

37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#coding=utf-8
import requests
import re
from bs4 import BeautifulSoup
import os
import threading
import Queue
import time
import urllib2
import string
f=open('d:\\nlx.txt','w') #存储路径
NUM=10 #线程数
JOBS=2 #定义末页, 共有900多页,测试阶段设为2
q=Queue.Queue()
f.write(time.strftime('%H:%M:%S'))
def do_somthing(arg):
#print arg
pass
#lock=threading.Lock()
def working():
global lock
while True:
arg=q.get(block=True,timeout=None)
#do_somthing(arg)
res=requests.get(arg)
text=res.text
soup=BeautifulSoup(text,'html.parser') #解析网页源码
f.write(time.strftime('%H:%M:%S')) #写入线程时间
f.write('_'*5 + soup.find('title').string[10:].encode('utf-8')+'_'*5+'\r\n') #写入标题
kk=soup.findAll('div',class_='viewbox') #注释掉往下3行可以正常运行
for st in kk:
f.write(st.text.replace('\n','')) #写入详细文本内容
q.task_done()
res.close()
root_url='http://www.nlx.gov.cn/inter/'
header={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'www.nlx.gov.cn',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
#re_=re.compile('onclick="SwitchTheme.*?<a href="view\.php\?tid=(.*?)" target="_blank">',re.S)
for i in range(NUM):
t=threading.Thread(target=working)
t.setDaemon(True)
t.start()
for i in range(1,JOBS):
host_url='http://www.nlx.gov.cn/inter/?tid=&pages=%s'%i
req=urllib2.Request(host_url)
res=urllib2.urlopen(req)
text=res.read()
soup=BeautifulSoup(text,'html.parser')
a=soup.find('dl',class_='lists')
for aa in a.find_all('a'):
q.put(root_url+aa['href'],True,None) #传详细分页源址
res.close()
q.join()
f.close()

#coding=utf-8
from gevent import monkey,pool
monkey.patch_all()
import os
import gevent
from lxml import etree
import urllib2
import time
jobs=[]
links=[]
p=pool.Pool(30)
urls=[]
f=open('nlx_author.txt','w')
'''
def get_links(url):
r=urllib2.urlopen(url).read()
html=etree.HTML(r)
results=html.xpath('//td[@id="title"]//a')
k+=1
for txt in results:
f.write(txt.text.encode('utf-8')+'\n')
'''
def get_links(url):
r=urllib2.urlopen(url).read()
html=etree.HTML(r)
result=html.xpath('//div[@class="viewbox"]//*')
f.write(result[0].xpath('string(.)').encode('utf-8'))
root_url='http://www.nlx.gov.cn/inter/'
for i in range(1,20): #测试20页,实际有965页
ur='http://www.nlx.gov.cn/inter/?tid=&pages=%d'%i
html=urllib2.urlopen(ur).read()
txt=etree.HTML(html)
results=txt.xpath('//td[@id="title"]//a/@href')
for r in results:
urls.append(root_url+r)
print time.strftime('%H:%M:%S')
for url in urls:
jobs.append(p.spawn(get_links,url))
gevent.joinall(jobs)
print time.strftime('%H:%M:%S')
f.close()

import aiohttp
import asyncio
from lxml import etree
from bs4 import BeautifulSoup
import time
start = time.time()
def parse(page):
f = open(r'info.txt','a',encoding='utf-8')
resp = yield from aiohttp.request("GET","http://www.nlx.gov.cn/inter/?tid=&pages={}".format(page))
body = yield from resp.read()
lists = BeautifulSoup(body,'html5lib').findAll('tr',class_='list')
# selector = etree.HTML(body)
# lists = selector.xpath('//tr[@class="list"]')
for l in lists:
# f.write(l.xpath('string(.)').replace('\n','').strip()+'\n')
f.write(l.text.replace('\n','').strip()+'\n')
f.close()
pages = [n for n in range(1,10)]
tasks = [parse(page) for page in pages]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
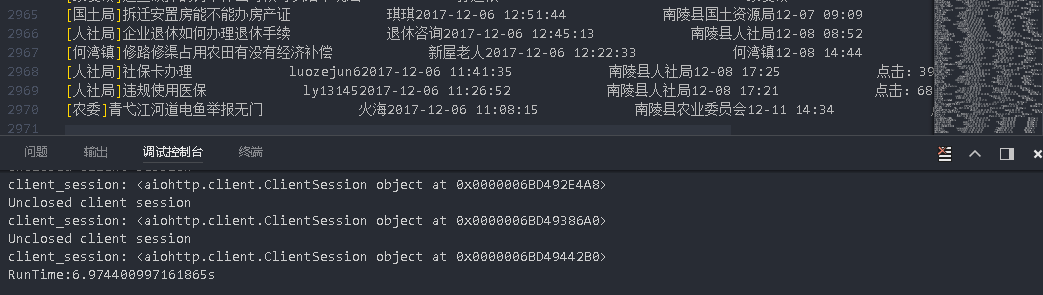
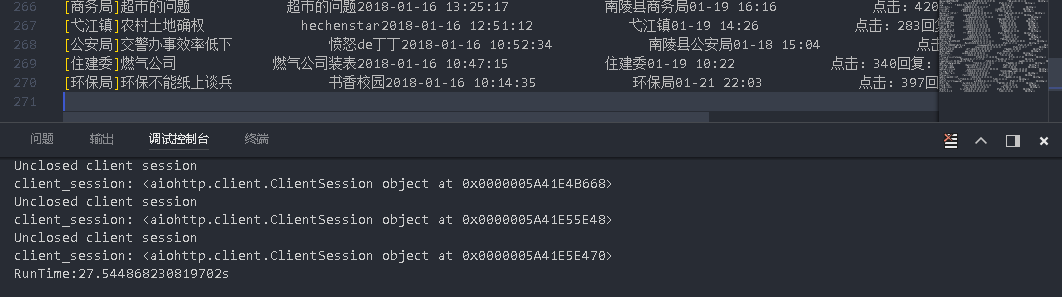
end = time.time()
print("RunTime:{}s".format(end-start))



