



34,588
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享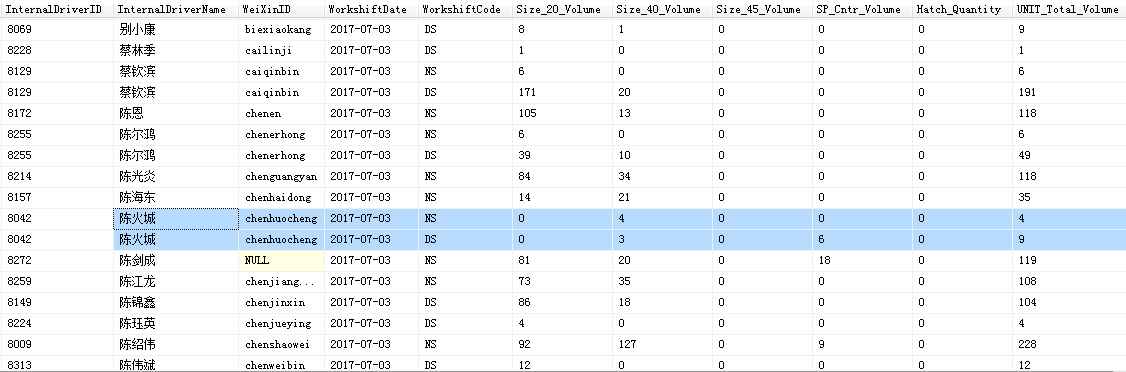


 [/quote]
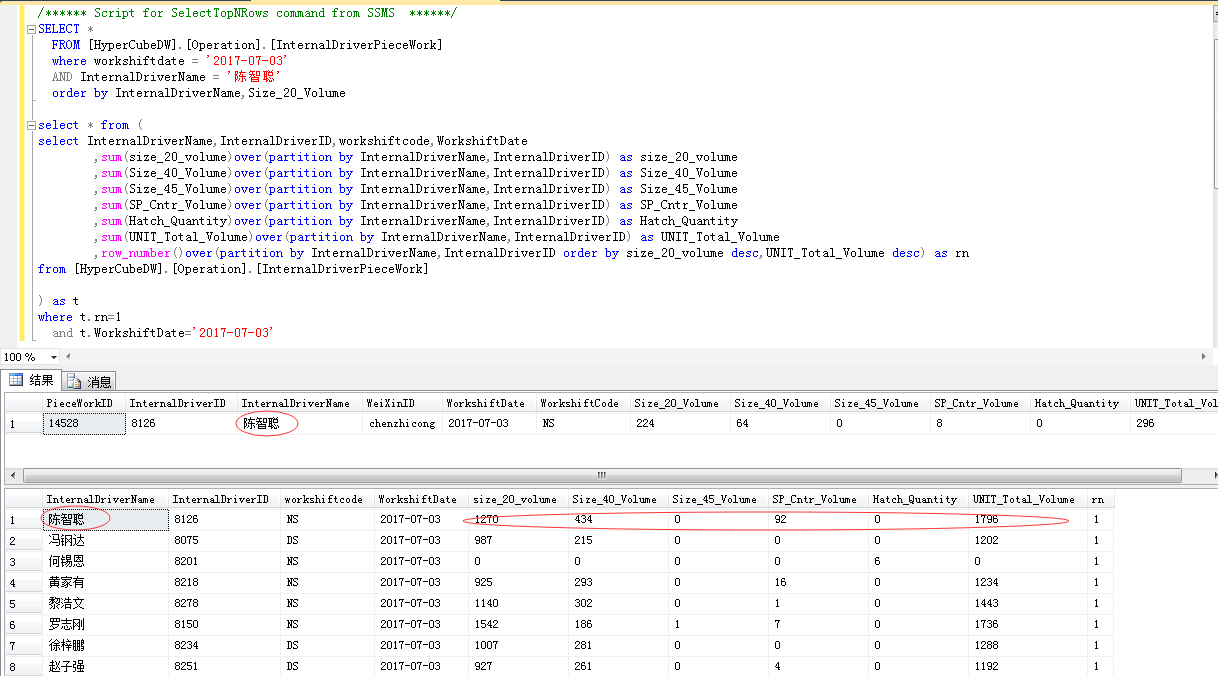
你要把条件放在里边的子查询,我写的逻辑是处理最后的结果,已经过滤掉一些数据,你在这里去查询肯定结果不对
[/quote]
你要把条件放在里边的子查询,我写的逻辑是处理最后的结果,已经过滤掉一些数据,你在这里去查询肯定结果不对--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([name] int,[SIZE_20_VOLUME] int,[UNIT_TOTAL_VOLUME] int,[workshiftcode] NVARCHAR(100),[WorkshiftDate] [date])
Insert #T
select 1,10,20,'DS','2017-07-01' union all
select 1,20,20,'NS','2017-07-01' union all
select 2,20,30,'DS','2017-07-01' union all
select 2,20,20,'NS','2017-07-01' union all
select 3,NULL,NULL,'DS','2017-07-01'
Go
--测试数据结束
SELECT a.name ,
SUM(a.SIZE_20_VOLUME) AS SIZE_20_VOLUME ,
