社区
脚本语言
帖子详情
scrapy框架下Request请求的问题
beike3
2017-12-24 03:04:37
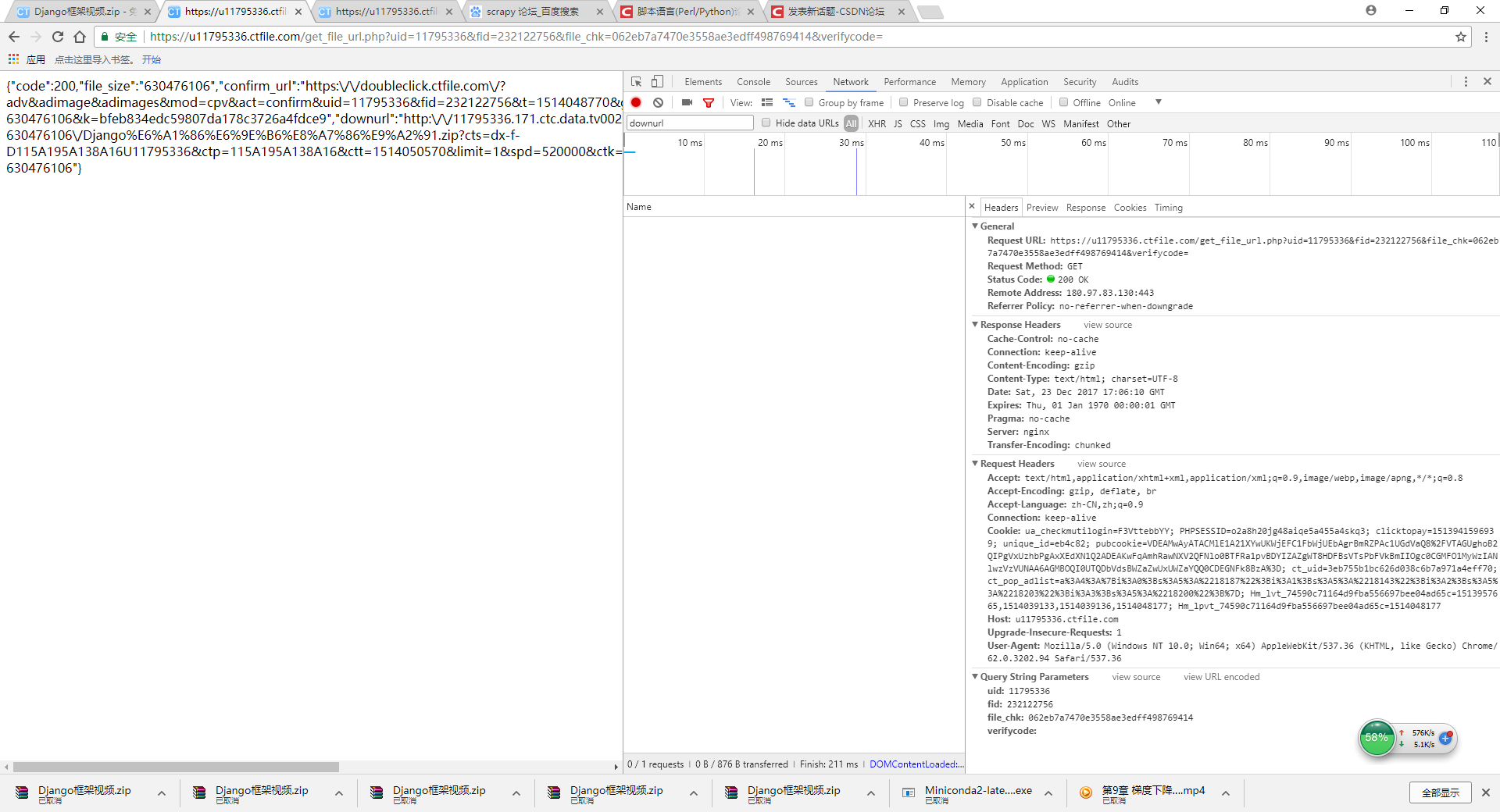
有这么一个目标网址
https://u11795336.ctfile.com/get_file_url.php?uid=11795336&fid=232122756&file_chk=062eb7a7470e3558ae3edff498769414&verifycode=
直接在浏览器中是可以访问,可以请求结果,如下图所示
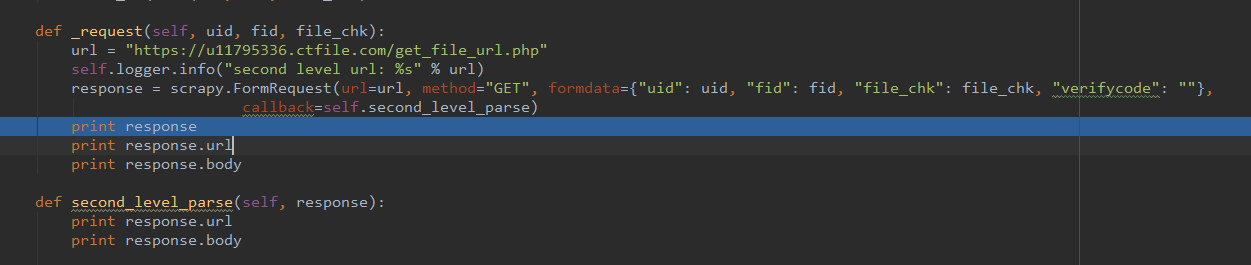
在scrapy代码中,尝试过Request和FormRequest,都无法获取结果,大神帮忙看看是什么原因?
