社区
脚本语言
帖子详情
怎么用python合并字段不一致的xls文件?求助
majiashu
2017-11-29 09:53:02
问题描述如下:
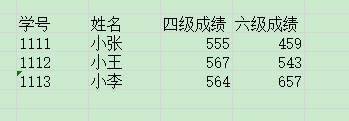
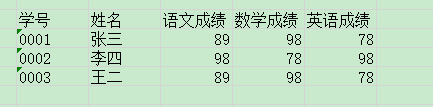
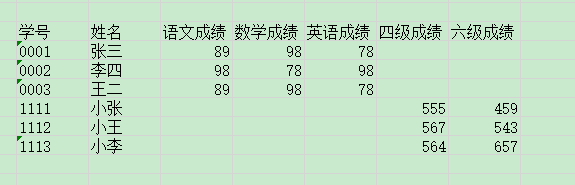
文件一:
文件二:
文件一、文件二合并后:
怎么样能处理那求助,什么方法都行,最好是python
...全文
332
4
打赏
收藏
怎么用python合并字段不一致的xls文件?求助
问题描述如下: 文件一: 文件二: 文件一、文件二合并后: 怎么样能处理那求助,什么方法都行,最好是python
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
珏丶Juer
2017-11-30
打赏
举报
回复
有个思路,尝试将两个表的字段集合进行合并,并去除集合中重复的字段,将这个字段集合作为新文件的字段。 接下来就是将记录一条条的导入进去,没有字段就放空或者填缺省值。
majiashu
2017-11-29
打赏
举报
回复
表比较多,而且数据量又很大,该怎么办构造那?
extend
2017-11-29
打赏
举报
回复
用pandas吧,构造完了,再写进excel 第一个表: >>> part1=pd.DataFrame({'学号':(1111,1112,1113), '姓名':('小张','小王','小李'), '四级成绩':(555,567,564), '六级成绩':(459,542,657)}) >>> part1 六级成绩 四级成绩 姓名 学号 0 459 555 小张 1111 1 542 567 小王 1112 2 657 564 小李 1113 第二个表: >>> part2=pd.DataFrame({'学号':pd.Series(('0001','0002','0003'),dtype='int32'), '姓名':('张三','李四','王五'), '语文成绩':(555,567,564), '数学成绩':(459,542,657)}) >>> part2 姓名 学号 数学成绩 语文成绩 0 张三 1 459 555 1 李四 2 542 567 2 王五 3 657 564 两表合并: >>> pd.concat([part1,part2]) 六级成绩 四级成绩 姓名 学号 数学成绩 语文成绩 0 459.0 555.0 小张 1111 NaN NaN 1 542.0 567.0 小王 1112 NaN NaN 2 657.0 564.0 小李 1113 NaN NaN 0 NaN NaN 张三 1 459.0 555.0 1 NaN NaN 李四 2 542.0 567.0 2 NaN NaN 王五 3 657.0 564.0
extend
2017-11-29
打赏
举报
回复
引用 2 楼 qq_38377523 的回复:
表比较多,而且数据量又很大,该怎么办构造那?
pandas支持直接读取excel,读成dataframe,最后合并成一个frame里,在写回excel。 但是我不确定pandas能不能直接写excel,不能的话,安装相应的包,不难。 从你的需求上看,pandas处理这个问题最合适,注意下数据类型即可。实际上我的例子里,对"0001"这样的编号没找到合适的数据类型,所以你也看到了,结果直接变成1,前面的0省略了,你自己需要注意下。 python+pandas处理大数据得心应手,你的数据量有多少?几百万条?完全没问题的。
python
实现多表格
合并
_
python
如何把两个表格数据,
合并
为一个呢?
想把文本 1 和文本 2 ,
合并
为文本 3 , 2 个数据源, date 是日期,然后另外 2 个不同
字段
,想
合并
到一张表中,也就是
合并
成同一个 json ,
求助
,有办法吗文本 1 :[{'aaaaa': 0, 'date': '12.13'},{'aaaaa': 0, 'date': '12.14'},{'aaaaa': 220, 'date': '12.15'},{'aaaaa': 0, 'd...
python
csv数据处理将类型数据改变为数字_如何快速学会
Python
处理数据?(5000字走心总结)...
大家好,我是大师兄。很多同学抱怨自己很想学好
Python
,但学了好久,书也买不少,视频课程也看了不少,但是总是学了一段时间,感觉还是没什么收获,碰到问题没思路,有思路写不出多少行代码,遇到报错时也不知道怎么处理。从入门到放弃,这是很多学习
python
的同学常常挂在嘴边上的口头禅。今天我分享一些自己学习
Python
的心得,并用一个案例来说明
python
解决问题的基本思路和框架。1 如何学好...
python
如何对表格数据分类-
python
如何把两个表格数据,
合并
为一个呢?
想把文本 1 和文本 2 ,
合并
为文本 3 , 2 个数据源, date 是日期,然后另外 2 个不同
字段
,想
合并
到一张表中,也就是
合并
成同一个 json ,
求助
,有办法吗文本 1 :[{"aaaaa": 0, "date": "12.13"},{"aaaaa": 0, "date": "...
求助
:
Python
merge后数据全部为空值nan
问题阐述:如何解决merge后数据全部为nan? A有1000行、2列 B有500行、1000列 一、左连接 df=pd.merge(A,B,on=[id1,id2], how='left') 结果df.shape()正常,1000行、1000列。但是数据有998列为空。 二、右连接 df=pd.merge(A,B,on=[id1,id2], how='right') 结果df.s...
110道
python
面试笔试题汇总,你能答对几道?
该文110道面试题全部来自于大家笔试面试时候拍照后发到群里
求助
的题目,并自己一道一道亲自做了,大部分题目属于巩固基本
python
知识点的题目,希望对基本知识不熟悉的同学,能认真做一遍,肯定会有不少收获 1、一行代码实现1--100之和 利用sum()函数求和 2、如何在一个函数内部修改全局变量 利用global 修改全局变量 3、列出5个
python
标准库 o...
脚本语言
37,719
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享