HDInsight Linux 在中国区正式上线,对于很多 Azure 上的大数据用户来说,是一件喜大普奔的事情:)除了底层虚拟机是 Linux ,更加符合用户的使用习惯以外,还增加了很多令人兴奋的新特性,例如 R Server , Spark 以及 Kafka 的支持,版本的更新,完整的监控等等,本文主要从以下几个方面来介绍 Spark 在 HDInsight Linux 上的创建,配置和开发:
第一部分:
为什么使用 Spark
HDInsight Linux 简介
创建配置 Spark on HDInsight
第二部分:
HDInsight 的监控和管理
Spark 集群使用及应用开发部署
第三部分
利用 Spark 进行机器学习
Spark 集群上的第三方应用
Spark 简介
一说到大数据分析,我们直接的反应就是 Hadoop 集群, MapReduce , HDFS 等等以及相关的生态系统,然而我们现在谈大数据,并不仅仅是海量数据的处理,同时也包括机器学习,流式分析,数据挖掘,图形计算……这也正是 Spark 作为一个基于内存的分布式并行大数据处理框架越来越火的原因之一,相对于传统的 MapReduce , Spark 具有以下优点:
高性能:相对于传统的 MapReduce ,基于磁盘的运算方式来讲, Spark 是一个基于内存的分布式运算框架,并且由于 RDD 和 Cache 的使用,数据的交换基于内存,大幅度提升了性能,在不同的场景下,比 MapReduce 快10倍到100倍不等。
易于使用: 支持 Java,Python,R, Scala 开发语言,并且目前 Spark 提供超过 80 多种抽象的数据转换操作,让你可以快速构建并行处理程序。
生态系统:Spark 目前已经构建出了完善而成熟的生态系统,内建对于 HDFS, RDBMS, S3, Apache Hive, Cassandra and MongoDB, Azure Storage 等数据源的良好支持。
统一引擎:从下图你可以看到, Spark SQL,Spark Streaming, Spark MLLib 以及 Graphx 均基于 Spark 核心引擎,也就意味着在一个平台可以统一支持多种不同的应用,相对于 Hadoop 的碎片化的组建生态,对开发人员来讲简单很多也高效很多
多调度器支持:虽然 Spark 底层的数据存储依然依赖于 HDFS,然而对于资源调度来说,Spark 可以使用 YARN,也可以使用 Mesos 甚至是独立的调度器,部署非常灵活,尤其是在容器技术大行其道的时候,你可以在容器上跑 Spark ,用 Mesos 来统一管理
什么是 HDInsight
