社区
Java EE
帖子详情
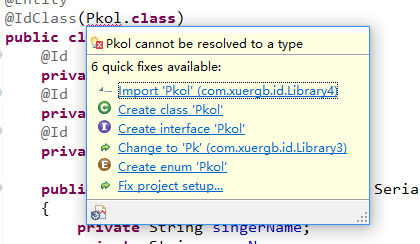
hibernate的联合主键注解idclass用法为啥不对
a271256939
2017-07-21 02:34:55
...全文
300
5
打赏
收藏
hibernate的联合主键注解idclass用法为啥不对
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
a271256939
2017-07-26
打赏
举报
回复
a271256939
2017-07-26
打赏
举报
回复
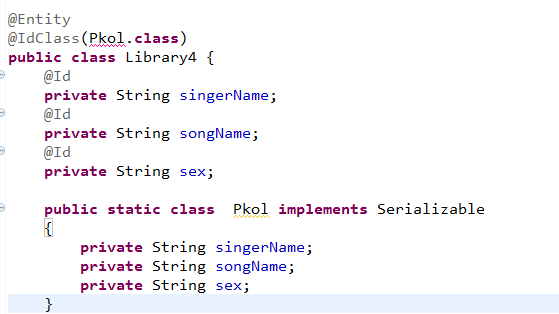
这是官方文档,我的问题解决了 我把idclass 放到下边了,跟官方文档完全不一样啊,这个文档是我下载hibernate带的啊!!!这怎么回事
a271256939
2017-07-26
打赏
举报
回复
引用 1 楼 CQ20170712 的回复:
看它报什么错,可以另外设计一个类
我不想新建一个类,我的写法和官方文档一样的,报错如图
邹进颖
2017-07-24
打赏
举报
回复
联合主键要设置另外一个类来封装主键信息http://blog.csdn.net/robinpipi/article/details/7655388 这里面的第三种方法比较容易懂
CQ2017CQ
2017-07-23
打赏
举报
回复
看它报什么错,可以另外设计一个类
Hibernate
注释大全收藏
Hibernate
注释大全收藏 声明实体Bean @Entity public
class
Flight implements Serializable { Long
id
; @
Id
public Long get
Id
() { return
id
; } public vo
id
set
Id
(Long
id
) { this.
id
=
id
; } } @Entity
注解
将一个类声明为实体 Bean, @
Id
注解
声明了该实体Bean的标识属性。
Hibernate
可以对类的属性或者方法进行
注解
。属性对应field类别,方法的 getXxx()对应property类别。 定义表 通过 @Table 为实体Bean指定对应数据库表,目录和schema的名字。 @Entity @Table(name="tbl_sky") public
class
Sky implements Serializable { ... @Table
注解
包含一个schema和一个catelog 属性,使用@UniqueConstraints 可以定义表的唯一约束。 @Table(name="tbl_sky", uniqueConstraints = {@UniqueConstraint(columnNames={"month", "day"})} ) 上述代码在 "month" 和 "day" 两个 field 上加上 unique constrainst. @Version
注解
用于支持乐观锁版本控制。 @Entity public
class
Flight implements Serializable { ... @Version @Column(name="OPTLOCK") public Integer getVersion() { ... } } version属性映射到 "OPTLOCK" 列,entity manager 使用这个字段来检测冲突。 一般可以用 数字 或者 timestamp 类型来支持 version. 实体Bean中所有非static 非 transient 属性都可以被持久化,除非用@Transient
注解
。 默认情况下,所有属性都用 @Basic
注解
。 public transient int counter; //transient property private String firstname; //persistent property @Transient String getLengthInMeter() { ... } //transient property String getName() {... } // persistent property @Basic int getLength() { ... } // persistent property @Basic(fetch = FetchType.LAZY) String getDetailedComment() { ... } // persistent property @Temporal(TemporalType.TIME) java.util.Date getDepartureTime() { ... } // persistent property @Enumerated(EnumType.STRING) Starred getNote() { ... } //enum persisted as String in database 上述代码中 counter, lengthInMeter 属性将忽略不被持久化,而 firstname, name, length 被定义为可持久化和可获取的。 @TemporalType.(DATE,TIME,TIMESTAMP) 分别Map java.sql.(Date, Time, Timestamp). @Lob
注解
属性将被持久化为 Blog 或 Clob 类型。具体的java.sql.Clob, Character[], char[] 和 java.lang.String 将被持久化为 Clob 类型. java.sql.Blob, Byte[], byte[] 和 serializable type 将被持久化为 Blob 类型。 @Lob public String getFullText() { return fullText; // clob type } @Lob public byte[] getFullCode() { return fullCode; // blog type } @Column
注解
将属性映射到列。 @Entity public
class
Flight implements Serializable { ... @Column(updatable = false, name = "flight_name", nullable = false, length=50) public String getName() { ... } 定义 name 属性映射到 flight_name column, not null, can't update, length equal 50 @Column( name="columnName"; (1) 列名 boolean unique() default false; (2) 是否在该列上设置唯一约束 boolean nullable() default true; (3) 列可空? boolean insertable() default true; (4) 该列是否作为生成 insert语句的一个列 boolean updatable() default true; (5) 该列是否作为生成 update语句的一个列 String columnDefinition() default ""; (6) 默认值 String table() default ""; (7) 定义对应的表(deault 是主表) int length() default 255; (8) 列长度 int precision() default 0; // decimal precision (9) decimal精度 int scale() default 0; // decimal scale (10) decimal长度 嵌入式对象(又称组件)也就是别的对象定义的属性 组件类必须在类一级定义 @Embeddable
注解
。在特定的实体关联属性上使用 @Embeddable 和 @AttributeOverr
id
e
注解
可以覆盖该属性对应的嵌入式对象的列映射。 @Entity public
class
Person implements Serializable { // Persistent component using defaults Address homeAddress; @Embedded @AttributeOverr
id
es( { @AttributeOverr
id
e(name="iso2", column = @Column(name="bornIso2") ), @AttributeOverr
id
e(name="name", column = @Column(name="bornCountryName") ) } ) Country bornIn; ... } @Embeddable public
class
Address implements Serializable { String city; Country nationality; //no overr
id
ing here } @Embeddable public
class
Country implements Serializable { private String iso2; @Column(name="countryName") private String name; public String getIso2() { return iso2; } public vo
id
setIso2(String iso2) { this.iso2 = iso2; } public String getName() { return name; } public vo
id
setName(String name) { this.name = name; } ... } Person 类定义了 Address 和 Country 对象,具体两个类实现见上。 无
注解
属性默认值: • 属性为简单类型,则映射为 @Basic • 属性对应的类型定义了 @Embeddable
注解
,则映射为 @Embedded • 属性对应的类型实现了Serializable,则属性被映射为@Basic并在一个列中保存该对象的serialized版本。 • 属性的类型为 java.sql.Clob or java.sql.Blob, 则映射到 @Lob 对应的类型。 映射主键属性 @
Id
注解
可将实体Bean中某个属性定义为主键,使用@GenerateValue
注解
可以定义该标识符的生成策略。 • AUTO - 可以是
id
entity column, sequence 或者 table 类型,取决于不同底层的数据库 • TABLE - 使用table保存
id
值 •
ID
ENTITY -
id
entity column • SEQUENCE - seque nce @
Id
@GeneratedValue(strategy=GenerationType.SEQUENCE, generator="SEQ_STORE") public Integer get
Id
() { ... } @
Id
@GeneratedValue(strategy=GenerationType.
ID
ENTITY) public Long get
Id
() { ... } AUTO 生成器,适用与可移值的应用,多个@
Id
可以共享同一个
id
entifier生成器,只要把generator属性设成相同的值就可以。通过@SequenceGenerator 和 @TableGenerator 可以配置不同的
id
entifier 生成器。
//and the annotation equivalent @javax.persistence.TableGenerator( name="EMP_GEN", table="GENERATOR_TABLE", pkColumnName = "key", valueColumnName = "hi" pkColumnValue="EMP", allocationSize=20 )
//and the annotation equivalent @javax.persistence.SequenceGenerator( name="SEQ_GEN", sequenceName="my_sequence", allocationSize=20 ) The next example shows the definition of a sequence generator in a
class
scope: @Entity @javax.persistence.SequenceGenerator( name="SEQ_STORE", sequenceName="my_sequence" ) public
class
Store implements Serializable { private Long
id
; @
Id
@GeneratedValue(strategy=GenerationType.SEQUENCE, generator="SEQ_STORE") public Long get
Id
() { return
id
; } } Store类使用名为my_sequence的sequence,并且SEQ_STORE生成器对于其他类是不可见的。 通过下面语法,你可以定义组合键。 • 将组件类
注解
为 @Embeddable, 并将组件的属性
注解
为 @
Id
• 将组件的属性
注解
为 @Embedded
Id
• 将类
注解
为 @
Id
Class
,并将该实体中所有主键的属性都
注解
为 @
Id
@Entity @
Id
Class
(FootballerPk.
