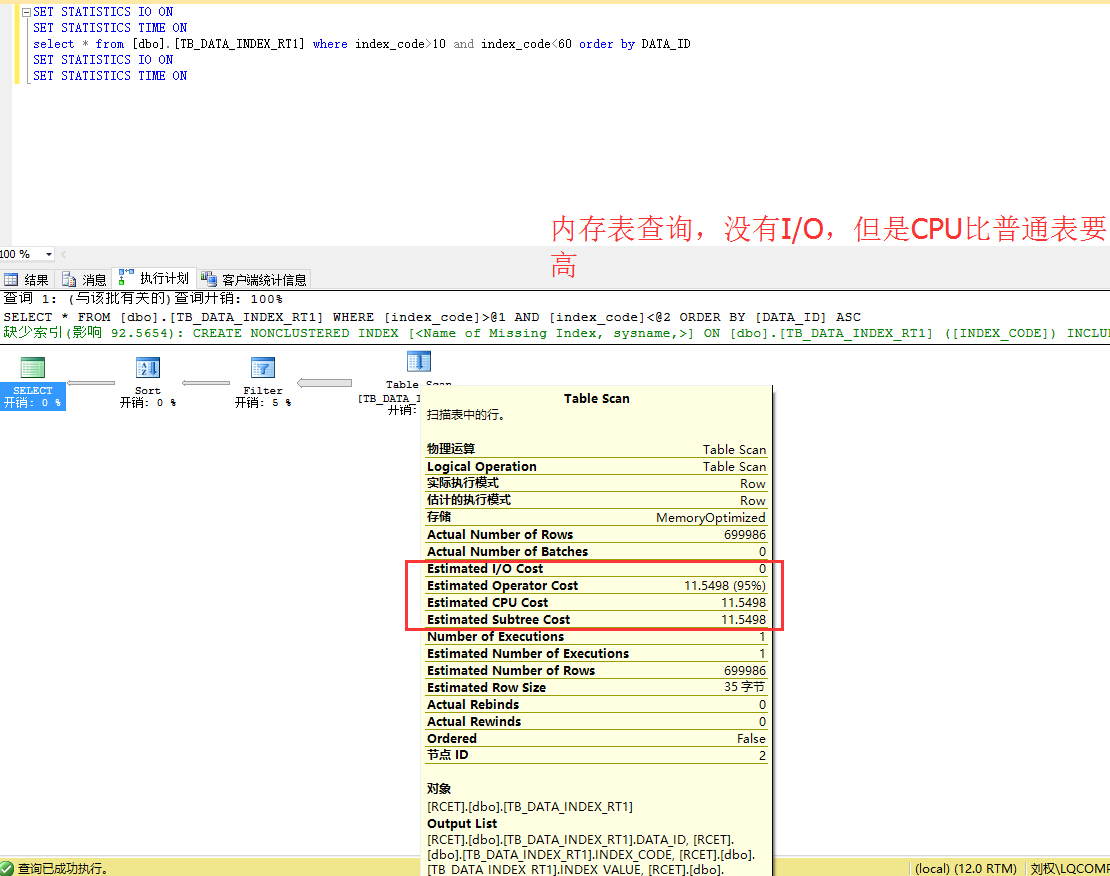
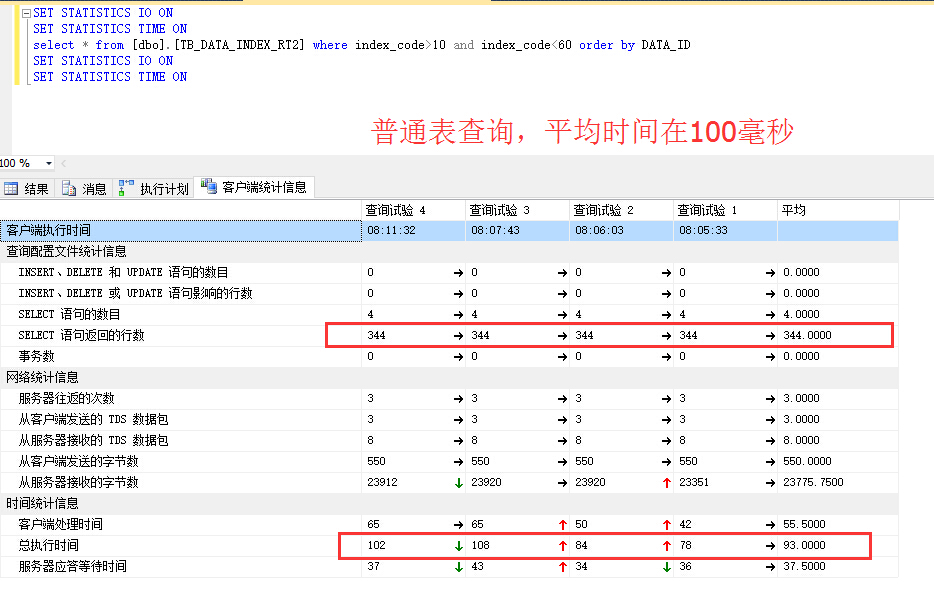
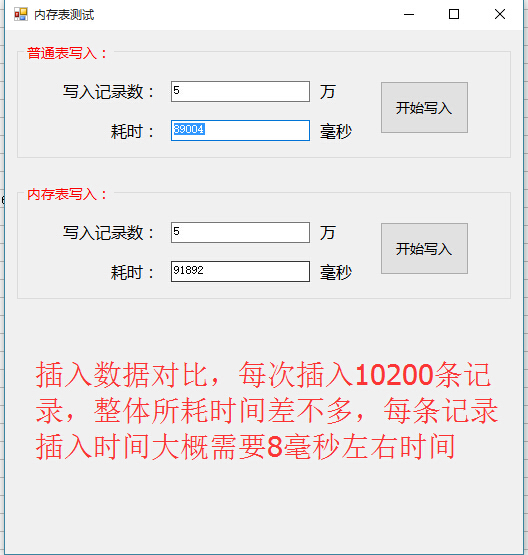
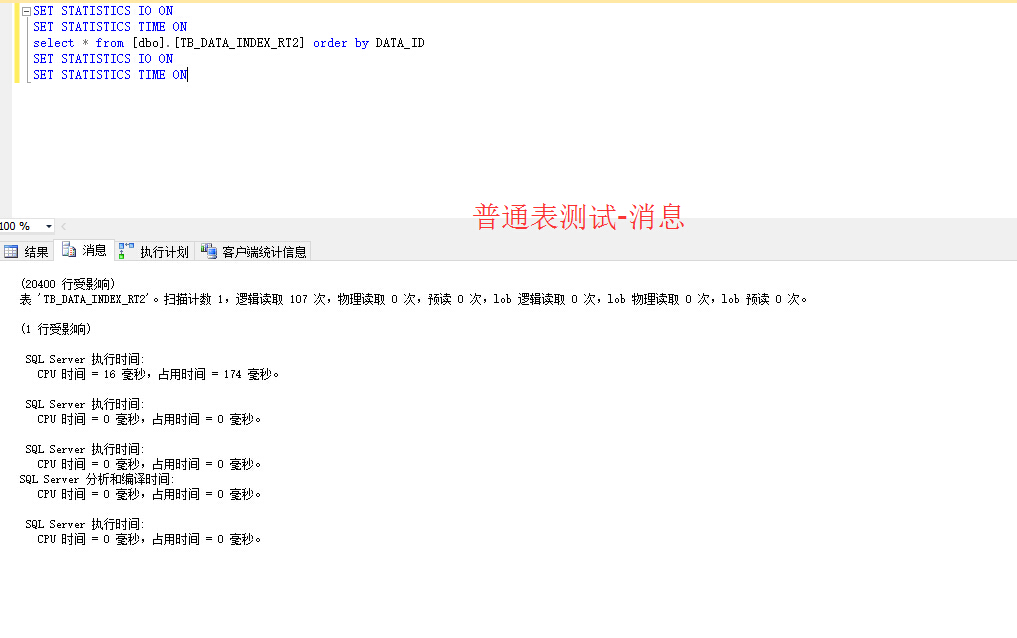
谢谢,目前还没用上SQL SERVER,仅仅是做数据库选型的,SQL SERVER2014有内存表,所以想测试下内存表到底能达到什么效果,看看是否能达到工业实时数据库的性能!
[/quote]
谢谢,目前还没用上SQL SERVER,仅仅是做数据库选型的,SQL SERVER2014有内存表,所以想测试下内存表到底能达到什么效果,看看是否能达到工业实时数据库的性能!