社区
HTML/XML
帖子详情
Html parser 取不出标签内的内容
代斯Max
2017-09-19 05:18:49
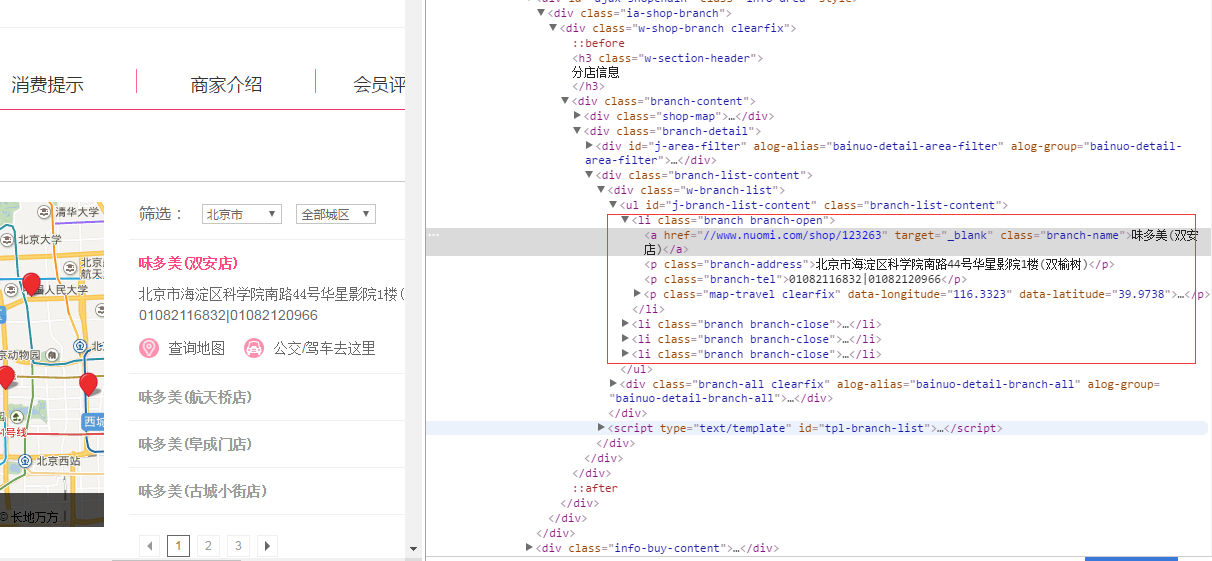
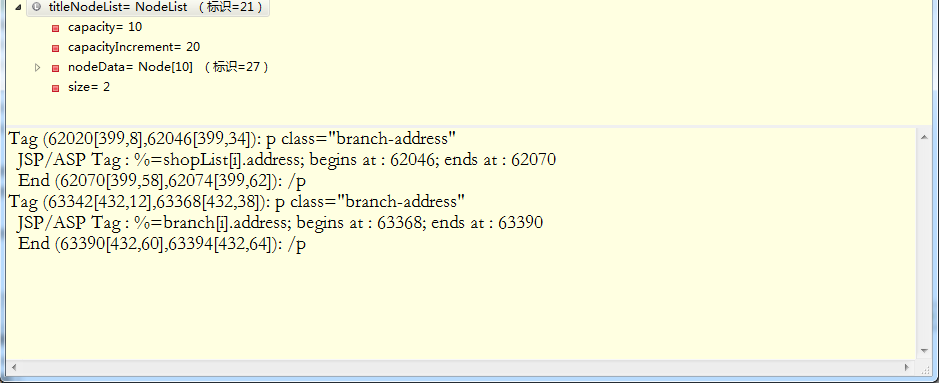
想爬取地址数据,方法都是对的,但想取的内容就像不对外开放似的。就说这个地址branch-address,script内的内容取出来了,li标签内的数据取不出来,为什么?
...全文
411
2
打赏
收藏
Html parser 取不出标签内的内容
想爬取地址数据,方法都是对的,但想取的内容就像不对外开放似的。就说这个地址branch-address,script内的内容取出来了,li标签内的数据取不出来,为什么?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
代斯Max
2017-09-19
打赏
举报
回复
引用 1 楼 oyljerry 的回复:
一般是ajax异步返回的内容,它是js动态插入的
谢谢,这样有解决的方法吗?
oyljerry
2017-09-19
打赏
举报
回复
一般是ajax异步返回的内容,它是js动态插入的
关于
Html
Parser
提取
标签
不完整的问题(
Html
Parser
扩展)
Html
Parser
可用来解析
html
,但它并不认识所有
标签
,如font,strong和自定义
标签
...而遇到它不认识的
标签
时提取出来的
内容
只会是这个
标签
的开始
标签
.例如有段
Html
是加粗字体 ,如果用NodeList nodeList =
parser
.
parser
(new TagNameFilter("strong"));提取的话结果就是 .如果想让提取结果是完整的加粗字体,则要扩展
Html
Parser
,让它认识这个
标签
,方法是自定义一个类继承自
Html
Parser
,然后利用PrototypicalNo
python3 读取
html
文件,关于Python3.7的BeautifulSoup解析
html
文件缺失
内容
的问题
背景从网站爬取
html
,用BeautifulSoup解析
标签
内容
,发现用尽办法都找不到想要的
标签
。分析过程(1)把urlopen请求到的
html
打印出来,body是完整的;(2)把BeautifulSoup解析后的soup打印出来,body只有少量的div,很快结束了。但后面还有一堆未格式化的
html
内容
,被排斥在body外;(3)一定是BeautifulSoup解析过程出问题了,由于直接请求到的...
python爬虫代码没有结果_beautifulsoup - python爬虫获取不到
标签
内容
问 题链接如下:http://aaxxy.com/vod-detail-i...使用requests请求此连接,然后用BeautifulSoup解析获取 dl > dd > a
标签
的
内容
,其中:上图所示的4个 a
标签
的
内容
只能获取到第一个“电影”,后面三个“动作”“喜剧”“剧情”获取不到,输出结果为None:使用pyquery解析的话连None都不显示,直接跳过这三个
标签
了:请问为什么会这样?...
Pure-JavaScript-
HTML
5-
Parser
源码解读
有个需求要用到
html
标签
解析,又碰巧之前有人写过,就直接用了之前用的东西https://github.com/blowsie/Pure-JavaScript-
HTML
5-
Parser
,git上星不多,不过感觉思路比较特别,和我最开始想的不太一样,稍微看了看原理,总结一下。因为没有release版本,只能写一个commit版本号,3e8b2b1153a40495f9a16506c778d00150...
python爬不是网页_用python爬网站数据,为什么只爬到
标签
,爬不到
标签
内容
呢
问 题我想爬电影票房的数据,网站是http://www.cbooo.cn/movieweek,我要爬网页最下面的【票房日期:2016-11-14至2016-11-20 单周票房:57271万 单周场次:1463995场 单周人次:1781万】这些数据,代码如下:from bs4 import BeautifulSoupimport urllib.requestz = input("请输入网址:")...
HTML/XML
3,055
社区成员
8,066
社区内容
发帖
与我相关
我的任务
HTML/XML
VC/MFC HTML/XML
复制链接
扫一扫
分享
社区描述
VC/MFC HTML/XML
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享