


50,530
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享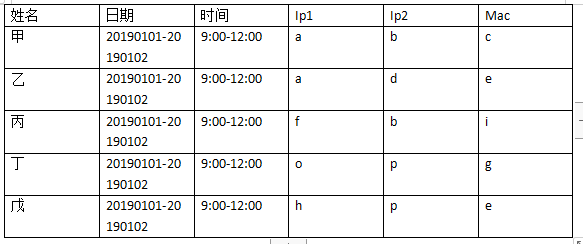


for(int l = merge.size() - 1; l >= 1; l--){
clu.remove(Integer.valueOf(merge.get(l)).intValue());
}
package test.gt70;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Test78 {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
List<Bean> src = new ArrayList();
Bean b1 = new Bean(1, 1, 1, 2, 3);
Bean b2 = new Bean(2, 1, 3, 21, 31);
Bean b3 = new Bean(3, 1, 11, 2, 33);
Bean b4 = new Bean(4, 1, 1, 222, 3333);
Bean b5 = new Bean(5, 1, 14, 24, 31);
src.add(b1);
src.add(b2);
src.add(b3);
src.add(b4);
src.add(b5);
List<Set<Bean>> clu = new ArrayList();
for(int i = 0; i < src.size(); i++){
if(clu.size() == 0){
Set<Bean> tempSet = new HashSet();
tempSet.add(src.get(i));
clu.add(tempSet);
}else {
List<Integer> merge = new ArrayList();
for(int j = 0; j < clu.size(); j++){
for(Bean tempBean: clu.get(j)){
if(src.get(i).compare(tempBean)){
merge.add(j);
break;
}
}
}
if(merge.size() == 0){
Set<Bean> tempSet = new HashSet();
tempSet.add(src.get(i));
clu.add(tempSet);
}else if(merge.size() == 1){
clu.get(merge.get(0)).add(src.get(i));
}else {
for(int k = 1; k < merge.size(); k++){
clu.get(merge.get(0)).addAll(clu.get(merge.get(k)));
}
for(int l = merge.size(); l > 1; l--){
clu.remove(merge.get(l));
}
}
}
}
System.out.println(clu);
}
static class Bean{
public int name;
public int time;
public int ip1;
public int ip2;
public int ip3;
public Bean(int name, int time, int ip1, int ip2, int ip3) {
super();
this.name = name;
this.time = time;
this.ip1 = ip1;
this.ip2 = ip2;
this.ip3 = ip3;
}
public boolean compare(Bean that){
if(this.ip1 == that.ip1 || this.ip2 == that.ip2 || this.ip3 == that.ip3)
return true;
else
return false;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return this.name + "";
}
}
}