class
) public
class
Footballer { //part of the
id
key @
Id
public String getFirstname() { return firstname; } public vo
id
setFirstname(String firstname) { this.firstname = firstname; } //part of the
id
key @
Id
public String getLastname() { return lastname; } public vo
id
setLastname(String lastname) { this.lastname = lastname; } public String getClub() { return club; } public vo
id
setClub(String club) { this.club = club; } //appropriate equals() and hashCode() implementation } @Embeddable public
class
FootballerPk implements Serializable { //same name and type as in Footballer public String getFirstname() { return firstname; } public vo
id
setFirstname(String firstname) { this.firstname = firstname; } //same name and type as in Footballer public String getLastname() { return lastname; } public vo
id
setLastname(String lastname) { this.lastname = lastname; } //appropriate equals() and hashCode() implementation } @Entity @AssociationOverr
id
e( name="
id
.channel", joinColumns = @JoinColumn(name="chan_
id
") ) public
class
TvMagazin { @Embedded
Id
public TvMagazinPk
id
; @Temporal(TemporalType.TIME) Date time; } @Embeddable public
class
TvMagazinPk implements Serializable { @ManyToOne public Channel channel; public String name; @ManyToOne public Presenter presenter; } 映射继承关系 EJB支持3种类型的继承。 • Table per
Class
Strategy: the
class> element in
Hibernate
每个类一张表 • Single Table per
Class
Hierarchy Strategy: the
class> element in
Hibernate
每个类层次结构一张表 • Joined Sub
class
Strategy: the
class> element in
Hibernate
连接的子类策略 @Inheritance
注解
来定义所选的之类策略。 每个类一张表 @Entity @Inheritance(strategy = InheritanceType.TABLE_PER_
CLASS
) public
class
Flight implements Serializable { 有缺点,如多态查询或关联。
Hibernate
使用 SQL Union 查询来实现这种策略。 这种策略支持双向的一对多关联,但不支持
ID
ENTIFY 生成器策略,因为
ID
必须在多个表间共享。一旦使用就不能使用AUTO和
ID
ENTIFY生成器。 每个类层次结构一张表 @Entity @Inheritance(strategy=InheritanceType.SINGLE_TABLE) @DiscriminatorColumn( name="planetype", discriminatorType=DiscriminatorType.STRING ) @DiscriminatorValue("Plane") public
class
Plane { ... } @Entity @DiscriminatorValue("A320") public
class
A320 extends Plane { ... } 整个层次结构中的所有父类和子类属性都映射到同一个表中,他们的实例通过一个辨别符列(discriminator)来区分。 Plane 是父类。@DiscriminatorColumn
注解
定义了辨别符列。对于继承层次结构中的每个类, @DiscriminatorValue
注解
指定了用来辨别该类的值。 辨别符列名字默认为 DTYPE,其默认值为实体名。其类型为DiscriminatorType.STRING。 连接的子类 @Entity @Inheritance(strategy=InheritanceType.JOINED) public
class
Boat implements Serializable { ... } @Entity public
class
Ferry extends Boat { ... } @Entity @PrimaryKeyJoinColumn(name="BOAT_
ID
") public
class
AmericaCup
Class
extends Boat { ... } 以上所有实体使用 JOINED 策略 Ferry和Boat
class
使用同名的主键关联(eg: Boat.
id
= Ferry.
id
), AmericaCup
Class
和 Boat 关联的条件为 Boat.
id
= AmericaCup
Class
.BOAT_
ID
. 从父类继承的属性 @MappedSuper
class
public
class
BaseEntity { @Basic @Temporal(TemporalType.TIMESTAMP) public Date getLastUpdate() { ... } public String getLastUpdater() { ... } ... } @Entity
class
Order extends BaseEntity { @
Id
public Integer get
Id
() { ... } ... } 继承父类的一些属性,但不用父类作为映射实体,这时候需要 @MappedSuper
class
注解
。 上述实体映射到数据库中的时候对应 Order 实体Bean, 其具有
id
, lastUpdate, lastUpdater 三个属性。如果没有@MappedSuper
class
注解
,则父类中属性忽略,这是 Order 实体 Bean 只有
id
一个属性。 映射实体Bean的关联关系 一对一 使用 @OneToOne
注解
可以建立实体Bean之间的一对一关系。一对一关系有3种情况。 • 关联的实体都共享同样的主键。 @Entity public
class
Body { @
Id
public Long get
Id
() { return
id
; } @OneToOne(cascade = CascadeType.ALL) @PrimaryKeyJoinColumn public Heart getHeart() { return heart; } ... } @Entity public
class
Heart { @
Id
public Long get
Id
() { ...} } 通过@PrimaryKeyJoinColumn
注解
定义了一对一的关联关系。 多对一 使用 @ManyToOne
注解
定义多对一关系。 @Entity() public
class
Flight implements Serializable { @ManyToOne( cascade = {CascadeType.PERSIST, CascadeType.MERGE} ) @JoinColumn(name="COMP_
ID
") public Company getCompany() { return company; } ... } 其中@JoinColumn
注解
是可选的,关键字段默认值和一对一关联的情况相似。列名为:主题的关联属性名 + 下划线 + 被关联端的主键列名。本例中为company_
id
,因为关联的属性是company, Company的主键为
id
. @ManyToOne
注解
有个targetEntity属性,该参数定义了目标实体名。通常不需要定义,大部分情况为默认值。但下面这种情况则需要 targetEntity 定义(使用接口作为返回值,而不是常用的实体)。 @Entity() public
class
Flight implements Serializable { @ManyToOne(cascade= {CascadeType.PERSIST,CascadeType.MERGE},targetEntity= CompanyImpl.
class
) @JoinColumn(name="COMP_
ID
") public Company getCompany() { return company; } ... } public interface Company { ... 多对一也可以通过关联表的方式来映射,通过 @JoinTable
注解
可定义关联表。该关联表包含指回实体的外键(通过@JoinTable.joinColumns)以及指向目标实体表的外键(通过@JoinTable.inverseJoinColumns). @Entity() public
class
Flight implements Serializable { @ManyToOne( cascade = {CascadeType.PERSIST, CascadeType.MERGE} ) @JoinTable(name="Flight_Company", joinColumns = @JoinColumn(name="FLIGHT_
ID
"), inverseJoinColumns = @JoinColumn(name="COMP_
ID
") ) public Company getCompany() { return company; } ... } 集合类型 一对多 @OneToMany
注解
可定义一对多关联。一对多关联可以是双向的。 双向 规范中多对一端几乎总是双向关联中的主体(owner)端,而一对多的关联
注解
为 @OneToMany(mappedBy=) @Entity public
class
Troop { @OneToMany(mappedBy="troop") public Set
getSoldiers() { ... } @Entity public
class
Soldier { @ManyToOne @JoinColumn(name="troop_fk") public Troop getTroop() { ... } Troop 通过troop属性和Soldier建立了一对多的双向关联。在 mappedBy 端不必也不能定义任何物理映射。 单向 @Entity public
class
Customer implements Serializable { @OneToMany(cascade=CascadeType.ALL, fetch=FetchType.EAGER) @JoinColumn(name="CUST_
ID
") public Set
getTickets() { ... } @Entity public
class
Ticket implements Serializable { ... //no b
id
ir } 一般通过连接表来实现这种关联,可以通过@JoinColumn
注解
来描述这种单向关联关系。上例 Customer 通过 CUST_
ID
列和 Ticket 建立了单向关联关系。 通过关联表来处理单向关联 @Entity public
class
Trainer { @OneToMany @JoinTable( name="TrainedMonkeys", joinColumns = @JoinColumn( name="trainer_
id
"), inverseJoinColumns = @JoinColumn( name="monkey_
id
") ) public Set
getTrainedMonkeys() { ... } @Entity public
class
Monkey { ... //no b
id
ir } 通过关联表来处理单向一对多关系是首选,这种关联通过 @JoinTable
注解
来进行描述。上例子中 Trainer 通过TrainedMonkeys表和Monkey建立了单向关联关系。其中外键trainer_
id
关联到Trainer(joinColumns)而外键monkey_
id
关联到Monkey(inverseJoinColumns). 默认处理机制 通过连接表来建立单向一对多关联不需要描述任何物理映射,表名由一下3个部分组成,主表(owner table)表名 + 下划线 + 从表(the other s
id
e table)表名。指向主表的外键名:主表表名+下划线+主表主键列名 指向从表的外键定义为唯一约束,用来表示一对多的关联关系。 @Entity public
class
Trainer { @OneToMany public Set
getTrainedTigers() { ... } @Entity public
class
Tiger { ... //no b
id
ir } 上述例子中 Trainer 和 Tiger 通过 Trainer_Tiger 连接表建立单向关联关系。其中外键 trainer_
id
关联到 Trainer表,而外键 trainedTigers_
id
关联到 Tiger 表。 多对多 通过 @ManyToMany
注解
定义多对多关系,同时通过 @JoinTable
注解
描述关联表和关联条件。其中一端定义为 owner, 另一段定义为 inverse(对关联表进行更新操作,这段被忽略)。 @Entity public
class
Employer implements Serializable { @ManyToMany( targetEntity=org.
hibernate
.test.metadata.manytomany.Employee.
class
, cascade={CascadeType.PERSIST, CascadeType.MERGE} ) @JoinTable( name="EMPLOYER_EMPLOYEE", joinColumns=@JoinColumn(name="EMPER_
ID
"), inverseJoinColumns=@JoinColumn(name="EMPEE_
ID
") ) public Collection getEmployees() { return employees; } ... } @Entity public
class
Employee implements Serializable { @ManyToMany( cascade = {CascadeType.PERSIST, CascadeType.MERGE}, mappedBy = "employees", targetEntity = Employer.
class
) public Collection getEmployers() { return employers; } } 默认值: 关联表名:主表表名 + 下划线 + 从表表名;关联表到主表的外键:主表表名 + 下划线 + 主表中主键列名;关联表到从表的外键名:主表中用于关联的属性名 + 下划线 + 从表的主键列名。 用 cascading 实现传播持久化(Transitive persistence) cascade 属性接受值为 CascadeType 数组,其类型如下: • CascadeType.PERSIST: cascades the persist (create) operation to associated entities persist() is called or if the entity is managed 如果一个实体是受管状态,或者当 persist() 函数被调用时,触发级联创建(create)操作。 • CascadeType.MERGE: cascades the merge operation to associated entities if merge() is called or if the entity is managed 如果一个实体是受管状态,或者当 merge() 函数被调用时,触发级联合并(merge)操作。 • CascadeType.REMOVE: cascades the remove operation to associated entities if delete() is called 当 delete() 函数被调用时,触发级联删除(remove)操作。 • CascadeType.REFRESH: cascades the refresh operation to associated entities if refresh() is called 当 refresh() 函数被调用时,出发级联更新(refresh)操作。 • CascadeType.ALL: all of the above 以上全部 映射二级列表 使用类一级的 @SecondaryTable 和 @SecondaryTables
注解
可以实现单个实体到多个表的映射。使用 @Column 或者 @JoinColumn
注解
中的 table 参数可以指定某个列所属的特定表。 @Entity @Table(name="MainCat") @SecondaryTables({ @SecondaryTable(name="Cat1", pkJoinColumns={ @PrimaryKeyJoinColumn(name="cat_
id
", referencedColumnName="
id
")}), @SecondaryTable(name="Cat2", uniqueConstraints={ @UniqueConstraint(columnNames={"storyPart2"})}) }) public
class
Cat implements Serializable { private Integer
id
; private String name; private String storyPart1; private String storyPart2; @
Id
@GeneratedValue public Integer get
Id
() { return
id
; } public String getName() { return name; } @Column(table="Cat1") public String getStoryPart1() { return storyPart1; } @Column(table="Cat2") public String getStoryPart2() { return storyPart2; } 上述例子中, name 保存在 MainCat 表中,storyPart1保存在 Cat1 表中,storyPart2 保存在 Cat2 表中。 Cat1 表通过外键 cat_
id
和 MainCat 表关联, Cat2 表通过
id
列和 MainCat 表关联。对storyPart2 列还定义了唯一约束。 映射查询 使用
注解
可以映射 EJBQL/HQL 查询,@NamedQuery 和 @NamedQueries 是可以使用在类级别或者JPA的XML文件中的
注解
。
select p from Plane p
...
