



57,063
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享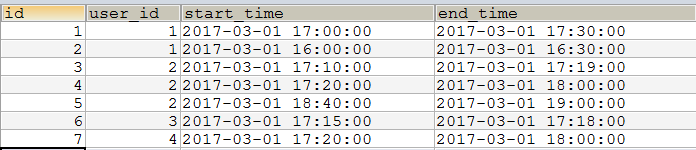
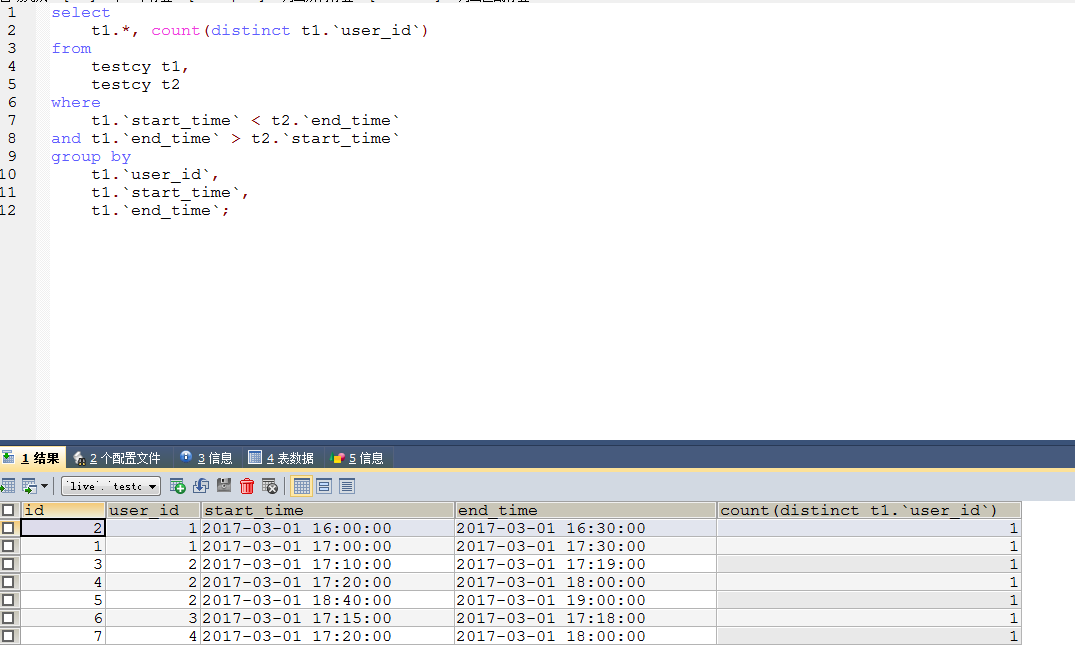
SELECT
t1.*, count(t1.`user_id`)
FROM
testcy t1,
testcy t2
WHERE
t1.`start_time` < t2.`end_time`
AND t1.`end_time` > t2.`start_time`
GROUP BY
t1.`user_id`,
t1.`start_time`,
t1.`end_time`;