SUM(a.[UNIT_TOTAL_VOLUME]) AS [UNIT_TOTAL_VOLUME] ,
MAX(CASE WHEN ISNULL(a.[SIZE_20_VOLUME],0) = ISNULL(b.[SIZE_20_VOLUME],0)
THEN ( CASE WHEN ISNULL(a.[UNIT_TOTAL_VOLUME],0) > ISNULL(b.[UNIT_TOTAL_VOLUME],0)
THEN a.[workshiftcode]
ELSE ISNULL(b.[workshiftcode],a.[workshiftcode])
END )
WHEN ISNULL(a.[SIZE_20_VOLUME],0) > ISNULL(b.[SIZE_20_VOLUME],0)
THEN a.[workshiftcode]
ELSE b.[workshiftcode]
END) AS [workshiftcode]
FROM #T a
LEFT JOIN #T b ON b.name = a.name
AND ( b.SIZE_20_VOLUME <> a.SIZE_20_VOLUME
OR b.UNIT_TOTAL_VOLUME <> a.UNIT_TOTAL_VOLUME
)
GROUP BY a.name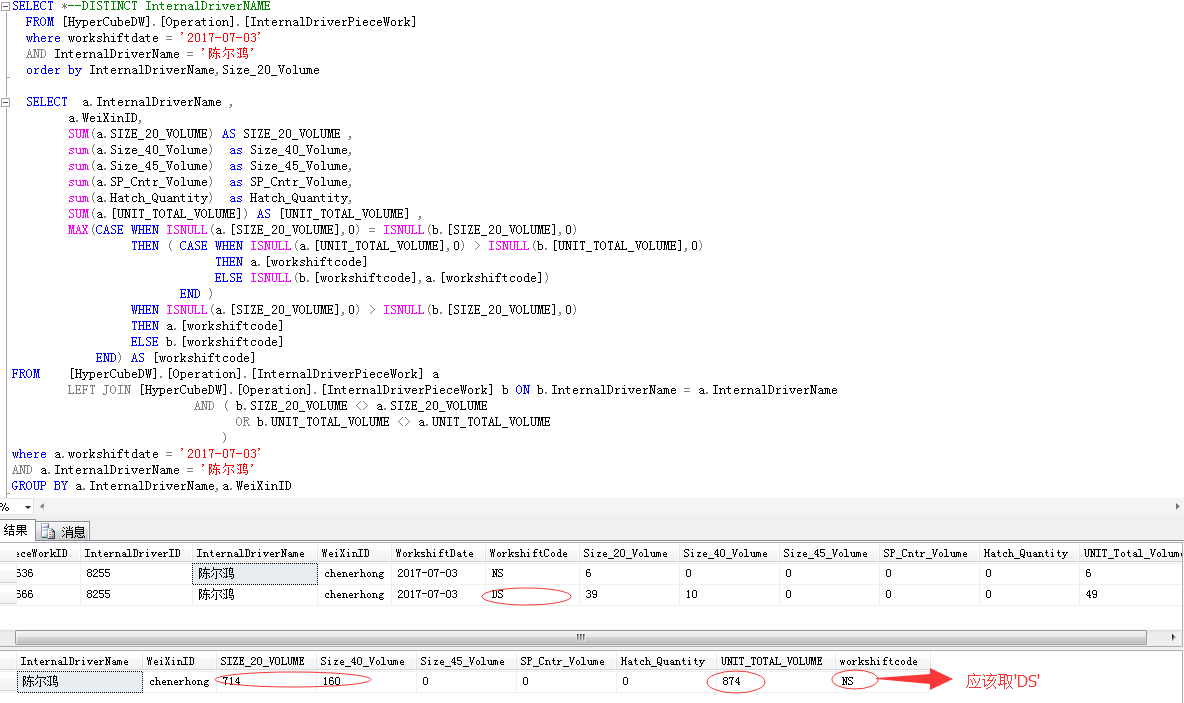

--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([name] int,[SIZE_20_VOLUME] int,[UNIT_TOTAL_VOLUME] int,[workshiftcode] NVARCHAR(100),[WorkshiftDate] [date])