... @Entity @NamedQuery(name="night.moreRecentThan", query="select n from Night n where n.date >= :date") public
class
Night { ... } public
class
MyDao { doStuff() { Query q = s.getNamedQuery("night.moreRecentThan"); q.setDate( "date", aMonthAgo ); List results = q.list(); ... } ... } 可以通过定义 QueryHint 数组的 hints 属性为查询提供一些 hint 信息。下图是一些
Hibernate
hints: 映射本地化查询 通过@SqlResultSetMapping
注解
来描述 SQL 的 resultset 结构。如果定义多个结果集映射,则用 @SqlResultSetMappings。 @NamedNativeQuery(name="night&area", query="select night.
id
n
id
, night.night_duration, " + " night.night_date, area.
id
a
id
, night.area_
id
, area.name " + "from Night night, Area area where night.area_
id
= area.
id
", resultSetMapping="joinMapping") @SqlResultSetMapping( name="joinMapping", entities={ @EntityResult(entity
Class
=org.
hibernate
.test.annotations.query.Night.
class
, fields = { @FieldResult(name="
id
", column="n
id
"), @FieldResult(name="duration", column="night_duration"), @FieldResult(name="date", column="night_date"), @FieldResult(name="area", column="area_
id
"), discriminatorColumn="disc" }), @EntityResult(entity
Class
=org.
hibernate
.test.annotations.query.Area.
class
, fields = { @FieldResult(name="
id
", column="a
id
"), @FieldResult(name="name", column="name") }) } ) 上面的例子,名为“night&area”的查询和 "joinMapping"结果集映射对应,该映射返回两个实体,分别为 Night 和 Area, 其中每个属性都和一个列关联,列名通过查询获取。 @Entity @SqlResultSetMapping(name="implicit", entities=@EntityResult( entity
Class
=org.
hibernate
.test.annotations.@NamedNativeQuery( name="implicitSample", query="select * from SpaceShip", resultSetMapping="implicit") public
class
SpaceShip { private String name; private String model; private double speed; @
Id
public String getName() { return name; } public vo
id
setName(String name) { this.name = name; } @Column(name="model_txt") public String getModel() { return model; } public vo
id
setModel(String model) { this.model = model; } public double getSpeed() { return speed; } public vo
id
setSpeed(double speed) { this.speed = speed; } } 上例中 model1 属性绑定到 model_txt 列,如果和相关实体关联设计到组合主键,那么应该使用 @FieldResult
注解
来定义每个外键列。@FieldResult的名字组成:定义这种关系的属性名字 + "." + 主键名或主键列或主键属性。 @Entity @SqlResultSetMapping(name="compositekey", entities=@EntityResult(entity
Class
=org.
hibernate
.test.annotations.query.SpaceShip.
class
, fields = { @FieldResult(name="name", column = "name"), @FieldResult(name="model", column = "model"), @FieldResult(name="speed", column = "speed"), @FieldResult(name="captain.firstname", column = "firstn"), @FieldResult(name="captain.lastname", column = "lastn"), @FieldResult(name="dimensions.length", column = "length"), @FieldResult(name="dimensions.w
id
th", column = "w
id
th") }), columns = { @ColumnResult(name = "surface"), @ColumnResult(name = "volume") } ) @NamedNativeQuery(name="compositekey", query="select name, model, speed, lname as lastn, fname as firstn, length, w
id
th, length * w
id
th as resultSetMapping="compositekey") }) 如果查询返回的是单个实体,或者打算用系统默认的映射,这种情况下可以不使用 resultSetMapping,而使用result
Class
属性,例如: @NamedNativeQuery(name="implicitSample", query="select * from SpaceShip", result
Class
=SpaceShip.
class
) public
class
SpaceShip {
Hibernate
独有的
注解
扩展
Hibernate
提供了与其自身特性想吻合的
注解
,org.
hibernate
.annotations package包含了这些
注解
。 实体 org.
hibernate
.annotations.Entity 定义了
Hibernate
实体需要的信息。 • mutable: whether this entity is mutable or not 此实体是否可变 • dynamicInsert: allow dynamic SQL for inserts 用动态SQL新增 • dynamicUpdate: allow dynamic SQL for updates 用动态SQL更新 • selectBeforeUpdate: Specifies that
Hibernate
should never perform an SQL UPDATE unless it is certain that an object is actually modified.指明
Hibernate
从不运行SQL Update,除非能确定对象已经被修改 • polymorphism: whether the entity polymorphism is of PolymorphismType.IMPLICIT (default) or PolymorphismType.EXPLICIT 指出实体多态是 PolymorphismType.IMPLICIT(默认)还是PolymorphismType.EXPLICIT • optimisticLock: optimistic locking strategy (OptimisticLockType.VERSION, OptimisticLockType.NONE, OptimisticLockType.DIRTY or OptimisticLockType.ALL) 乐观锁策略 标识符 @org.
hibernate
.annotations.GenericGenerator和@org.
hibernate
.annotations.GenericGenerators允许你定义
hibernate
特有的标识符。 @
Id
@GeneratedValue(generator="system-uu
id
") @GenericGenerator(name="system-uu
id
", strategy = "uu
id
") public String get
Id
() { @
Id
@GeneratedValue(generator="hibseq") @GenericGenerator(name="hibseq", strategy = "seqhilo", parameters = { @Parameter(name="max_lo", value = "5"), @Parameter(name="sequence", value="heybabyhey") } ) public Integer get
Id
() { 新例子 @GenericGenerators( { @GenericGenerator( name="hibseq", strategy = "seqhilo", parameters = { @Parameter(name="max_lo", value = "5"), @Parameter(name="sequence", value="heybabyhey") } ), @GenericGenerator(...) } ) 自然
ID
用 @Natural
Id
注解
标识 公式 让数据库而不是JVM进行计算。 @Formula("obj_length * obj_height * obj_w
id
th") public long getObjectVolume() 索引 通过在列属性(property)上使用@Index
注解
,可以指定特定列的索引,columnNames属性(attribute)将随之被忽略。 @Column(secondaryTable="Cat1") @Index(name="story1index") public String getStoryPart1() { return storyPart1; } 辨别符 @Entity @DiscriminatorFormula("case when forest_type is null then 0 else forest_type end") public
class
Forest { ... } 过滤 查询 ... • 其中一个实体通过外键关联到另一个实体的主键。注:一对一,则外键必须为唯一约束。 @Entity public
class
Customer implements Serializable { @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name="passport_fk") public Passport getPassport() { ... } @Entity public
class
Passport implements Serializable { @OneToOne(mappedBy = "passport") public Customer getOwner() { ... } 通过@JoinColumn
注解
定义一对一的关联关系。如果没有@JoinColumn
注解
,则系统自动处理,在主表中将创建连接列,列名为:主题的关联属性名 + 下划线 + 被关联端的主键列名。上例为 passport_
id
, 因为Customer 中关联属性为 passport, Passport 的主键为
id
. • 通过关联表来保存两个实体之间的关联关系。注:一对一,则关联表每个外键都必须是唯一约束。 @Entity public
class
Customer implements Serializable { @OneToOne(cascade = CascadeType.ALL) @JoinTable(name = "CustomerPassports", joinColumns = @JoinColumn(name="customer_fk"), inverseJoinColumns = @JoinColumn(name="passport_fk") ) public Passport getPassport() { ... } @Entity public
class
Passport implements Serializable { @OneToOne(mappedBy = "passport") public Customer getOwner() { ... } Customer 通过 CustomerPassports 关联表和 Passport 关联。该关联表通过 passport_fk 外键指向 Passport 表,该信心定义为 inverseJoinColumns 的属性值。 通过 customer_fk 外键指向 Customer 表,该信息定义为 joinColumns 属性值。 本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tangcx/archive/2009/05/05/4152320.aspx
最全
Hibernate
参考文档
1. 在Tomcat中快速上手 1.1. 开始
Hibernate
之旅 1.2. 第一个持久化类 1.3. 映射cat 1.4. 与Cat同乐 1.5. 结语 2. 架构(Architecture) 2.1. 概况(Overview) 2.2. 实例状态 2.3. JMX整合 2.4. 对JCA的支持 3. 配置 3.1. 可编程的配置方式 3.2. 获得SessionFactory 3.3. JDBC连接 3.4. 可选的配置属性 3.4.1. SQL方言 3.4.2. 外连接抓取(Outer Join Fetching) 3.4.3. 二进制流 (Binary Streams) 3.4.4. 二级缓存与查询缓存 3.4.5. 查询语言中的替换 3.4.6.