HDInsight 是微软推出的基于云端的 Hadoop 大数据处理平台,支持 Storm,Spark,HBase,R Server, Kafka,Interactive Hive(LLAP) 等多种不同的大数据框架,HDInsight Linux 顾名思义就是底层的头结点和数据节点都是基于 Linux 的,目前是 Ubuntu 16.04 LTS 。本身来讲 HDInsight 是基于大数据三大巨头之一的 Hortonworks 公司的 Hortonworks Data Platform (HDP) 来构建的,并针对企业级用户在云端使用的需求,增强了管理和安全多方面的功能。
如果你之前在自己的数据中心,在云端使用 HDInsight 可以为企业带来诸多好处,例如:
易于使用,部署方便:对于 HDInsight 的集群部署来说,你不需要了解复杂的底层细节,头结点,数据节点的配置,不同的组件等等,在 Azure 的管理界面,经过几个简单的点击,几分钟的时间,一个 16 节点的集群就创建成功了
按需付费:你不需要为了你的企业运行大数据,一次采购大量的硬件,并且业务闲时机器闲置,浪费资源,你只需要在需要计算的时候,创建集群,运算完毕就可以删除该集群, Azure 只按照使用量来计费,由于计算和存储分离的特性,你的数据库会保存在 Azure 存储上,每个月只需要少量存储的钱
弹性扩展:你可以根据你的也无需要,在界面上扩展或者伸缩节点数目,满足你的业务的弹性要求
丰富的服务和版本选择:HDInsight 提供各个不同版本的 HBase,Hadoop,Spark,Storm,Hive,Pig,R, Kafka 等等生态系统组件,而且自动安装配置,满足你不同的业务需求
开源 100% 兼容:HDInsight 基于HDP 构建,与开源 Hadoop完全兼容,这就意味着你已有的大数据方案,可以快速的迁移到云
端而不需要或者轻微的改动(例如数据的存储位置)就可以使用
数据持久化:从以下架构可以看出,HDInsight 的 HDFS 基于 Azure Storage 实现,意味着你存储的每一分数据,都会默认存储完全相同的三份,对于企业来说,数据安全就是核心,Azure 的存储高可用性,保证了在任何情况下的数据可靠性
创建 HDInsight Linux for Spark
从下图可以看到,创建 HDInsight 的简单步骤,你可以先创建一个存储账号,用于存储 Spark 要处理的数据,也可以在创建集群时一起创建,然后创建集群,完成后使用 Spark SQL 进行数据处理,在部署方式上,你可以使用 ARM 模板部署, Powershell 部署或者 Linux/Mac 下使用 Azure CLI 部署,本例中使用 Azure 管理界面进行部署。
1. 打开 Azure 新 portal,https://portal.azure.cn, 选择新建,Intelligence + Analytics , 就可以看到 HDInsight 图标,单击进行创建:
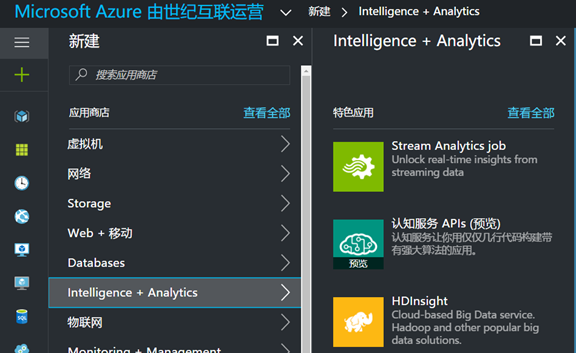
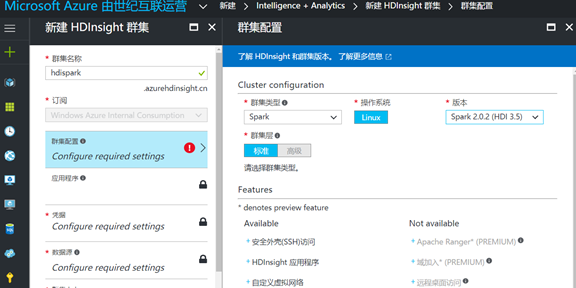
