

22,209
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

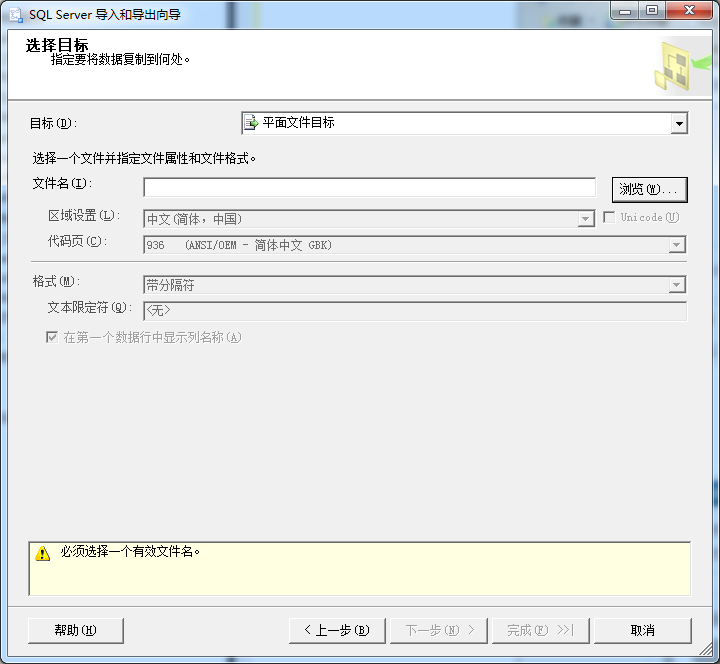 。
。 DROP TABLE #test
CREATE TABLE #test (aa VARCHAR(50), bb VARCHAR(50))
SELECT * FROM #test
INSERT INTO #test
SELECT '11', '22'
UNION
SELECT '22', '22'
UNION
SELECT '33', '33'
UNION
SELECT '44', '44'
UNION
SELECT '44', '44'
ALTER TABLE #test ADD id bigint identity (1, 1)
SELECT * FROM #test

select * * from 表名 order by getdate() offset 1300000000 row fetch first 100000000 rows only

--1. 创建新表,增加标识列(表结构除了标识列,其它按原来的表)
CREATE TABLE t_new(
id BIGINT IDENTITY(1,1) PRIMARY KEY,
c1 INT,
c2 INT,
……
)
--2. 将原表中的所有记录插入到新表
INSERT INTO t_new
(
c1,
c2,
……
)
SELECT c1,c2
FROM t
--3. 分页导出,每次导出 1000 万条.



