社区
C#
帖子详情
爬虫解析网页问题
hanghangz
2019-07-10 02:27:02
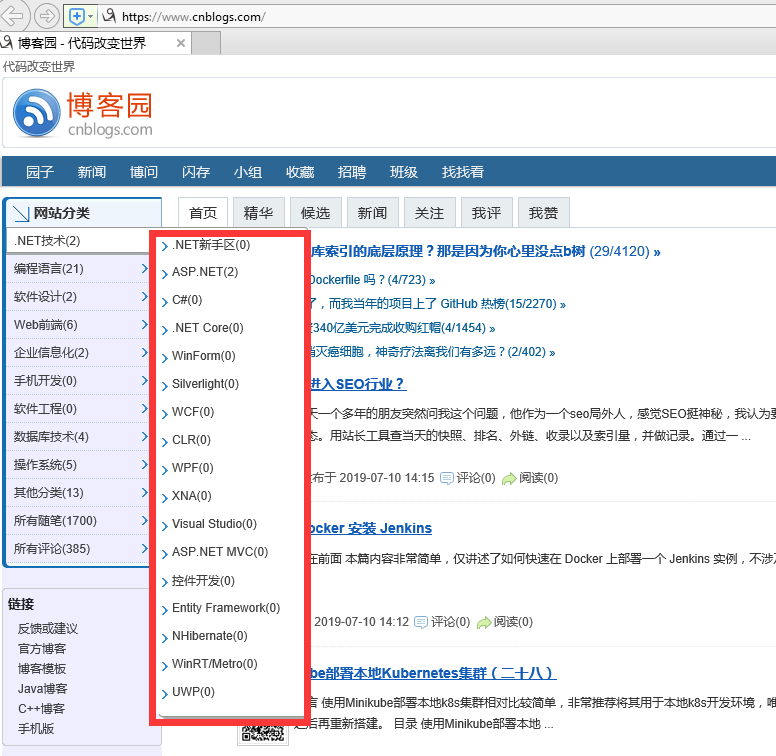
最近在玩爬虫,好多年前做过这个事情.忘记得差不多了哦.
如图中红框所示.
查看html源码,不能看到文本信息. 只能在它上一级(.NET技术)看到一个onmouseover事件.
onmouseover="cateShow(108698)"
请问红框列表怎么获取?
...全文
130
2
打赏
收藏
爬虫解析网页问题
最近在玩爬虫,好多年前做过这个事情.忘记得差不多了哦. 如图中红框所示. 查看html源码,不能看到文本信息. 只能在它上一级(.NET技术)看到一个onmouseover事件. onmouseover="cateShow(108698)" 请问红框列表怎么获取?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
JasonShih
2019-07-10
打赏
举报
回复
Hover的内容存放在Id为"cate_content_block_"+n的div中,其中n是当前条目的id,比如你提到的108698.通过Id获取该元素,即可抓取其中的内容。
听雨停了
2019-07-10
打赏
举报
回复
这个列表在html源码中是有的,onmouseover只是添加了一个class上去。怎么获取我就不知道了
python
爬虫
爬取
网页
数据并
解析
数据
主要介绍了python
爬虫
如何爬取
网页
数据并
解析
数据,帮助大家更好的利用
爬虫
分析
网页
,感兴趣的朋友可以了解下
Python
爬虫
解析
网页
内容
Python
爬虫
是一种自动化程序,可以模拟人类用户访问
网页
,获取
网页
中的内容。
爬虫
在信息采集、数据分析和网络监测等领域有着广泛的应用。在
爬虫
过程中,
解析
网页
内容是非常重要的一步。Python提供了许多强大的库和工具,用于
解析
网页
内容。其中,BeautifulSoup库是一个流行的库,可以帮助我们方便地
解析
HTML和XML文档。在本文中,我们将介绍如何使用Python和BeautifulSoup库来
解析
网页
内容,并提取我们所需的信息。
Python
爬虫
解析
网页
的3种方式,值得收藏
一般来说当我们爬取
网页
的整个源代码后,是需要对
网页
进行
解析
的。 Python
网页
解析
正则匹配
解析
:BeautifulSoup
解析
项目实战 正常的
解析
方法有三种 ①:正则匹配
解析
②:BeatuifulSoup
解析
③:lxml
解析
正则匹配
解析
: 在之前的学习中,我们学习过
爬虫
的基本用法,比如/s,/d,/w,*,+,?等用法,但是在对爬取到的
网页
进行
解析
的时候,仅仅会这些基础的用法,是不够用的,因此我们需要了解Python中正则匹配的经典函数。 re.match runoob解释:re.match尝试从字
Python
爬虫
解析
网页
的4种方式 值得收藏
用Python写
爬虫
工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情。 我们知道,
爬虫
的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行
解析
,按照自己的想法提取出想要的数据,所以今天我们主要来讲四种在Python中
解析
网页
HTML内容的方法,各有千秋,适合在不同的场...
python
爬虫
爬取
网页
数据
python
爬虫
爬取
网页
数据
C#
110,534
社区成员
642,576
社区内容
发帖
与我相关
我的任务
C#
.NET技术 C#
复制链接
扫一扫
分享
社区描述
.NET技术 C#
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧
+ 用AI写文章







 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