...全文
548
5
打赏
收藏
scrapy框架下Request请求的问题
有这么一个目标网址 https://u11795336.ctfile.com/get_file_url.php?uid=11795336&fid=232122756&file_chk=062eb7a7470e3558ae3edff498769414&verifycode= 直接在浏览器中是可以访问,可以请求结果,如下图所示 在scrapy代码中,尝试过Request和FormRequest,都无法获取结果,大神帮忙看看是什么原因?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
「已注销」
2018-08-20
打赏
举报
回复
method = 'POST'不是GET
CaiNiaoWuZui
2017-12-28
打赏
举报
回复
我试了一下 import requests url = 你的url r = requests.get(url) 返回的信息里有下载地址downurl,应该就是你要的。 downurl = eval(r.text)["downurl"]
Bug_Gee
2017-12-24
打赏
举报
回复
scrapy不是这样用的啊
beike3
2017-12-24
打赏
举报
回复
顶上去,有人知道吗?
beike3
2017-12-24
打赏
举报
回复
折腾两个小时了,没有结果,烦请大神帮忙
selenium结合到
scrapy
框架
。
框架
包括了selenium结合到
scrapy
中,下拉动态获取的网站,然后再
scrapy
的spider中解析数据,进一步的获取再用python的
request
请求
,
请求
后再用
scrapy
的selector解析数据,保存到txt文件中。
scrapy
框架
携带cookie访问淘宝购物车功能的实现代码
scrapy
框架
简介
Scrapy
是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用
框架
,用途非常广泛
框架
的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
scrapy
架构图 crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 Scheduler(调度器): 它负责接受引擎发送过来的
Request
请求
,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 Downloader(下载器):负责
Python爬虫
Scrapy
框架
基础与实战项目案例
学习Python爬虫,怎能少了
Scrapy
框架
?
Scrapy
框架
是爬虫集大成者,让你享受
框架
带来的种种流畅和便利。本课程讲解爬虫相关基础,通过多个实际案例,深入浅出吃透
Scrapy
框架
的架构原理及具体使用方法。学完本课程,你也就上手了
Scrapy
框架
,能独立使用
Scrapy
框架
爬取多数网站内容以及下载文件。----------------------------------------------------------------scarpy是分布式爬虫
框架
。——实现爬取网站数据、提取结构性数据而编写的应用
框架
,用途广泛。
框架
的作用?相当于建高楼大厦,已经做好了
框架
结构,只需要根据具体需求和目标砌墙和搞装修就行啦。使用scarpy,就已经有了爬虫
框架
;只需要根据具体需求和目标,做好少部分模块,就可以很方便爬取到数据资源。
Python利用
Scrapy
框架
爬取豆瓣电影示例
本文实例讲述了Python利用
Scrapy
框架
爬取豆瓣电影。分享给大家供大家参考,具体如下: 1、概念
Scrapy
是一个为了爬取网站数据,提取结构性数据而编写的应用
框架
。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 通过Python包管理工具可以很便捷地对
scrapy
进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install
scrapy
scrapy
的组成结构如下图所示 引擎
Scrapy
Engine,用于中转调度其他部分的信号和数据传递 调度器Scheduler,一个存储
Request
的队列,引擎将
请求
的连接发送给Schedu
Scrapy
框架
使用的基本知识
scrapy
是一个基于Twisted的异步处理
框架
,可扩展性很强。优点此处不再一一赘述。 下面介绍一些概念性知识,帮助大家理解
scrapy
。 一、数据流向 要想熟练掌握这个
框架
,一定要明白数据的流向是怎么一个过程。总结如下: 1.引擎先打开网站,
请求
url。 2.引擎通过调度器以
Request
形式调度url。 3.引擎
请求
下一个url。 4.调度器将url通过Downloader Middlewares发送给引擎 5.Downloader 生成response,通过Downloader Middlewares发送给引擎 6.引擎接收Response 通过spiderMiddleware发送给s
脚本语言
37,719
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


 折腾两个小时了,没有结果,烦请大神帮忙
折腾两个小时了,没有结果,烦请大神帮忙
