

37,720
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
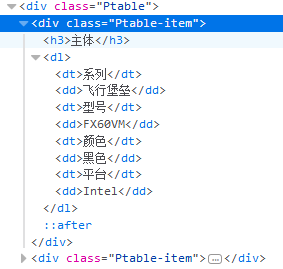



def find_text(find_url):
html = requests.get(find_url, headers=headers).text
soup = BeautifulSoup(html, 'html5lib')
find_texts = soup.find('div', class_='Ptable')
print(find_texts.get_text('\n', strip=True))
print(100 * '*')