Hibernate
的统计(statistics)机制 3.5. 日志 3.6. 实现NamingStrategy 3.7. XML配置文件 3.8. J2EE应用程序服务器的集成 3.8.1. 事务策略配置 3.8.2. JNDI绑定的SessionFactory 3.8.3. JTA和Session的自动绑定 3.8.4. JMX部署 4. 持久化类(Persistent
Class
es) 4.1. 一个简单的POJO例子 4.1.1. 为持久化字段声明访问器(accessors)和是否可变的标志(mutators) 4.1.2. 实现一个默认的(即无参数的)构造方法(constructor) 4.1.3. 提供一个标识属性(
id
entifier property)(可选) 4.1.4. 使用非final的类 (可选) 4.2. 实现继承(Inheritance) 4.3. 实现equals()和hashCode() 4.4. 动态模型(Dynamic models) 5. 对象/关系数据库映射基础(Basic O/R Mapping) 5.1. 映射定义(Mapping declaration) 5.1.1. Doctype 5.1.2.
hibernate
-mapping 5.1.3.
class
5.1.4.
id
5.1.4.1. Generator 5.1.4.2. 高/低位算法(Hi/Lo Algorithm) 5.1.4.3. UU
ID
算法(UU
ID
Algorithm ) 5.1.4.4. 标识字段和序列(
Id
entity columns and Sequences) 5.1.4.5. 程序分配的标识符(Assigned
Id
entifiers) 5.1.4.6. 触发器实现的主键生成器(Primary keys assigned by triggers) 5.1.5. composite-
id
5.1.6. 鉴别器(discriminator) 5.1.7. 版本(version)(可选) 5.1.8. timestamp (optional) 5.1.9. property 5.1.10. 多对一(many-to-one) 5.1.11. 一对一 5.1.12. 组件(component), 动态组件(dynamic-component) 5.1.13. properties 5.1.14. 子类(sub
class
) 5.1.15. 连接的子类(joined-sub
class
) 5.1.16. 联合子类(union-sub
class
) 5.1.17. 连接(join) 5.1.18. 键(key) 5.1.19. 字段和规则元素(column and formula elements) 5.1.20. 引用(import) 5.1.21. any 5.2.
Hibernate
的类型 5.2.1. 实体(Entities)和值(values) 5.2.2. 基本值类型 5.2.3. 自定义值类型 5.3. SQL中引号包围的标识符 5.4. 其他元数据(Metadata) 5.4.1. 使用 XDoclet 标记 5.4.2. 使用 JDK 5.0 的
注解
(Annotation) 6. 集合类(Collections)映射 6.1. 持久化集合类(Persistent collections) 6.2. 集合映射( Collection mappings ) 6.2.1. 集合外键(Collection foreign keys) 6.2.2. 集合元素(Collection elements) 6.2.3. 索引集合类(Indexed collections) 6.2.4. 值集合于多对多关联(Collections of values and many-to-many associations) 6.2.5. 一对多关联(One-to-many Associations) 6.3. 高级集合映射(Advanced collection mappings) 6.3.1. 有序集合(Sorted collections) 6.3.2. 双向关联(B
id
irectional associations) 6.3.3. 三重关联(Ternary associations) 6.3.4. 使用<
id
bag> 6.4. 集合例子(Collection example) 7. 关联关系映射 7.1. 介绍 7.2. 单向关联(Un
id
irectional associations) 7.2.1. 多对一(many to one) 7.2.2. 一对一(one to one) 7.2.3. 一对多(one to many) 7.3. 使用连接表的单向关联(Un
id
irectional associations with join tables) 7.3.1. 一对多(one to many) 7.3.2. 多对一(many to one) 7.3.3. 一对一(one to one) 7.3.4. 多对多(many to many) 7.4. 双向关联(B
id
irectional associations) 7.4.1. 一对多(one to many) / 多对一(many to one) 7.4.2. 一对一(one to one) 7.5. 使用连接表的双向关联(B
id
irectional associations with join tables) 7.5.1. 一对多(one to many) /多对一( many to one) 7.5.2. 一对一(one to one) 7.5.3. 多对多(many to many) 8. 组件(Component)映射 8.1. 依赖对象(Dependent objects) 8.2. 在集合中出现的依赖对象 8.3. 组件作为Map的索引(Components as Map indices ) 8.4. 组件作为联合标识符(Components as composite
id
entifiers) 8.5. 动态组件 (Dynamic components) 9. 继承映射(Inheritance Mappings) 9.1. 三种策略 9.1.1. 每个类分层结构一张表(Table per
class
hierarchy) 9.1.2. 每个子类一张表(Table per sub
class
) 9.1.3. 每个子类一张表(Table per sub
class
),使用辨别标志(Discriminator) 9.1.4. 混合使用“每个类分层结构一张表”和“每个子类一张表” 9.1.5. 每个具体类一张表(Table per concrete
class
) 9.1.6. Table per concrete
class
, using implicit polymorphism 9.1.7. 隐式多态和其他继承映射混合使用 9.2. 限制 10. 与对象共事 10.1.
Hibernate
对象状态(object states) 10.2. 使对象持久化 10.3. 装载对象 10.4. 查询 10.4.1. 执行查询 10.4.1.1. 迭代式获取结果(Iterating results) 10.4.1.2. 返回元组(tuples)的查询 10.4.1.3. 标量(Scalar)结果 10.4.1.4. 绑定参数 10.4.1.5. 分页 10.4.1.6. 可滚动遍历(Scrollable iteration) 10.4.1.7. 外置命名查询(Externalizing named queries) 10.4.2. 过滤集合 10.4.3. 条件查询(Criteria queries) 10.4.4. 使用原生SQL的查询 10.5. 修改持久对象 10.6. 修改脱管(Detached)对象 10.7. 自动状态检测 10.8. 删除持久对象 10.9. 在两个不同数据库间复制对象 10.10. Session刷出(flush) 10.11. 传播性持久化(transitive persistence) 10.12. 使用元数据 11. 事务和并发 11.1. Session和事务范围(transaction scopes) 11.1.1. 操作单元(Unit of work) 11.1.2. 应用程序事务(Application transactions) 11.1.3. 关注对象标识(Cons
id
ering object
id
entity) 11.1.4. 常见问题 11.2. 数据库事务声明 11.2.1. 非托管环境 11.2.2. 使用JTA 11.2.3. 异常处理 11.3. 乐观并发控制(Optimistic concurrency control) 11.3.1. 应用程序级别的版本检查(Application version checking) 11.3.2. 长生命周期session和自动版本化 11.3.3. 脱管对象(deatched object)和自动版本化 11.3.4. 定制自动版本化行为 11.4. 悲观锁定(Pessimistic Locking) 12. 拦截器与事件(Interceptors and events) 12.1. 拦截器(Interceptors) 12.2. 事件系统(Event system) 12.3.
Hibernate
的声明式安全机制 13. 批量处理(Batch processing) 13.1. 批量插入(Batch inserts) 13.2. 批量更新(Batch updates) 13.3. 大批量更新/删除(Bulk update/delete) 14. HQL:
Hibernate
查询语言 14.1. 大小写敏感性问题 14.2. from子句 14.3. 关联(Association)与连接(Join) 14.4. select子句 14.5. 聚集函数 14.6. 多态查询 14.7. where子句 14.8. 表达式 14.9. order by子句 14.10. group by子句 14.11. 子查询 14.12. HQL示例 14.13. 批量的UPDATE & DELETE语句 14.14. 小技巧 & 小窍门 15. 条件查询(Criteria Queries) 15.1. 创建一个Criteria 实例 15.2. 限制结果集内容 15.3. 结果集排序 15.4. 关联 15.5. 动态关联抓取 15.6. 查询示例 15.7. 投影(Projections)、聚合(aggregation)和分组(grouping) 15.8. 离线(detached)查询和子查询 16. Native SQL查询 16.1. 创建一个基于SQL的Query 16.2. 别名和属性引用 16.3. 命名SQL查询 16.3.1. 使用return-property来明确地指定字段/别名 16.3.2. 使用存储过程来查询 16.3.2.1. 使用存储过程的规则和限制 16.4. 定制SQL用来create,update和delete 16.5. 定制装载SQL 17. 过滤数据 17.1.
Hibernate
过滤器(filters) 18. XML映射 18.1. 用XML数据进行工作 18.1.1. 指定同时映射XML和类 18.1.2. 只定义XML映射 18.2. XML映射元数据 18.3. 操作XML数据 19. 提升性能 19.1. 抓取策略(Fetching strategies) 19.1.1. 调整抓取策略(Tuning fetch strategies) 19.1.2. 单端关联代理(Single-ended association proxies) 19.1.3. 实例化集合和代理(Initializing collections and proxies) 19.1.4. 使用批量抓取(Using batch fetching) 19.1.5. 使用子查询抓取(Using subselect fetching) 19.1.6. 使用延迟属性抓取(Using lazy property fetching) 19.2. 二级缓存(The Second Level Cache) 19.2.1. 缓存映射(Cache mappings) 19.2.2. 策略:只读缓存(Strategy: read only) 19.2.3. 策略:读/写缓存(Strategy: read/write) 19.2.4. 策略:非严格读/写缓存(Strategy: nonstrict read/write) 19.2.5. 策略:事务缓存(transactional) 19.3. 管理缓存(Managing the caches) 19.4. 查询缓存(The Query Cache) 19.5. 理解集合性能(Understanding Collection performance) 19.5.1. 分类(Taxonomy) 19.5.2. Lists, maps 和sets用于更新效率最高 19.5.3. Bag和list是反向集合类中效率最高的 19.5.4. 一次性删除(One shot delete) 19.6. 监测性能(Monitoring performance) 19.6.1. 监测SessionFactory 19.6.2. 数据记录(Metrics) 20. 工具箱指南 20.1. Schema自动生成(Automatic schema generation) 20.1.1. 对schema定制化(Customizing the schema) 20.1.2. 运行该工具 20.1.3. 属性(Properties) 20.1.4. 使用Ant(Using Ant) 20.1.5. 对schema的增量更新(Incremental schema updates) 20.1.6. 用Ant来增量更新schema(Using Ant for incremental schema updates) 21. 示例:父子关系(Parent Child Relationships) 21.1. 关于collections 21.2. 双向的一对多关系(B
id
irectional one-to-many) 21.3. 级联生命周期(Cascading lifecycle) 21.4. 级联与未保存值(Cascades and unsaved-value) 21.5. 结论 22. 示例:Weblog 应用程序 22.1. 持久化类 22.2.
Hibernate
映射 22.3.
