




19,612
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享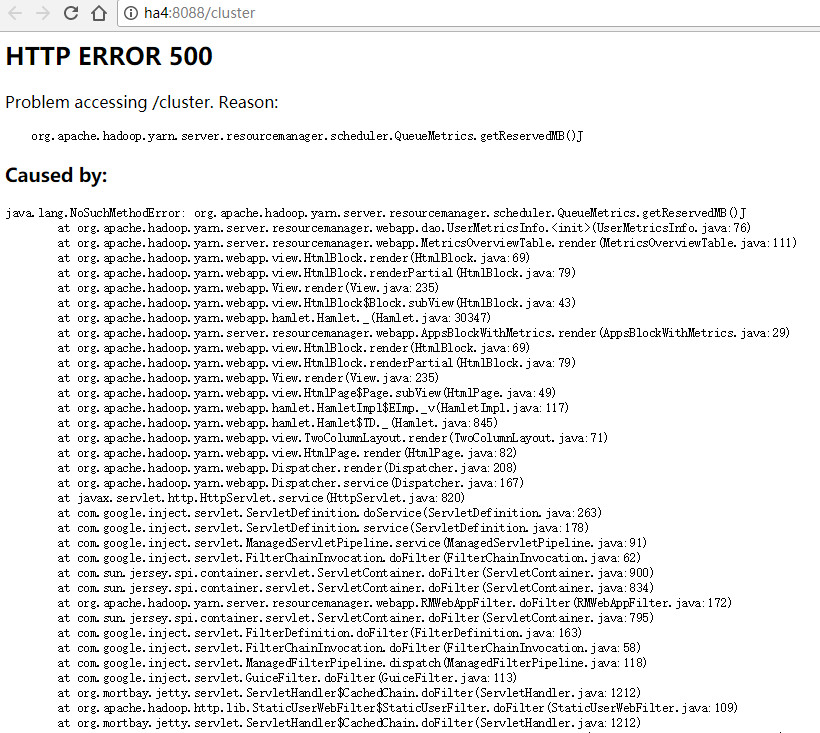
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ha4</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>sp1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ha4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>sp1:8088</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ha1:2181,ha2:2181,ha4:2181</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>40</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>3</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- FairScheduler -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/home/hadoop/storage/software/hadoop-2.7.4/etc/hadoop/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.sizebaseweight</name>
<value>true</value>
</property>
</configuration><?xml version="1.0"?>
<allocations>
<queue name="queueA">
<minResources>1000 mb, 4 vcores</minResources>
<maxResources>5000 mb, 30 vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<minSharePreemptionTimeout>300</minSharePreemptionTimeout>
<weight>2.0</weight>
<queue name="queueB">
<minResources>1000 mb, 4 vcores</minResources>
<maxResources>5000 mb, 15 vcores</maxResources>
</queue>
<queue name="queueC">
<minResources>1000 mb, 4 vcores</minResources>
<maxResources>5000 mb, 15 vcores</maxResources>
</queue>
</queue>
<user name="hadoop">
<maxRunningApps>40</maxRunningApps>
</user>
<userMaxAppsDefault>10</userMaxAppsDefault>
<fairSharePreemptionTimeout>6000</fairSharePreemptionTimeout>
</allocations><?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>172.30.142.54:10020</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
</configuration>
