



579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享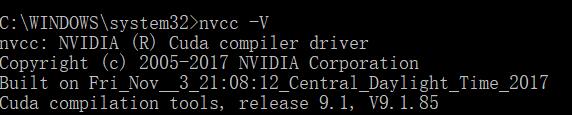
////////////////////////////////////////////////////////////////////////////
//
// Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
//
// Please refer to the NVIDIA end user license agreement (EULA) associated
// with this source code for terms and conditions that govern your use of
// this software. Any use, reproduction, disclosure, or distribution of
// this software and related documentation outside the terms of the EULA
// is strictly prohibited.
//
////////////////////////////////////////////////////////////////////////////
//
// This sample illustrates the usage of CUDA events for both GPU timing and
// overlapping CPU and GPU execution. Events are inserted into a stream
// of CUDA calls. Since CUDA stream calls are asynchronous, the CPU can
// perform computations while GPU is executing (including DMA memcopies
// between the host and device). CPU can query CUDA events to determine
// whether GPU has completed tasks.
//
// includes, system
#include <stdio.h>
// includes CUDA Runtime
#include <cuda_runtime.h>
// includes, project
#include <helper_cuda.h>
#include <helper_functions.h> // helper utility functions
__global__ void increment_kernel(int *g_data, int inc_value)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
bool correct_output(int *data, const int n, const int x)
{
for (int i = 0; i < n; i++)
if (data[i] != x)
{
printf("Error! data[%d] = %d, ref = %d\n", i, data[i], x);
return false;
}
return true;
}
int main(int argc, char *argv[])
{
int devID;
cudaDeviceProp deviceProps;
printf("[%s] - Starting...\n", argv[0]);
// This will pick the best possible CUDA capable device
devID = findCudaDevice(argc, (const char **)argv);
// get device name
checkCudaErrors(cudaGetDeviceProperties(&deviceProps, devID));
printf("CUDA device [%s]\n", deviceProps.name);
int n = 16 * 1024 * 1024;
int nbytes = n * sizeof(int);
int value = 26;
// allocate host memory
int *a = 0;
checkCudaErrors(cudaMallocHost((void **)&a, nbytes));
memset(a, 0, nbytes);
// allocate device memory
int *d_a=0;
checkCudaErrors(cudaMalloc((void **)&d_a, nbytes));
checkCudaErrors(cudaMemset(d_a, 255, nbytes));
// set kernel launch configuration
dim3 threads = dim3(512, 1);
dim3 blocks = dim3(n / threads.x, 1);
// create cuda event handles
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
StopWatchInterface *timer = NULL;
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
checkCudaErrors(cudaDeviceSynchronize());
float gpu_time = 0.0f;
// asynchronously issue work to the GPU (all to stream 0)
sdkStartTimer(&timer);
cudaEventRecord(start, 0);
cudaMemcpyAsync(d_a, a, nbytes, cudaMemcpyHostToDevice, 0);
increment_kernel<<<blocks, threads, 0, 0>>>(d_a, value);
cudaMemcpyAsync(a, d_a, nbytes, cudaMemcpyDeviceToHost, 0);
cudaEventRecord(stop, 0);
sdkStopTimer(&timer);
// have CPU do some work while waiting for stage 1 to finish
unsigned long int counter=0;
while (cudaEventQuery(stop) == cudaErrorNotReady)
{
counter++;
}
checkCudaErrors(cudaEventElapsedTime(&gpu_time, start, stop));
// print the cpu and gpu times
printf("time spent executing by the GPU: %.2f\n", gpu_time);
printf("time spent by CPU in CUDA calls: %.2f\n", sdkGetTimerValue(&timer));
printf("CPU executed %lu iterations while waiting for GPU to finish\n", counter);
// check the output for correctness
bool bFinalResults = correct_output(a, n, value);
// release resources
checkCudaErrors(cudaEventDestroy(start));
checkCudaErrors(cudaEventDestroy(stop));
checkCudaErrors(cudaFreeHost(a));
checkCudaErrors(cudaFree(d_a));
exit(bFinalResults ? EXIT_SUCCESS : EXIT_FAILURE);
}



