我使用CDH5搭建的集群。前端传来的数据,我需要及时的保存到hive中。这里我用hdfs 的append方法,直接将数据写入到hive对应的表中。但是在写入中,用不了多长时间就会抛出All datanodes DatanodeInfoWithStorage xxxx are bad. Aborting。看日志发现是datanode抛出了DiskOutOfSpaceException。通过仔细观察我发现,在append数据的时候,datanode磁盘容量急速被用掉,但实际上并没有被用到那么多,这里感觉是程序检测异常。
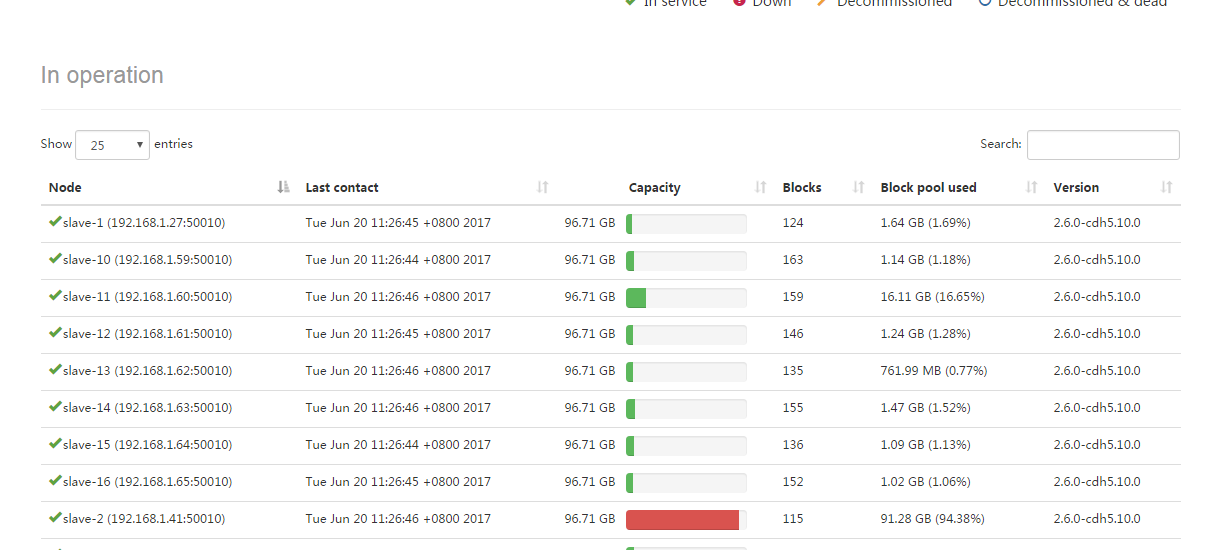
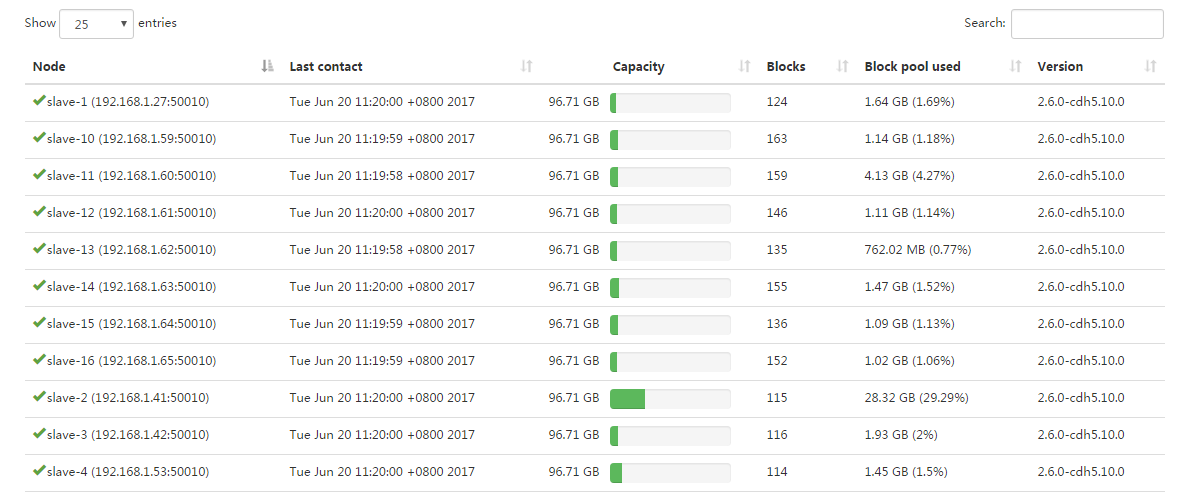
如上图中的slave-2那个机器不到一会磁盘就被用完了,但等报出异常后,slave-2的硬盘使用情况又恢复正常了。
请问有高手遇到过这个问题吗?已经困扰几天了,希望高人解答!!





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