 或许这就是大佬吧...
或许这就是大佬吧...
SELECT
t1.*, (SELECT count(DISTINCT `user_id`)
from testcy t2 where t1.`start_time` <= t2.`start_time`
AND t1.`end_time` >= t2.`end_time`) as 在线人数
FROM
testcy t1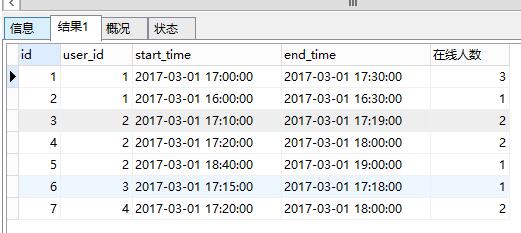
 谢谢大神的指教
谢谢大神的指教SELECT
t1.*, (SELECT count(t2.`id`)
from testcy t2 where t1.`start_time` <= t2.`start_time`
AND t1.`end_time` >= t2.`start_time` and t1.group_id = t2.group_id ) as count
FROM
testcy t1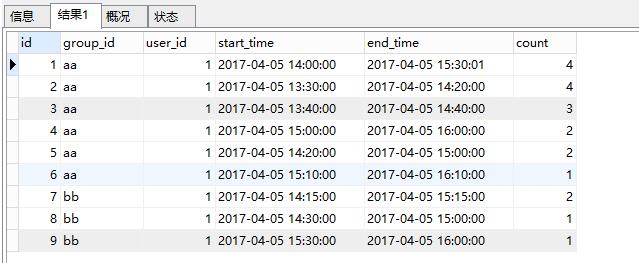
create table `testcy` (
`id` int (11),
`group_id` varchar (255),
`user_id` int (11),
`start_time` datetime ,
`end_time` datetime
);
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('1','aa','1','2017-04-05 14:00:00','2017-04-05 15:30:01');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('2','aa','1','2017-04-05 13:30:00','2017-04-05 14:20:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('3','aa','1','2017-04-05 13:40:00','2017-04-05 14:40:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('4','aa','1','2017-04-05 15:00:00','2017-04-05 16:00:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('5','aa','1','2017-04-05 14:20:00','2017-04-05 15:00:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('6','aa','1','2017-04-05 15:10:00','2017-04-05 16:10:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('7','bb','1','2017-04-05 14:15:00','2017-04-05 15:15:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('8','bb','1','2017-04-05 14:30:00','2017-04-05 15:00:00');
insert into `testcy` (`id`, `group_id`, `user_id`, `start_time`, `end_time`) values('9','bb','1','2017-04-05 15:30:00','2017-04-05 16:00:00');select
t1.*, (select count(t2.`id`)
from testcy t2 where t1.`start_time` <= t2.`end_time`
and t1.`end_time` >= t2.`start_time` and t1.group_id = t2.group_id ) as count
from
testcy t1; id group_id user_id start_time end_time count
------ -------- ------- ------------------- ------------------- --------
1 aa 1 2017-04-05 14:00:00 2017-04-05 15:30:01 6
2 aa 1 2017-04-05 13:30:00 2017-04-05 14:20:00 4
3 aa 1 2017-04-05 13:40:00 2017-04-05 14:40:00 4
4 aa 1 2017-04-05 15:00:00 2017-04-05 16:00:00 4
5 aa 1 2017-04-05 14:20:00 2017-04-05 15:00:00 5
6 aa 1 2017-04-05 15:10:00 2017-04-05 16:10:00 3
7 bb 1 2017-04-05 14:15:00 2017-04-05 15:15:00 2
8 bb 1 2017-04-05 14:30:00 2017-04-05 15:00:00 2
9 bb 1 2017-04-05 15:30:00 2017-04-05 16:00:00 1 请指教我该如何写这样的sql
请指教我该如何写这样的sqlSELECT
t1.*, (SELECT count(t2.`id`)
from testcy t2 where t1.`start_time` <= t2.`start_time`
AND t1.`end_time` >= t2.`end_time` and t1.group_id = t2.group_id ) as count
FROM
testcy t1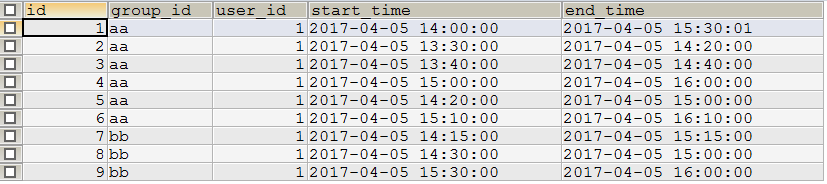

select t1.*,count(t2.`id`)
from testcy t1,testcy t2
where t1.`group_id`=t2.group_id
and t1.`start_time` <= t2.`end_time`
and t1.`end_time` >= t2.`start_time`
group by t1.`id`,t1.`start_time`,t1.`end_time`;SELECT
t1.*, count(distinct t1.`user_id`)
FROM
testcy t1,
testcy t2
WHERE
t1.`start_time` < t2.`end_time`
AND t1.`end_time` > t2.`start_time`
GROUP BY
t1.`user_id`,
t1.`start_time`,
t1.`end_time`;