Insert #T
select 1,10,20,'DS','2017-07-01' union all
select 1,20,20,'NS','2017-07-01' union all
select 2,20,30,'DS','2017-07-01' union all
select 2,20,20,'NS','2017-07-01' union all
select 3,NULL,NULL,'DS','2017-07-01'
Go
--测试数据结束
SELECT a.name ,
SUM(a.SIZE_20_VOLUME) AS SIZE_20_VOLUME ,
SUM(a.[UNIT_TOTAL_VOLUME]) AS [UNIT_TOTAL_VOLUME] ,
MAX(CASE WHEN ISNULL(a.[SIZE_20_VOLUME],0) = ISNULL(b.[SIZE_20_VOLUME],0)
THEN ( CASE WHEN ISNULL(a.[UNIT_TOTAL_VOLUME],0) > ISNULL(b.[UNIT_TOTAL_VOLUME],0)
THEN a.[workshiftcode]
ELSE ISNULL(b.[workshiftcode],a.[workshiftcode])
END )
WHEN ISNULL(a.[SIZE_20_VOLUME],0) > ISNULL(b.[SIZE_20_VOLUME],0)
THEN a.[workshiftcode]
ELSE b.[workshiftcode]
END) AS [workshiftcode]
FROM #T a
LEFT JOIN #T b ON b.name = a.name
AND ( b.SIZE_20_VOLUME <> a.SIZE_20_VOLUME
OR b.UNIT_TOTAL_VOLUME <> a.UNIT_TOTAL_VOLUME
)
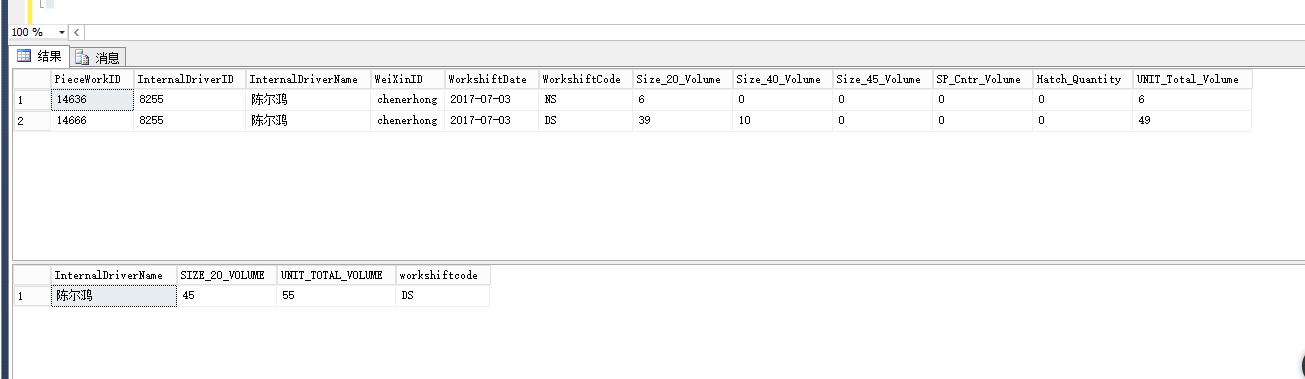
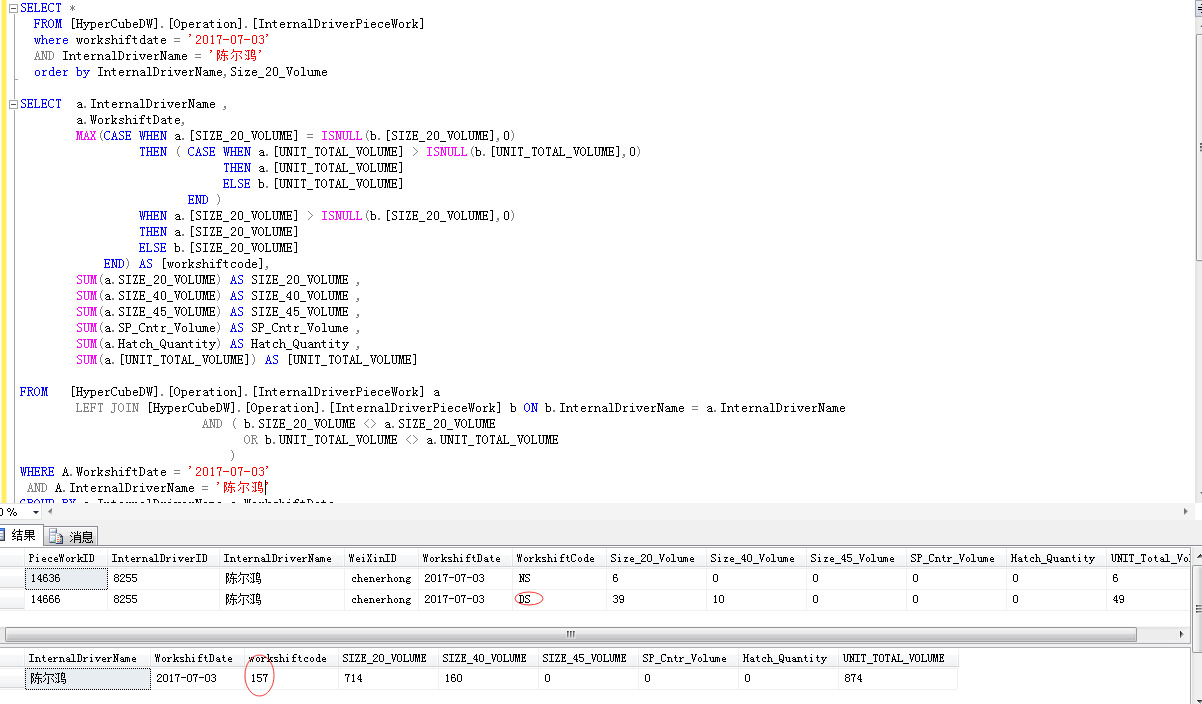
GROUP BY a.nameSELECT * FROM [InternalDriverPieceWork] WHERE WorkshiftDate='2017-07-03' AND InternalDriverName='陈尔鸿'
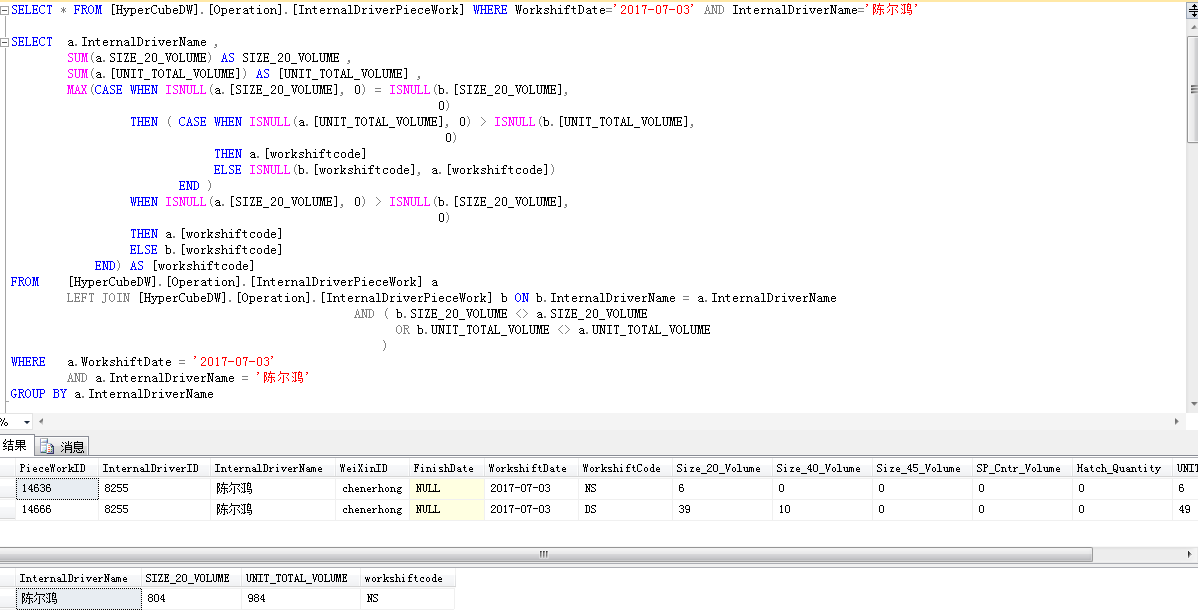
SELECT a.InternalDriverName ,
SUM(a.SIZE_20_VOLUME) AS SIZE_20_VOLUME ,
SUM(a.[UNIT_TOTAL_VOLUME]) AS [UNIT_TOTAL_VOLUME] ,
MAX(CASE WHEN ISNULL(a.[SIZE_20_VOLUME], 0) = ISNULL(b.[SIZE_20_VOLUME],
0)
THEN ( CASE WHEN ISNULL(a.[UNIT_TOTAL_VOLUME], 0) > ISNULL(b.[UNIT_TOTAL_VOLUME],