Hibernate
代码 23. 示例:复杂映射实例 23.1. Employer(雇主)/Employee(雇员) 23.2. Author(作家)/Work(作品) 23.3. Customer(客户)/Order(订单)/Product(产品) 23.4. 杂例 23.4.1. "Typed" one-to-one association 23.4.2. Composite key example 23.4.3. Content based discrimination 23.4.4. Associations on alternate keys 24. 最佳实践(Best Practices)
Hibernate
中文 html 帮助文档
目录 前言 1. 翻译说明 2. 版权声明 1.
Hibernate
入门 1.1. 前言 1.2. 第一部分 - 第一个
Hibernate
应用程序 1.2.1. 第一个
class
1.2.2. 映射文件 1.2.3.
Hibernate
配置 1.2.4. 用Ant构建 1.2.5. 启动和辅助类 1.2.6. 加载并存储对象 1.3. 第二部分 - 关联映射 1.3.1. 映射Person类 1.3.2. 单向Set-based的关联 1.3.3. 使关联工作 1.3.4. 值类型的集合 1.3.5. 双向关联 1.3.6. 使双向连起来 1.4. 第三部分 - EventManager web应用程序 1.4.1. 编写基本的servlet 1.4.2. 处理与渲染 1.4.3. 部署与测试 1.5. 总结 2. 体系结构(Architecture) 2.1. 概况(Overview) 2.2. 实例状态 2.3. JMX整合 2.4. 对JCA的支持 2.5. 上下文相关的(Contextual)Session 3. 配置 3.1. 可编程的配置方式 3.2. 获得SessionFactory 3.3. JDBC连接 3.4. 可选的配置属性 3.4.1. SQL方言 3.4.2. 外连接抓取(Outer Join Fetching) 3.4.3. 二进制流 (Binary Streams) 3.4.4. 二级缓存与查询缓存 3.4.5. 查询语言中的替换 3.4.6.
Hibernate
的统计(statistics)机制 3.5. 日志 3.6. 实现NamingStrategy 3.7. XML配置文件 3.8. J2EE应用程序服务器的集成 3.8.1. 事务策略配置 3.8.2. JNDI绑定的SessionFactory 3.8.3. 在JTA环境下使用Current Session context (当前session上下文)管理 3.8.4. JMX部署 4. 持久化类(Persistent
Class
es) 4.1. 一个简单的POJO例子 4.1.1. 实现一个默认的(即无参数的)构造方法(constructor) 4.1.2. 提供一个标识属性(
id
entifier property)(可选) 4.1.3. 使用非final的类 (可选) 4.1.4. 为持久化字段声明访问器(accessors)和是否可变的标志(mutators)(可选) 4.2. 实现继承(Inheritance) 4.3. 实现equals()和hashCode() 4.4. 动态模型(Dynamic models) 4.5. 元组片断映射(Tuplizers) 5. 对象/关系数据库映射基础(Basic O/R Mapping) 5.1. 映射定义(Mapping declaration) 5.1.1. Doctype 5.1.1.1. EntityResolver 5.1.2.
hibernate
-mapping 5.1.3.
class
5.1.4.
id
5.1.4.1. Generator 5.1.4.2. 高/低位算法(Hi/Lo Algorithm) 5.1.4.3. UU
ID
算法(UU
ID
Algorithm ) 5.1.4.4. 标识字段和序列(
Id
entity columns and Sequences) 5.1.4.5. 程序分配的标识符(Assigned
Id
entifiers) 5.1.4.6. 触发器实现的主键生成器(Primary keys assigned by triggers) 5.1.5. composite-
id
5.1.6. 鉴别器(discriminator) 5.1.7. 版本(version)(可选) 5.1.8. timestamp (可选) 5.1.9. property 5.1.10. 多对一(many-to-one) 5.1.11. 一对一 5.1.12. 自然
ID
(natural-
id
) 5.1.13. 组件(component), 动态组件(dynamic-component) 5.1.14. properties 5.1.15. 子类(sub
class
) 5.1.16. 连接的子类(joined-sub
class
) 5.1.17. 联合子类(union-sub
class
) 5.1.18. 连接(join) 5.1.19. 键(key) 5.1.20. 字段和规则元素(column and formula elements) 5.1.21. 引用(import) 5.1.22. any 5.2.
Hibernate
的类型 5.2.1. 实体(Entities)和值(values) 5.2.2. 基本值类型 5.2.3. 自定义值类型 5.3. 多次映射同一个类 5.4. SQL中引号包围的标识符 5.5. 其他元数据(Metadata) 5.5.1. 使用 XDoclet 标记 5.5.2. 使用 JDK 5.0 的
注解
(Annotation) 5.6. 数据库生成属性(Generated Properties) 5.7. 辅助数据库对象(Auxiliary Database Objects) 6. 集合类(Collections)映射 6.1. 持久化集合类(Persistent collections) 6.2. 集合映射( Collection mappings ) 6.2.1. 集合外键(Collection foreign keys) 6.2.2. 集合元素(Collection elements) 6.2.3. 索引集合类(Indexed collections) 6.2.4. 值集合于多对多关联(Collections of values and many-to-many associations) 6.2.5. 一对多关联(One-to-many Associations) 6.3. 高级集合映射(Advanced collection mappings) 6.3.1. 有序集合(Sorted collections) 6.3.2. 双向关联(B
id
irectional associations) 6.3.3. 双向关联,涉及有序集合类 6.3.4. 三重关联(Ternary associations) 6.3.5. 使用<
id
bag> 6.4. 集合例子(Collection example) 7. 关联关系映射 7.1. 介绍 7.2. 单向关联(Un
id
irectional associations) 7.2.1. 多对一(many to one) 7.2.2. 一对一(one to one) 7.2.3. 一对多(one to many) 7.3. 使用连接表的单向关联(Un
id
irectional associations with join tables) 7.3.1. 一对多(one to many) 7.3.2. 多对一(many to one) 7.3.3. 一对一(one to one) 7.3.4. 多对多(many to many) 7.4. 双向关联(B
id
irectional associations) 7.4.1. 一对多(one to many) / 多对一(many to one) 7.4.2. 一对一(one to one) 7.5. 使用连接表的双向关联(B
id
irectional associations with join tables) 7.5.1. 一对多(one to many) /多对一( many to one) 7.5.2. 一对一(one to one) 7.5.3. 多对多(many to many) 7.6. 更复杂的关联映射 8. 组件(Component)映射 8.1. 依赖对象(Dependent objects) 8.2. 在集合中出现的依赖对象 (Collections of dependent objects) 8.3. 组件作为Map的索引(Components as Map indices ) 8.4. 组件作为联合标识符(Components as composite
id
entifiers) 8.5. 动态组件 (Dynamic components) 9. 继承映射(Inheritance Mappings) 9.1. 三种策略 9.1.1. 每个类分层结构一张表(Table per
class
hierarchy) 9.1.2. 每个子类一张表(Table per sub
class
) 9.1.3. 每个子类一张表(Table per sub
class
),使用辨别标志(Discriminator) 9.1.4. 混合使用“每个类分层结构一张表”和“每个子类一张表” 9.1.5. 每个具体类一张表(Table per concrete
class
) 9.1.6. Table per concrete
class
, using implicit polymorphism 9.1.7. 隐式多态和其他继承映射混合使用 9.2. 限制 10. 与对象共事 10.1.
Hibernate
对象状态(object states) 10.2. 使对象持久化 10.3. 装载对象 10.4. 查询 10.4.1. 执行查询 10.4.1.1. 迭代式获取结果(Iterating results) 10.4.1.2. 返回元组(tuples)的查询 10.4.1.3. 标量(Scalar)结果 10.4.1.4. 绑定参数 10.4.1.5. 分页 10.4.1.6. 可滚动遍历(Scrollable iteration) 10.4.1.7. 外置命名查询(Externalizing named queries) 10.4.2. 过滤集合 10.4.3. 条件查询(Criteria queries) 10.4.4. 使用原生SQL的查询 10.5. 修改持久对象 10.6. 修改脱管(Detached)对象 10.7. 自动状态检测 10.8. 删除持久对象 10.9. 在两个不同数据库间复制对象 10.10. Session刷出(flush) 10.11. 传播性持久化(transitive persistence) 10.12. 使用元数据 11. 事务和并发 11.1. Session和事务范围(transaction scope) 11.1.1. 操作单元(Unit of work) 11.1.2. 长对话 11.1.3. 关注对象标识(Cons
id
ering object
id
entity) 11.1.4. 常见问题 11.2. 数据库事务声明 11.2.1. 非托管环境 11.2.2. 使用JTA 11.2.3. 异常处理 11.2.4. 事务超时 11.3. 乐观并发控制(Optimistic concurrency control) 11.3.1. 应用程序级别的版本检查(Application version checking) 11.3.2. 扩展周期的session和自动版本化 11.3.3. 脱管对象(deatched object)和自动版本化 11.3.4. 定制自动版本化行为 11.4. 悲观锁定(Pessimistic Locking) 11.5. 连接释放模式(Connection Release Modes) 12. 拦截器与事件(Interceptors and events) 12.1. 拦截器(Interceptors) 12.2. 事件系统(Event system) 12.3.
