社区
Spark
帖子详情
kafka0.8.1开发程序,启动后发现kafka.consumer.ConsumerIterator占用内存特别大
gjinge
2018-01-13 10:41:23
1、kafka版本0.8.1.1,jdk1.8
2、kafka topic有三个分区,程序中消费者启动3个线程
3、程序启动后占用内存达到2G
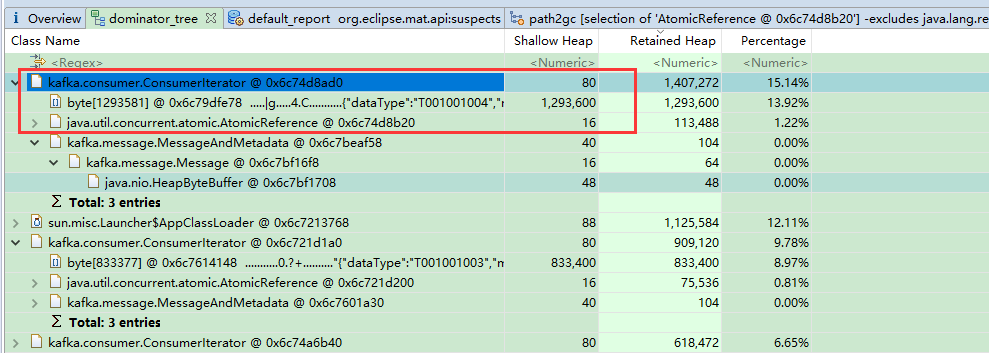
4、使用mat分析 kafka.consumer.ConsumerIterator占了好多,但是并没有内存溢出,维持在2个G不在增加
5、我怀疑是kafka消费者把消息缓存到本地导致的
6、大神给分析分析?
下面是mat的内存分析截图
...全文
430
回复
打赏
收藏
kafka0.8.1开发程序,启动后发现kafka.consumer.ConsumerIterator占用内存特别大
1、kafka版本0.8.1.1,jdk1.8 2、kafka topic有三个分区,程序中消费者启动3个线程 3、程序启动后占用内存达到2G 4、使用mat分析kafka.consumer.ConsumerIterator占了好多,但是并没有内存溢出,维持在2个G不在增加 5、我怀疑是kafka消费者把消息缓存到本地导致的 6、大神给分析分析? 下面是mat的内存分析截图
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
kafka
_2.9.2-
0.8
.2.1.tgz
bin/
kafka
-console-con
sum
er
.sh --zookeep
er
localhost:2181 --topic test --from-beginning produce
启动
的时候参数使用的是
kafka
的端口而con
sum
er
启动
的时候使用的是zookeep
er
的端口; 单机连通性能测试 运行...
kafka
监控命令
kafka
-run-class.sh查看消费了多少条数据
kafka
自带了很多工具类,在源码
kafka
.tools里可以看到: 源码包下载地址:http://archive.apache.org/dist/
kafka
/ 这些类该如何使用呢,
kafka
的设计者早就为我们考虑到了,在${
KAFKA
_HOME}/bin下,有很多的...
kafka
_2.9.2-
0.8
.1集群安装
一、利用安装zookeep
er
的三台服务器做
KAFKA
集群。 服务器 IP地址 端口 服务器1 10.211.55.7 9092 服务器2 10.211.55.8 9092 服务器3 10.211.55.9 9092 1.1下载
kafka
_2.9.2-
0.8
.1 wget ...
Kafka
0.8
.1 Documentation
http://
kafka
.apache.org/documentation.html ...
Kafka
is a distributed, partitioned, replicated commit log s
er
vice. It provides the functionality of a messaging system, but with a u...
Kafka
0.9 新版本con
sum
er
客户端使用介绍
翻译自: ...
kafka
最初时
开发
时, 所带的produc
er
和con
sum
er
client都是Scala所写. 我们逐渐
发现
这些API具有一些限制. high-level的api支持co
Spark
1,258
社区成员
1,168
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

