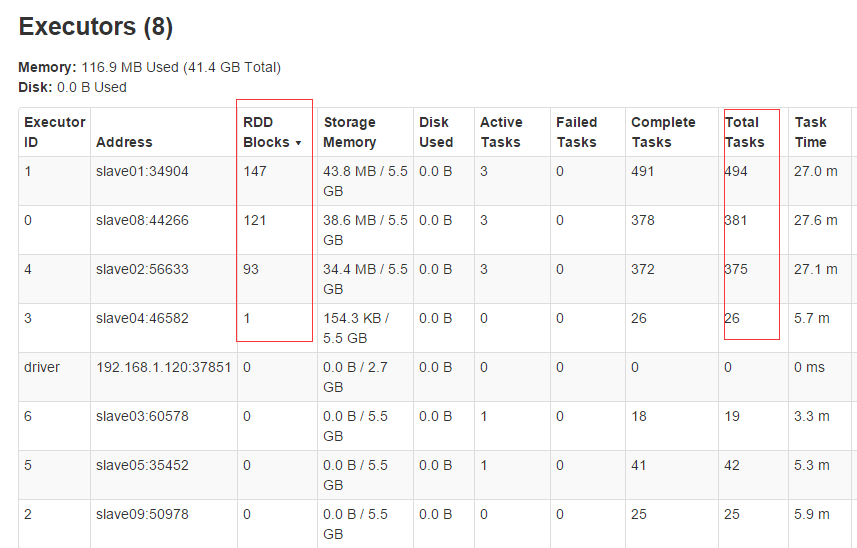
我也出现了这种情况,但不知道原因是不是一样,我是两个表进行full join, t1 full join t2 表t1的partition大部分都集中在几台机器上,而表t2的parition分布均衡, 执行full join时,表t1在左边的时候,task就都集中在了 某几台机器上,表t2在左侧的时候,task分布就非常均衡,join的性能也提升了很多。 原因应该是根据后面on的条件,将t1的partition对应的t2数据拉取到t1分区所在的机器上执行task任务,所以出现了task倾斜的问题。
1,258
社区成员
1,168
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