Hibernate
的声明式安全机制 13. 批量处理(Batch processing) 13.1. 批量插入(Batch inserts) 13.2. 批量更新(Batch updates) 13.3. StatelessSession (无状态session)接口 13.4. DML(数据操作语言)风格的操作(DML-style operations) 14. HQL:
Hibernate
查询语言 14.1. 大小写敏感性问题 14.2. from子句 14.3. 关联(Association)与连接(Join) 14.4. join 语法的形式 14.5. select子句 14.6. 聚集函数 14.7. 多态查询 14.8. where子句 14.9. 表达式 14.10. order by子句 14.11. group by子句 14.12. 子查询 14.13. HQL示例 14.14. 批量的UPDATE和DELETE 14.15. 小技巧 & 小窍门 15. 条件查询(Criteria Queries) 15.1. 创建一个Criteria 实例 15.2. 限制结果集内容 15.3. 结果集排序 15.4. 关联 15.5. 动态关联抓取 15.6. 查询示例 15.7. 投影(Projections)、聚合(aggregation)和分组(grouping) 15.8. 离线(detached)查询和子查询 15.9. 根据自然标识查询(Queries by natural
id
entifier) 16. Native SQL查询 16.1. 使用SQLQuery 16.1.1. 标量查询(Scalar queries) 16.1.2. 实体查询(Entity queries) 16.1.3. 处理关联和集合类(Handling associations and collections) 16.1.4. 返回多个实体(Returning multiple entities) 16.1.4.1. 别名和属性引用(Alias and property references) 16.1.5. 返回非受管实体(Returning non-managed entities) 16.1.6. 处理继承(Handling inheritance) 16.1.7. 参数(Parameters) 16.2. 命名SQL查询 16.2.1. 使用return-property来明确地指定字段/别名 16.2.2. 使用存储过程来查询 16.2.2.1. 使用存储过程的规则和限制 16.3. 定制SQL用来create,update和delete 16.4. 定制装载SQL 17. 过滤数据 17.1.
Hibernate
过滤器(filters) 18. XML映射 18.1. 用XML数据进行工作 18.1.1. 指定同时映射XML和类 18.1.2. 只定义XML映射 18.2. XML映射元数据 18.3. 操作XML数据 19. 提升性能 19.1. 抓取策略(Fetching strategies) 19.1.1. 操作延迟加载的关联 19.1.2. 调整抓取策略(Tuning fetch strategies) 19.1.3. 单端关联代理(Single-ended association proxies) 19.1.4. 实例化集合和代理(Initializing collections and proxies) 19.1.5. 使用批量抓取(Using batch fetching) 19.1.6. 使用子查询抓取(Using subselect fetching) 19.1.7. 使用延迟属性抓取(Using lazy property fetching) 19.2. 二级缓存(The Second Level Cache) 19.2.1. 缓存映射(Cache mappings) 19.2.2. 策略:只读缓存(Strategy: read only) 19.2.3. 策略:读/写缓存(Strategy: read/write) 19.2.4. 策略:非严格读/写缓存(Strategy: nonstrict read/write) 19.2.5. 策略:事务缓存(transactional) 19.3. 管理缓存(Managing the caches) 19.4. 查询缓存(The Query Cache) 19.5. 理解集合性能(Understanding Collection performance) 19.5.1. 分类(Taxonomy) 19.5.2. Lists, maps 和sets用于更新效率最高 19.5.3. Bag和list是反向集合类中效率最高的 19.5.4. 一次性删除(One shot delete) 19.6. 监测性能(Monitoring performance) 19.6.1. 监测SessionFactory 19.6.2. 数据记录(Metrics) 20. 工具箱指南 20.1. Schema自动生成(Automatic schema generation) 20.1.1. 对schema定制化(Customizing the schema) 20.1.2. 运行该工具 20.1.3. 属性(Properties) 20.1.4. 使用Ant(Using Ant) 20.1.5. 对schema的增量更新(Incremental schema updates) 20.1.6. 用Ant来增量更新schema(Using Ant for incremental schema updates) 20.1.7. Schema 校验 20.1.8. 使用Ant进行schema校验 21. 示例:父子关系(Parent Child Relationships) 21.1. 关于collections需要注意的一点 21.2. 双向的一对多关系(B
id
irectional one-to-many) 21.3. 级联生命周期(Cascading lifecycle) 21.4. 级联与未保存值(Cascades and unsaved-value) 21.5. 结论 22. 示例:Weblog 应用程序 22.1. 持久化类 22.2.
Hibernate
映射 22.3.
Hibernate
代码 23. 示例:复杂映射实例 23.1. Employer(雇主)/Employee(雇员) 23.2. Author(作家)/Work(作品) 23.3. Customer(客户)/Order(订单)/Product(产品) 23.4. 杂例 23.4.1. "Typed" one-to-one association 23.4.2. Composite key example 23.4.3. 共有组合键属性的多对多(Many-to-many with shared composite key attribute) 23.4.4. Content based discrimination 23.4.5. Associations on alternate keys 24. 最佳实践(Best Practices)
hibernate
体系结构与配置 参考文档(html)
1.
Hibernate
入门 1.1. 前言 1.2. 第一部分 - 第一个
Hibernate
应用程序 1.2.1. 第一个
class
1.2.2. 映射文件 1.2.3.
Hibernate
配置 1.2.4. 用Ant构建 1.2.5. 启动和辅助类 1.2.6. 加载并存储对象 1.3. 第二部分 - 关联映射 1.3.1. 映射Person类 1.3.2. 单向Set-based的关联 1.3.3. 使关联工作 1.3.4. 值类型的集合 1.3.5. 双向关联 1.3.6. 使双向连起来 1.4. 第三部分 - EventManager web应用程序 1.4.1. 编写基本的servlet 1.4.2. 处理与渲染 1.4.3. 部署与测试 1.5. 总结 2. 体系结构(Architecture) 2.1. 概况(Overview) 2.2. 实例状态 2.3. JMX整合 2.4. 对JCA的支持 2.5. 上下文相关的(Contextual)Session 3. 配置 3.1. 可编程的配置方式 3.2. 获得SessionFactory 3.3. JDBC连接 3.4. 可选的配置属性 3.4.1. SQL方言 3.4.2. 外连接抓取(Outer Join Fetching) 3.4.3. 二进制流 (Binary Streams) 3.4.4. 二级缓存与查询缓存 3.4.5. 查询语言中的替换 3.4.6.
Hibernate
的统计(statistics)机制 3.5. 日志 3.6. 实现NamingStrategy 3.7. XML配置文件 3.8. J2EE应用程序服务器的集成 3.8.1. 事务策略配置 3.8.2. JNDI绑定的SessionFactory 3.8.3. 在JTA环境下使用Current Session context (当前session上下文)管理 3.8.4. JMX部署 4. 持久化类(Persistent
Class
es) 4.1. 一个简单的POJO例子 4.1.1. 实现一个默认的(即无参数的)构造方法(constructor) 4.1.2. 提供一个标识属性(
id
entifier property)(可选) 4.1.3. 使用非final的类 (可选) 4.1.4. 为持久化字段声明访问器(accessors)和是否可变的标志(mutators)(可选) 4.2. 实现继承(Inheritance) 4.3. 实现equals()和hashCode() 4.4. 动态模型(Dynamic models) 4.5. 元组片断映射(Tuplizers) 5. 对象/关系数据库映射基础(Basic O/R Mapping) 5.1. 映射定义(Mapping declaration) 5.1.1. Doctype 5.1.2.
hibernate
-mapping 5.1.3.
class
5.1.4.
id
5.1.4.1. Generator 5.1.4.2. 高/低位算法(Hi/Lo Algorithm) 5.1.4.3. UU
ID
算法(UU
ID
Algorithm ) 5.1.4.4. 标识字段和序列(
Id
entity columns and Sequences) 5.1.4.5. 程序分配的标识符(Assigned
Id
entifiers) 5.1.4.6. 触发器实现的主键生成器(Primary keys assigned by triggers) 5.1.5. composite-
id
5.1.6. 鉴别器(discriminator) 5.1.7. 版本(version)(可选) 5.1.8. timestamp (可选) 5.1.9. property 5.1.10. 多对一(many-to-one) 5.1.11. 一对一 5.1.12. 自然
ID
(natural-
id
) 5.1.13. 组件(component), 动态组件(dynamic-component) 5.1.14. properties 5.1.15. 子类(sub
class
) 5.1.16. 连接的子类(joined-sub
class
) 5.1.17. 联合子类(union-sub
class
) 5.1.18. 连接(join) 5.1.19. 键(key) 5.1.20. 字段和规则元素(column and formula elements) 5.1.21. 引用(import) 5.1.22. any 5.2.
Hibernate
的类型 5.2.1. 实体(Entities)和值(values) 5.2.2. 基本值类型 5.2.3. 自定义值类型 5.3. 多次映射同一个类 5.4. SQL中引号包围的标识符 5.5. 其他元数据(Metadata) 5.5.1. 使用 XDoclet 标记 5.5.2. 使用 JDK 5.0 的
注解
(Annotation) 5.6. 数据库生成属性(Generated Properties) 5.7. 辅助数据库对象(Auxiliary Database Objects) 6. 集合类(Collections)映射 6.1. 持久化集合类(Persistent collections) 6.2. 集合映射( Collection mappings ) 6.2.1. 集合外键(Collection foreign keys) 6.2.2. 集合元素(Collection elements) 6.2.3. 索引集合类(Indexed collections) 6.2.4. 值集合于多对多关联(Collections of values and many-to-many associations) 6.2.5. 一对多关联(One-to-many Associations) 6.3. 高级集合映射(Advanced collection mappings) 6.3.1. 有序集合(Sorted collections) 6.3.2. 双向关联(B
id
irectional associations) 6.3.3. 双向关联,涉及有序集合类 6.3.4. 三重关联(Ternary associations) 6.3.5. 使用<
id
bag> 6.4. 集合例子(Collection example) 7. 关联关系映射 7.1. 介绍 7.2. 单向关联(Un
id
irectional associations) 7.2.1. 多对一(many to one) 7.2.2. 一对一(one to one) 7.2.3. 一对多(one to many) 7.3. 使用连接表的单向关联(Un
id
irectional associations with join tables) 7.3.1. 一对多(one to many) 7.3.2. 多对一(many to one) 7.3.3. 一对一(one to one) 7.3.4. 多对多(many to many) 7.4. 双向关联(B
id
irectional associations) 7.4.1. 一对多(one to many) / 多对一(many to one) 7.4.2. 一对一(one to one) 7.5. 使用连接表的双向关联(B
id
irectional associations with join tables) 7.5.1. 一对多(one to many) /多对一( many to one) 7.5.2. 一对一(one to one) 7.5.3. 多对多(many to many) 7.6. 更复杂的关联映射 8. 组件(Component)映射 8.1. 依赖对象(Dependent objects) 8.2. 在集合中出现的依赖对象 (Collections of dependent objects) 8.3. 组件作为Map的索引(Components as Map indices ) 8.4. 组件作为联合标识符(Components as composite
id
entifiers) 8.5. 动态组件 (Dynamic components) 9. 继承映射(Inheritance Mappings) 9.1. 三种策略 9.1.1. 每个类分层结构一张表(Table per
class
hierarchy) 9.1.2. 每个子类一张表(Table per sub
class
) 9.1.3. 每个子类一张表(Table per sub
class
),使用辨别标志(Discriminator) 9.1.4. 混合使用“每个类分层结构一张表”和“每个子类一张表” 9.1.5. 每个具体类一张表(Table per concrete
class
) 9.1.6. Table per concrete
class
, using implicit polymorphism 9.1.7. 隐式多态和其他继承映射混合使用 9.2. 限制 10. 与对象共事 10.1.
