

22,299
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


if not object_id(N'Tempdb..#tb') is null
drop table #tb
Go
Create table #tb(id nvarchar(5),[node1] nvarchar(5),[node2] nvarchar(5))
Insert #tb
select N'110',N'1-A',N'1-B' union all
select N'111',N'2-A',N'2-B' union all
select N'112',N'3-A',N'3-B' union all
select N'113',N'4-A',N'4-B'
Go
if not object_id(N'Tempdb..#tb2') is null
drop table #tb2
Go
Create table #tb2(id nvarchar(5),[node1] nvarchar(5),[node2] nvarchar(5),lengh INT)
Insert #tb2
select N'P3',N'1-A',N'2110',N'400' union all
select N'P4',N'2115',N'1-B',N'200' union all
select N'P1',N'2-A',N'2132',N'100' union all
select N'P2',N'2001',N'2-B',N'200'
Go
SELECT a.id,case when a.node1=b.node1 then 0 else cast(b.node1 as int) end as node1,
case when a.node2=b.node2 then 0 else cast(b.node2 as int) end as node2,b.lengh
into #tb3
FROM #tb a left join #tb2 b on a.node1=b.node1 or a.node2=b.node2
select id,SUM(node1) as node1,SUM(node2) as node2,SUM(lengh) as lengh from #tb3
group by id

use Tempdb
go
--> --> 听雨停了-->生成测试数据
if not object_id(N'cribe') is null
drop table cribe
Go
Create table cribe([id] int,[node1] nvarchar(23),[node2] nvarchar(23))
Insert cribe
select 110,N'1-A',N'1-B' union all
select 111,N'2-A',N'2-B' union all
select 112,N'3-A',N'3-B' union all
select 113,N'4-A',N'4-B'
Go
if not object_id(N'detail') is null
drop table detail
Go
Create table detail([id] nvarchar(22),[node1] nvarchar(24),[node2] nvarchar(24),[lengh] int)
Insert detail
select N'p3',N'1-A',N'2110',400 union all
select N'P4',N'2115',N'1-B',200 union all
select N'p1',N'2-A',N'2132',100 union all
select N'p2',N'2001',N'2-B',200
Go
--测试数据结束
;WITH cte AS (
SELECT a.id,
CASE ISNUMERIC(b.node1)
WHEN 1 THEN b.node1
ELSE ''
END AS node1,
CASE ISNUMERIC(b.node2)
WHEN 1 THEN b.node2
ELSE ''
END AS node2,
b.lengh
FROM cribe a
INNER JOIN detail b
ON a.node1 = b.node1
UNION ALL
SELECT a.id,
CASE ISNUMERIC(b.node1)
WHEN 1 THEN b.node1
ELSE ''
END AS node1,
CASE ISNUMERIC(b.node2)
WHEN 1 THEN b.node2
ELSE ''
END AS node2,
b.lengh
FROM cribe a
INNER JOIN detail b
ON a.node2 = b.node2
)
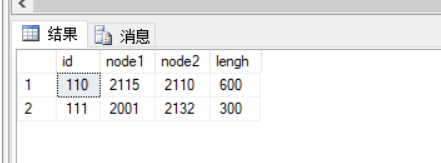
SELECT id,
SUM(ISNULL(CAST(node1 AS INT), 0)) AS node1,
SUM(ISNULL(CAST(node2 AS INT), 0)) AS node2,
SUM(ISNULL(CAST(lengh AS INT), 0)) AS lengh
FROM cte
GROUP BY
id


import csv
import sqlite3
with open('cribe.txt') as cf, open('detail.txt') as df:
cribe_list = list(csv.reader(cf, delimiter='\t'))[1:]
detail_list = list(csv.reader(df, delimiter='\t'))[1:]
con = sqlite3.connect(":memory:")
# 使用:memory:标识,数据库放在内存里,不产生磁盘文件。
cur = con.cursor()
cur.execute('CREATE TABLE cribe(id INT PRIMARY KEY NOT NULL, node1 TEXT, node2 TEXT);')
cur.execute('CREATE TABLE detail(id TEXT, node1 TEXT, node2 TEXT, length INT);')
cur.executemany('INSERT INTO cribe(id, node1, node2) VALUES(?,?,?);', cribe_list)
cur.executemany('INSERT INTO detail(id, node1, node2, length) VALUES(?,?,?,?);', detail_list)
rows = cur.execute("""SELECT N1.id, N2.node1, N1.node2, N1.length + N2.length AS length
FROM
(SELECT C.id, D.node2 AS node2, D.length FROM detail AS D INNER JOIN cribe AS C ON C.node1 = D.node1) AS N1
INNER JOIN
(SELECT C.id, D.node1 AS node1, D.length FROM detail AS D INNER JOIN cribe AS C ON C.node2 = D.node2) AS N2
ON N1.id = N2.id;""")
for row in rows:
print(row)