0)
THEN a.[workshiftcode]
ELSE ISNULL(b.[workshiftcode], a.[workshiftcode])
END )
WHEN ISNULL(a.[SIZE_20_VOLUME], 0) > ISNULL(b.[SIZE_20_VOLUME],
0)
THEN a.[workshiftcode]
ELSE b.[workshiftcode]
END) AS [workshiftcode]
FROM [InternalDriverPieceWork] a
LEFT JOIN [InternalDriverPieceWork] b ON b.InternalDriverName = a.InternalDriverName
AND ( b.SIZE_20_VOLUME <> a.SIZE_20_VOLUME
OR b.UNIT_TOTAL_VOLUME <> a.UNIT_TOTAL_VOLUME
)
WHERE a.WorkshiftDate = '2017-07-03'
AND a.InternalDriverName = '陈尔鸿'
GROUP BY a.InternalDriverName
 [/quote]
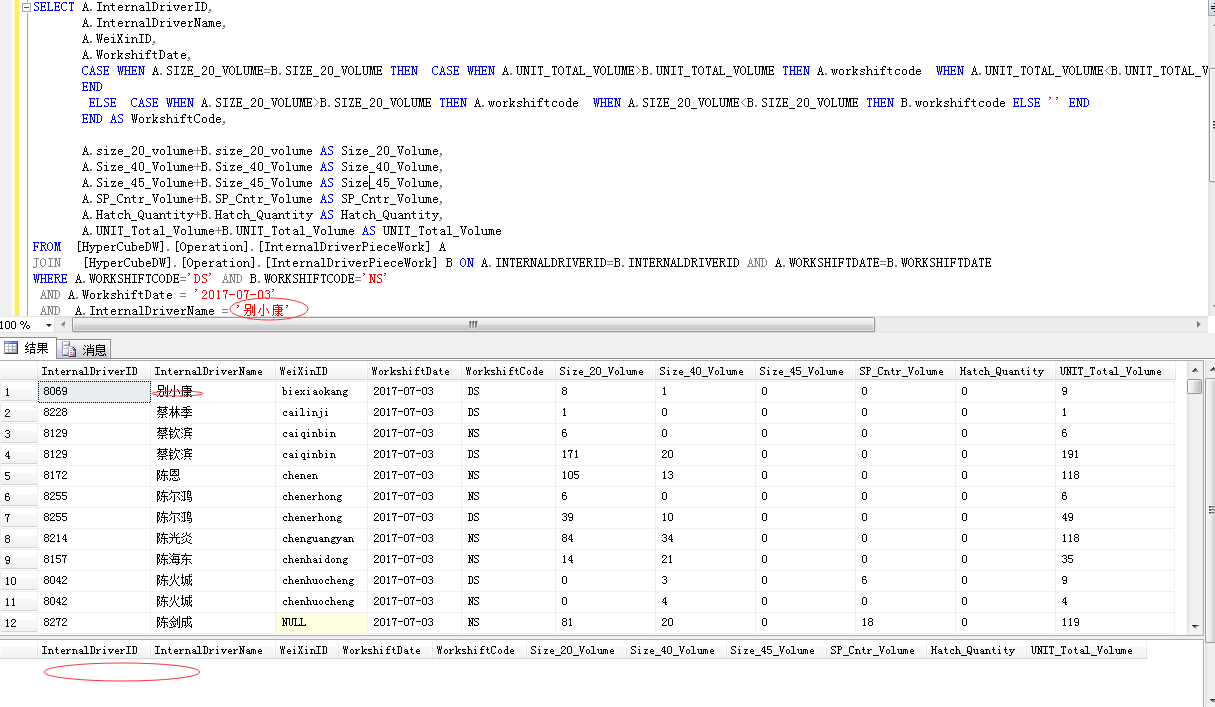
其实我没看明白是什么需求……如果可以建议楼主给出表结构、测试数据、规则、以及基于测试数据的正确结果
[/quote]
其实我没看明白是什么需求……如果可以建议楼主给出表结构、测试数据、规则、以及基于测试数据的正确结果
