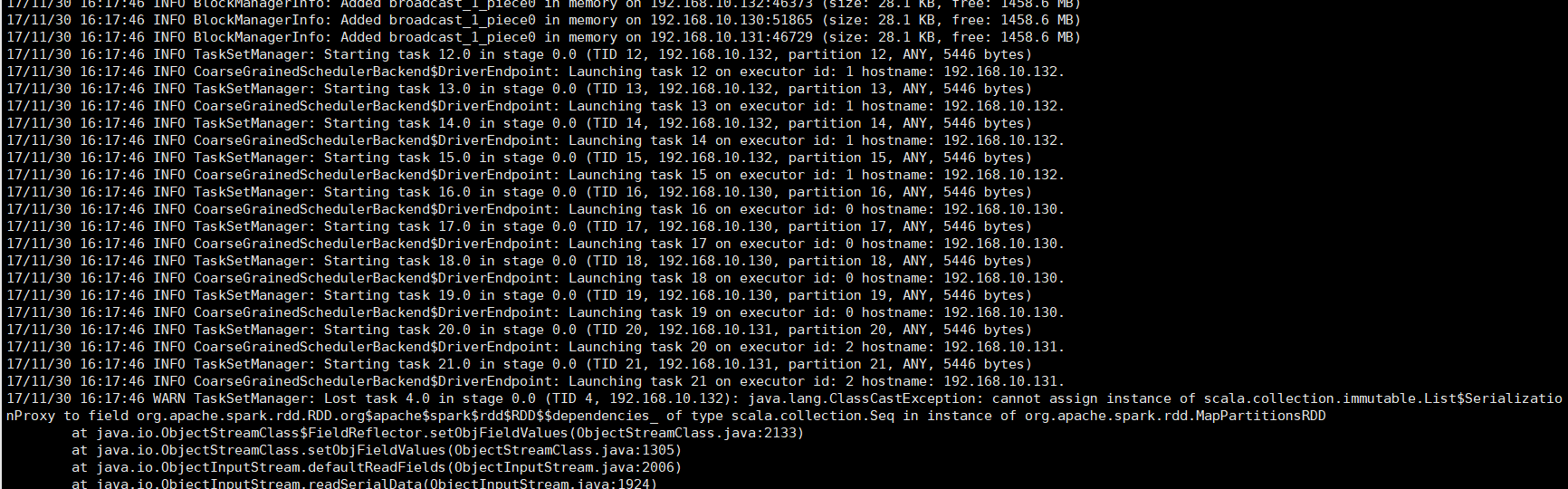
运行代码,发现如果只是使用sparksql进行数据查询不会报错,但是一旦需要insert,或者collect,show之类的就直接报如下的错误。
package MlBigdata
import org.apache.spark._
import org.apache.spark.sql.hive.HiveContext
object mlEndclaimInfo {
def main(args: Array[String]): Unit = {
if (args.length < 1) {
System.err.println("Usage: HdfsWordCount <directory>")
System.exit(1)
}
val columnGroup = args.mkString(",")
val conf = new SparkConf().setAppName("spark_ml").setMaster("spark://192.168.10.124:7077")
conf.setExecutorEnv("SPARK_EXECUTOR_MEMORY", "3G")
val jars =Array("/home/data/MlBigdata.jar")
conf.setJars(jars)
val sc =new SparkContext(conf);
val sqlContext =new HiveContext(sc)
sqlContext.setConf("spark.sql.shuffle.partitions","4")
import sqlContext.implicits._
import sqlContext.sql
sqlContext.sql("use hive")
val answer =sqlContext.sql("select count(distinct notificationno) notification_dis_count,sum(1) notification_count,sum(CLAIMAMOUNT) claimamount,sum(CLAIMAMOUNT_CAR) claimamount_car,sum(CLAIMAMOUNT_MAN) claimamount_man,sum(CLAIMAMOUNT_THING) claimamount_thing,"+columnGroup+" from ml_endclaim_info group by "+columnGroup)
answer.show
sc.stop()
}
}




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