2. 给你的 cluster 起一个名字,在本例中叫 hdispark,配置集群,在集群类型中,可以看到我们可以选择 Hadoop,HBase,Storm,Spark,R server 等等,我们选择 Spark ,操作系统目前类型只支持 Linux,版本选择 Spark2.0,其对应的 HDP 是 3.5 版本:
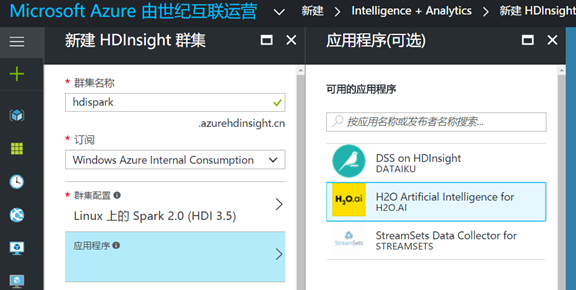
3. 在应用程序选项部分,你可以看到 HDInsight Spark 自带了一些第三方的,基于 Spark 的工具集和库,你可以根据需要选择使用,我们暂时忽略掉该部分,在下一章中详细介绍:
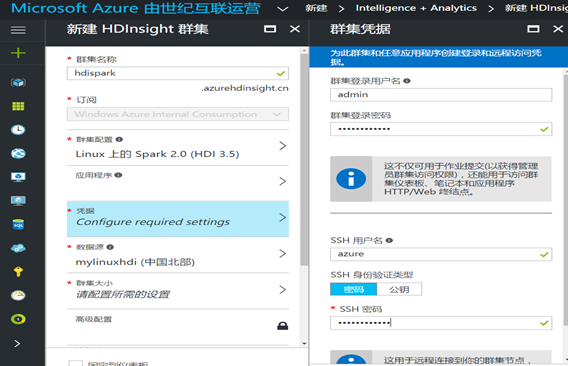
4. 在凭据部分,第一个用户名和密码是你后面需要访问 Ambari 仪表板需要的用户名密码,第二个用户名密码是你使用 SSH 进行远程登录的用户名密码,按照你的习惯进行设置,但这些用户名和密码必须记住,旺季后无法恢复,后面会使用到:
5. 数据源的部分,需要配置你的数据存储在什么地方,目前 Data Lake 中国暂时不支持,所以我们只使用 Azure 存储,配置你的数据处理存储在哪个账号里,如果是第一次创建,可以选择创建新建存储的账号,指定名称即可,或者你也可以使用你已经创建的存储账号:
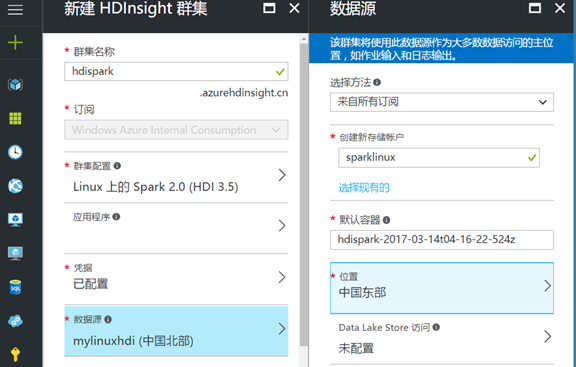
注:如果你想删除 Spark 计算集群后,依然保存 Hive 和 Oozie 的数据,你需要提前创建一个 SQL 数据库用来保存数据:
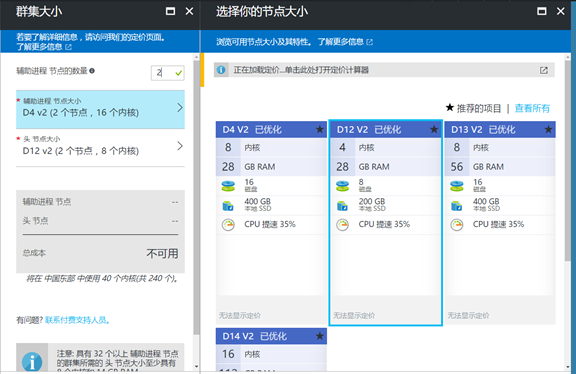
6. 在 Spark 集群中,默认需要两个头结点,你可以指定多个工作节点,在群集大小中,需要选择合适的节点大小,和数据节点的个数,这部分的选择关系到你有多大的数据量,需要多长时间完成,并且关系到成本,需要提前做规划,选择完成后,选择确定:
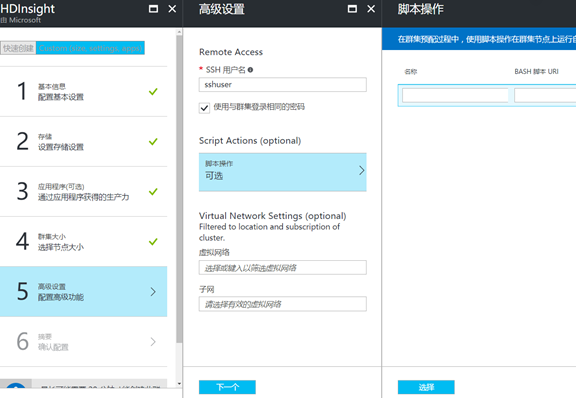
7. 在高级特性配置中,你可以选择配置 vNet,即将 Spark 集群部署到你的虚拟网络里面,这样虚拟网络的虚拟机可以直接访问集群;也可以自定义脚本,在集群部署完
成后再额外部署新的包或者执行安装后的操作;点击确定开始创建:
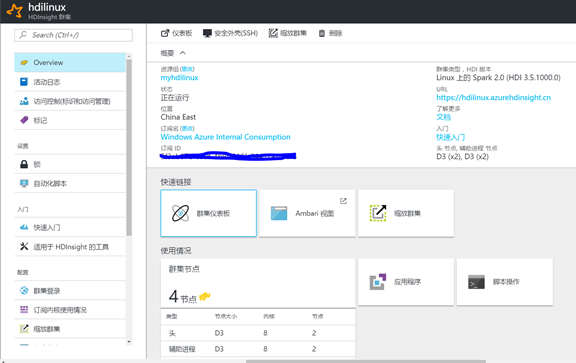
8. 创建完成后,你就可以看到 Spark 集群的仪表板界面,就可以看到仪表板界面,包括集群仪表板,Ambari ,SSH 登录信息,节点信息,在本例中一共有 4 个节点,2 个头节点,2 个工作节点:
由于篇幅的关系,我们将在下一节中介绍如何对 Spark 集群进行监控,管理以及 Spark 上的应用开发和部署。感兴趣的朋友,也可通过
点击这里自行了解。





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