Hibernate
对象状态(object states) 10.2. 使对象持久化 10.3. 装载对象 10.4. 查询 10.4.1. 执行查询 10.4.1.1. 迭代式获取结果(Iterating results) 10.4.1.2. 返回元组(tuples)的查询 10.4.1.3. 标量(Scalar)结果 10.4.1.4. 绑定参数 10.4.1.5. 分页 10.4.1.6. 可滚动遍历(Scrollable iteration) 10.4.1.7. 外置命名查询(Externalizing named queries) 10.4.2. 过滤集合 10.4.3. 条件查询(Criteria queries) 10.4.4. 使用原生SQL的查询 10.5. 修改持久对象 10.6. 修改脱管(Detached)对象 10.7. 自动状态检测 10.8. 删除持久对象 10.9. 在两个不同数据库间复制对象 10.10. Session刷出(flush) 10.11. 传播性持久化(transitive persistence) 10.12. 使用元数据 11. 事务和并发 11.1. Session和事务范围(transaction scope) 11.1.1. 操作单元(Unit of work) 11.1.2. 长对话 11.1.3. 关注对象标识(Cons
id
ering object
id
entity) 11.1.4. 常见问题 11.2. 数据库事务声明 11.2.1. 非托管环境 11.2.2. 使用JTA 11.2.3. 异常处理 11.2.4. 事务超时 11.3. 乐观并发控制(Optimistic concurrency control) 11.3.1. 应用程序级别的版本检查(Application version checking) 11.3.2. 扩展周期的session和自动版本化 11.3.3. 脱管对象(deatched object)和自动版本化 11.3.4. 定制自动版本化行为 11.4. 悲观锁定(Pessimistic Locking) 11.5. 连接释放模式(Connection Release Modes) 12. 拦截器与事件(Interceptors and events) 12.1. 拦截器(Interceptors) 12.2. 事件系统(Event system) 12.3.
Hibernate
的声明式安全机制 13. 批量处理(Batch processing) 13.1. 批量插入(Batch inserts) 13.2. 批量更新(Batch updates) 13.3. StatelessSession (无状态session)接口 13.4. DML(数据操作语言)风格的操作(DML-style operations) 14. HQL:
Hibernate
查询语言 14.1. 大小写敏感性问题 14.2. from子句 14.3. 关联(Association)与连接(Join) 14.4. join 语法的形式 14.5. select子句 14.6. 聚集函数 14.7. 多态查询 14.8. where子句 14.9. 表达式 14.10. order by子句 14.11. group by子句 14.12. 子查询 14.13. HQL示例 14.14. 批量的UPDATE和DELETE 14.15. 小技巧 & 小窍门 15. 条件查询(Criteria Queries) 15.1. 创建一个Criteria 实例 15.2. 限制结果集内容 15.3. 结果集排序 15.4. 关联 15.5. 动态关联抓取 15.6. 查询示例 15.7. 投影(Projections)、聚合(aggregation)和分组(grouping) 15.8. 离线(detached)查询和子查询 15.9. 根据自然标识查询(Queries by natural
id
entifier) 16. Native SQL查询 16.1. 使用SQLQuery 16.2. 别名和属性引用 16.3. 命名SQL查询 16.3.1. 使用return-property来明确地指定字段/别名 16.3.2. 使用存储过程来查询 16.3.2.1. 使用存储过程的规则和限制 16.4. 定制SQL用来create,update和delete 16.5. 定制装载SQL 17. 过滤数据 17.1.
Hibernate
过滤器(filters) 18. XML映射 18.1. 用XML数据进行工作 18.1.1. 指定同时映射XML和类 18.1.2. 只定义XML映射 18.2. XML映射元数据 18.3. 操作XML数据 19. 提升性能 19.1. 抓取策略(Fetching strategies) 19.1.1. 操作延迟加载的关联 19.1.2. 调整抓取策略(Tuning fetch strategies) 19.1.3. 单端关联代理(Single-ended association proxies) 19.1.4. 实例化集合和代理(Initializing collections and proxies) 19.1.5. 使用批量抓取(Using batch fetching) 19.1.6. 使用子查询抓取(Using subselect fetching) 19.1.7. 使用延迟属性抓取(Using lazy property fetching) 19.2. 二级缓存(The Second Level Cache) 19.2.1. 缓存映射(Cache mappings) 19.2.2. 策略:只读缓存(Strategy: read only) 19.2.3. 策略:读/写缓存(Strategy: read/write) 19.2.4. 策略:非严格读/写缓存(Strategy: nonstrict read/write) 19.2.5. 策略:事务缓存(transactional) 19.3. 管理缓存(Managing the caches) 19.4. 查询缓存(The Query Cache) 19.5. 理解集合性能(Understanding Collection performance) 19.5.1. 分类(Taxonomy) 19.5.2. Lists, maps 和sets用于更新效率最高 19.5.3. Bag和list是反向集合类中效率最高的 19.5.4. 一次性删除(One shot delete) 19.6. 监测性能(Monitoring performance) 19.6.1. 监测SessionFactory 19.6.2. 数据记录(Metrics) 20. 工具箱指南 20.1. Schema自动生成(Automatic schema generation) 20.1.1. 对schema定制化(Customizing the schema) 20.1.2. 运行该工具 20.1.3. 属性(Properties) 20.1.4. 使用Ant(Using Ant) 20.1.5. 对schema的增量更新(Incremental schema updates) 20.1.6. 用Ant来增量更新schema(Using Ant for incremental schema updates) 20.1.7. Schema 校验 20.1.8. 使用Ant进行schema校验 21. 示例:父子关系(Parent Child Relationships) 21.1. 关于collections需要注意的一点 21.2. 双向的一对多关系(B
id
irectional one-to-many) 21.3. 级联生命周期(Cascading lifecycle) 21.4. 级联与未保存值(Cascades and unsaved-value) 21.5. 结论 22. 示例:Weblog 应用程序 22.1. 持久化类 22.2.
Hibernate
映射 22.3.
Hibernate
代码 23. 示例:复杂映射实例 23.1. Employer(雇主)/Employee(雇员) 23.2. Author(作家)/Work(作品) 23.3. Customer(客户)/Order(订单)/Product(产品) 23.4. 杂例 23.4.1. "Typed" one-to-one association 23.4.2. Composite key example 23.4.3. 共有组合键属性的多对多(Many-to-many with shared composite key attribute) 23.4.4. Content based discrimination 23.4.5. Associations on alternate keys
Hibernate
教程
Hibernate
参考文档 目录 前言 1. 翻译说明 2. 版权声明 1. 在Tomcat中快速上手 1.1. 开始
Hibernate
之旅 1.2. 第一个持久化类 1.3. 映射cat 1.4. 与Cat同乐 1.5. 结语 2.
Hibernate
入门 2.1. 前言 2.2. 第一部分 - 第一个
Hibernate
程序 2.2.1. 第一个
class
2.2.2. 映射文件 2.2.3.
Hibernate
配置 2.2.4. 用Ant编译 2.2.5. 安装和帮助 2.2.6. 加载并存储对象 2.3. 第二部分 - 关联映射 2.3.1. 映射Person类 2.3.2. 一个单向的Set-based关联 2.3.3. 使关联工作 2.3.4. 值类型的集合 2.3.5. 双向关联 2.3.6. 使双向关联工作 2.4. 总结 3. 体系结构(Architecture) 3.1. 概况(Overview) 3.2. 实例状态 3.3. JMX整合 3.4. 对JCA的支持 4. 配置 4.1. 可编程的配置方式 4.2. 获得SessionFactory 4.3. JDBC连接 4.4. 可选的配置属性 4.4.1. SQL方言 4.4.2. 外连接抓取(Outer Join Fetching) 4.4.3. 二进制流 (Binary Streams) 4.4.4. 二级缓存与查询缓存 4.4.5. 查询语言中的替换 4.4.6.
Hibernate
的统计(statistics)机制 4.5. 日志 4.6. 实现NamingStrategy 4.7. XML配置文件 4.8. J2EE应用程序服务器的集成 4.8.1. 事务策略配置 4.8.2. JNDI绑定的SessionFactory 4.8.3. JTA和Session的自动绑定 4.8.4. JMX部署 5. 持久化类(Persistent
Class
es) 5.1. 一个简单的POJO例子 5.1.1. 为持久化字段声明访问器(accessors)和是否可变的标志(mutators) 5.1.2. 实现一个默认的(即无参数的)构造方法(constructor) 5.1.3. 提供一个标识属性(
id
entifier property)(可选) 5.1.4. 使用非final的类 (可选) 5.2. 实现继承(Inheritance) 5.3. 实现equals()和hashCode() 5.4. 动态模型(Dynamic models) 6. 对象/关系数据库映射基础(Basic O/R Mapping) 6.1. 映射定义(Mapping declaration) 6.1.1. Doctype 6.1.2.
hibernate
-mapping 6.1.3.
class
6.1.4.
id
6.1.4.1. Generator 6.1.4.2. 高/低位算法(Hi/Lo Algorithm) 6.1.4.3. UU
ID
算法(UU
ID
Algorithm ) 6.1.4.4. 标识字段和序列(
Id
entity columns and Sequences) 6.1.4.5. 程序分配的标识符(Assigned
Id
entifiers) 6.1.4.6. 触发器实现的主键生成器(Primary keys assigned by triggers) 6.1.5. composite-
id
6.1.6. 鉴别器(discriminator) 6.1.7. 版本(version)(可选) 6.1.8. timestamp (optional) 6.1.9. property 6.1.10. 多对一(many-to-one) 6.1.11. 一对一 6.1.12. 组件(component), 动态组件(dynamic-component) 6.1.13. properties 6.1.14. 子类(sub
class
) 6.1.15. 连接的子类(joined-sub
class
) 6.1.16. 联合子类(union-sub
class
) 6.1.17. 连接(join) 6.1.18. 键(key) 6.1.19. 字段和规则元素(column and formula elements) 6.1.20. 引用(import) 6.1.21. any 6.2.
