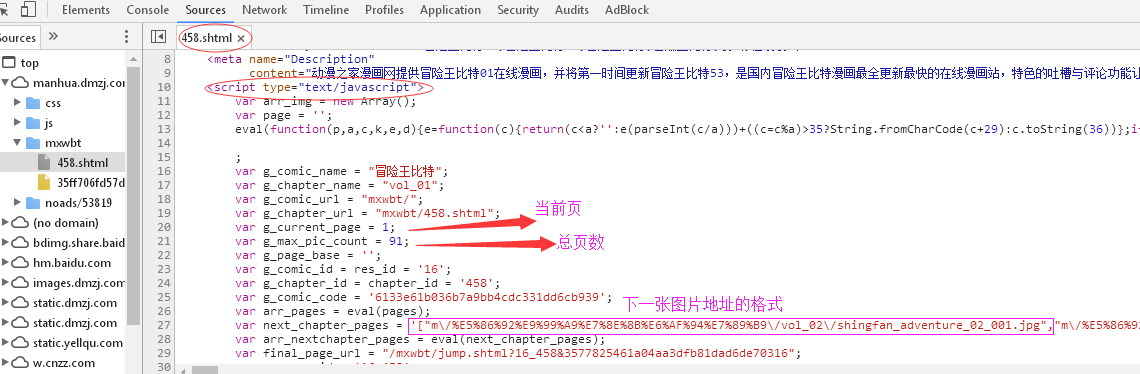
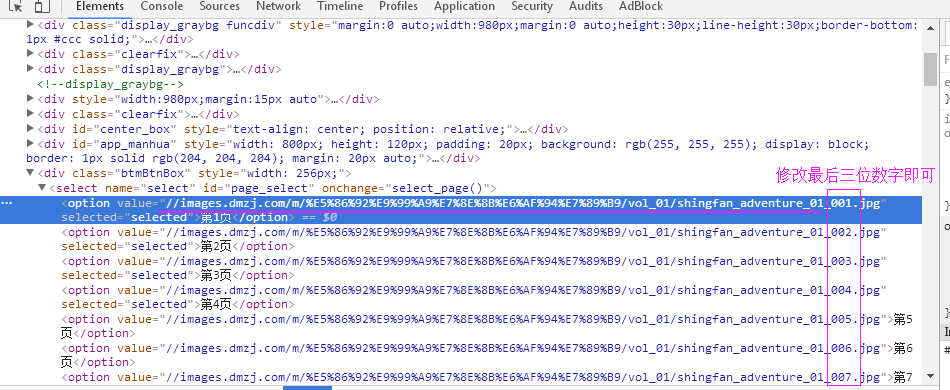
刚学爬虫,有个网站地址:http://manhua.dmzj.com/mxwbt/458.shtml#@page=1
我要得到这个
列表框的图片连接数据,我用webClient 得到源码 是没有这个标签的,之后用了httpwebRequest 发送请求报文 的到的response的hhttp源码也是没有,最后我发现在客户端计算出来添加到页面的,我用了webbrowser的到了源码的标签了,但是有个问题假如不使用webbrowser能得到这些标签吗?刚学不懂,假如我要使用webbrowser得到页面但是都在ui线程里的话会卡住,假如建立线程Thread把线程设置为sta 但是有时候会报错 访问无效的内存!
假如不使用 webbrowser能得到这个列表框的标签吗?



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享