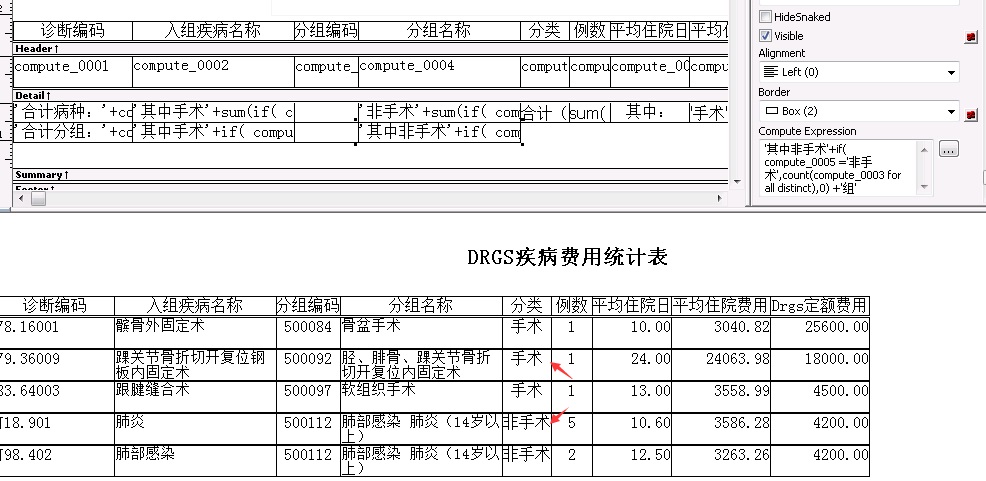
如图所示,报表中分类这一列有两种状态,一种是手术,一种是非手术
我要统计当分类=手术 的时候,分组名称不重复的有多少组
总的合计分组是已经写出语句了: '合计分组:'+count( compute_0003 for all distinct)
加条件来进行分组我也写了,但是貌似没用:
'其中手术'+if( compute_0005 ='手术',count(compute_0003 for all distinct),0) +'组'
'其中非手术'+if( compute_0005 ='非手术',count(compute_0003 for all distinct),0) +'组'
求大神看看是那里不对



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