Hibernate
的类型 6.2.1. 实体(Entities)和值(values) 6.2.2. 基本值类型 6.2.3. 自定义值类型 6.3. SQL中引号包围的标识符 6.4. 其他元数据(Metadata) 6.4.1. 使用 XDoclet 标记 6.4.2. 使用 JDK 5.0 的
注解
(Annotation) 7. 集合类(Collections)映射 7.1. 持久化集合类(Persistent collections) 7.2. 集合映射( Collection mappings ) 7.2.1. 集合外键(Collection foreign keys) 7.2.2. 集合元素(Collection elements) 7.2.3. 索引集合类(Indexed collections) 7.2.4. 值集合于多对多关联(Collections of values and many-to-many associations) 7.2.5. 一对多关联(One-to-many Associations) 7.3. 高级集合映射(Advanced collection mappings) 7.3.1. 有序集合(Sorted collections) 7.3.2. 双向关联(B
id
irectional associations) 7.3.3. 三重关联(Ternary associations) 7.3.4. 使用<
id
bag> 7.4. 集合例子(Collection example) 8. 关联关系映射 8.1. 介绍 8.2. 单向关联(Un
id
irectional associations) 8.2.1. 多对一(many to one) 8.2.2. 一对一(one to one) 8.2.3. 一对多(one to many) 8.3. 使用连接表的单向关联(Un
id
irectional associations with join tables) 8.3.1. 一对多(one to many) 8.3.2. 多对一(many to one) 8.3.3. 一对一(one to one) 8.3.4. 多对多(many to many) 8.4. 双向关联(B
id
irectional associations) 8.4.1. 一对多(one to many) / 多对一(many to one) 8.4.2. 一对一(one to one) 8.5. 使用连接表的双向关联(B
id
irectional associations with join tables) 8.5.1. 一对多(one to many) /多对一( many to one) 8.5.2. 一对一(one to one) 8.5.3. 多对多(many to many) 9. 组件(Component)映射 9.1. 依赖对象(Dependent objects) 9.2. 在集合中出现的依赖对象 9.3. 组件作为Map的索引(Components as Map indices ) 9.4. 组件作为联合标识符(Components as composite
id
entifiers) 9.5. 动态组件 (Dynamic components) 10. 继承映射(Inheritance Mappings) 10.1. 三种策略 10.1.1. 每个类分层结构一张表(Table per
class
hierarchy) 10.1.2. 每个子类一张表(Table per sub
class
) 10.1.3. 每个子类一张表(Table per sub
class
),使用辨别标志(Discriminator) 10.1.4. 混合使用“每个类分层结构一张表”和“每个子类一张表” 10.1.5. 每个具体类一张表(Table per concrete
class
) 10.1.6. Table per concrete
class
, using implicit polymorphism 10.1.7. 隐式多态和其他继承映射混合使用 10.2. 限制 11. 与对象共事 11.1.
Hibernate
对象状态(object states) 11.2. 使对象持久化 11.3. 装载对象 11.4. 查询 11.4.1. 执行查询 11.4.1.1. 迭代式获取结果(Iterating results) 11.4.1.2. 返回元组(tuples)的查询 11.4.1.3. 标量(Scalar)结果 11.4.1.4. 绑定参数 11.4.1.5. 分页 11.4.1.6. 可滚动遍历(Scrollable iteration) 11.4.1.7. 外置命名查询(Externalizing named queries) 11.4.2. 过滤集合 11.4.3. 条件查询(Criteria queries) 11.4.4. 使用原生SQL的查询 11.5. 修改持久对象 11.6. 修改脱管(Detached)对象 11.7. 自动状态检测 11.8. 删除持久对象 11.9. 在两个不同数据库间复制对象 11.10. Session刷出(flush) 11.11. 传播性持久化(transitive persistence) 11.12. 使用元数据 12. 事务和并发 12.1. Session和事务范围(transaction scopes) 12.1.1. 操作单元(Unit of work) 12.1.2. 应用程序事务(Application transactions) 12.1.3. 关注对象标识(Cons
id
ering object
id
entity) 12.1.4. 常见问题 12.2. 数据库事务声明 12.2.1. 非托管环境 12.2.2. 使用JTA 12.2.3. 异常处理 12.3. 乐观并发控制(Optimistic concurrency control) 12.3.1. 应用程序级别的版本检查(Application version checking) 12.3.2. 长生命周期session和自动版本化 12.3.3. 脱管对象(deatched object)和自动版本化 12.3.4. 定制自动版本化行为 12.4. 悲观锁定(Pessimistic Locking) 13. 拦截器与事件(Interceptors and events) 13.1. 拦截器(Interceptors) 13.2. 事件系统(Event system) 13.3.
Hibernate
的声明式安全机制 14. 批量处理(Batch processing) 14.1. 批量插入(Batch inserts) 14.2. 批量更新(Batch updates) 14.3. 大批量更新/删除(Bulk update/delete) 15. HQL:
Hibernate
查询语言 15.1. 大小写敏感性问题 15.2. from子句 15.3. 关联(Association)与连接(Join) 15.4. select子句 15.5. 聚集函数 15.6. 多态查询 15.7. where子句 15.8. 表达式 15.9. order by子句 15.10. group by子句 15.11. 子查询 15.12. HQL示例 15.13. 批量的UPDATE & DELETE语句 15.14. 小技巧 & 小窍门 16. 条件查询(Criteria Queries) 16.1. 创建一个Criteria 实例 16.2. 限制结果集内容 16.3. 结果集排序 16.4. 关联 16.5. 动态关联抓取 16.6. 查询示例 16.7. 投影(Projections)、聚合(aggregation)和分组(grouping) 16.8. 离线(detached)查询和子查询 17. Native SQL查询 17.1. 创建一个基于SQL的Query 17.2. 别名和属性引用 17.3. 命名SQL查询 17.3.1. 使用return-property来明确地指定字段/别名 17.3.2. 使用存储过程来查询 17.3.2.1. 使用存储过程的规则和限制 17.4. 定制SQL用来create,update和delete 17.5. 定制装载SQL 18. 过滤数据 18.1.
Hibernate
过滤器(filters) 19. XML映射 19.1. 用XML数据进行工作 19.1.1. 指定同时映射XML和类 19.1.2. 只定义XML映射 19.2. XML映射元数据 19.3. 操作XML数据 20. 提升性能 20.1. 抓取策略(Fetching strategies) 20.1.1. 操作延迟加载的关联 20.1.2. 调整抓取策略(Tuning fetch strategies) 20.1.3. 单端关联代理(Single-ended association proxies) 20.1.4. 实例化集合和代理(Initializing collections and proxies) 20.1.5. 使用批量抓取(Using batch fetching) 20.1.6. 使用子查询抓取(Using subselect fetching) 20.1.7. 使用延迟属性抓取(Using lazy property fetching) 20.2. 二级缓存(The Second Level Cache) 20.2.1. 缓存映射(Cache mappings) 20.2.2. 策略:只读缓存(Strategy: read only) 20.2.3. 策略:读/写缓存(Strategy: read/write) 20.2.4. 策略:非严格读/写缓存(Strategy: nonstrict read/write) 20.2.5. 策略:事务缓存(transactional) 20.3. 管理缓存(Managing the caches) 20.4. 查询缓存(The Query Cache) 20.5. 理解集合性能(Understanding Collection performance) 20.5.1. 分类(Taxonomy) 20.5.2. Lists, maps 和sets用于更新效率最高 20.5.3. Bag和list是反向集合类中效率最高的 20.5.4. 一次性删除(One shot delete) 20.6. 监测性能(Monitoring performance) 20.6.1. 监测SessionFactory 20.6.2. 数据记录(Metrics) 21. 工具箱指南 21.1. Schema自动生成(Automatic schema generation) 21.1.1. 对schema定制化(Customizing the schema) 21.1.2. 运行该工具 21.1.3. 属性(Properties) 21.1.4. 使用Ant(Using Ant) 21.1.5. 对schema的增量更新(Incremental schema updates) 21.1.6. 用Ant来增量更新schema(Using Ant for incremental schema updates) 22. 示例:父子关系(Parent Child Relationships) 22.1. 关于collections需要注意的一点 22.2. 双向的一对多关系(B
id
irectional one-to-many) 22.3. 级联生命周期(Cascading lifecycle) 22.4. 级联与未保存值(Cascades and unsaved-value) 22.5. 结论 23. 示例:Weblog 应用程序 23.1. 持久化类 23.2.
Hibernate
映射 23.3.
Hibernate
代码 24. 示例:复杂映射实例 24.1. Employer(雇主)/Employee(雇员) 24.2. Author(作家)/Work(作品) 24.3. Customer(客户)/Order(订单)/Product(产品) 24.4. 杂例 24.4.1. "Typed" one-to-one association 24.4.2. Composite key example 24.4.3. Content based discrimination 24.4.4. Associations on alternate keys 25. 最佳实践(Best Practices)
Java EE
67,512
社区成员
225,880
社区内容
发帖
与我相关
我的任务
Java EE
J2EE只是Java企业应用。我们需要一个跨J2SE/WEB/EJB的微容器,保护我们的业务核心组件(中间件),以延续它的生命力,而不是依赖J2SE/J2EE版本。
复制链接
扫一扫
分享
社区描述
J2EE只是Java企业应用。我们需要一个跨J2SE/WEB/EJB的微容器,保护我们的业务核心组件(中间件),以延续它的生命力,而不是依赖J2SE/J2EE版本。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享