目前显卡的浮点性能远高于CPU,一些数据运算密集型的程序采用显卡运算后,性能有数量级的提升。但更多的科学计算仅部分模块是密集型的,例如稀疏矩阵的LU分解,具体效果显然依赖于具体问题。以下是稀疏矩阵求解(GSS)调用Nvidia CUDA 1.1的初步测试结果,供大家参考。
稀疏矩阵求解是科学计算的基本模块,往往是时间瓶颈,因此是高性能计算的重要研究方向,其中就包括稀疏LU分解的高效实现。通过多波前法等算法,稀疏LU分解主要的运算量由BLAS-3完成,而BLAS-3是典型的密集型运算,适合由GPU来完成。其它运算则仍由CPU来处理,尤其是内部复杂的逻辑指令,是不适合放到GPU上的。稀疏LU分解的令一个问题是需要大量存储,往往超过显存的容量,这使得整个程序无法用kernel实现,必然带来额外的数据交换。总之,许多科学计算都会遇到类似的问题:1、仅部分运算是密集型;2、程序空间大于显存空间,带来数据交换等额外开销。
测试环境
1 测试集
采用了来自UF sparse matrix collection 的12个算例,具有一定的代表性,见下表。
2 硬件
AMD Athlon 64X2 4000+。2G DDR2 667内存。
Nvidia 8600 GT 256M DDR3显存,实测带宽:host->device: 1.5G/s, device->host: 0.67G/s
3 软件:
稀疏求解器采用GSS 2.0(GRUS SPARSE SOLVER)。对比了GSS采用MKL-BLAS与CUBLAS的数值分解时间,CUBLAS来自Nvidia CUDA 1.1, 实测性能远高于MKL-BLAS,但调用CUBLAS又需要额外的开销。实测结果见下表,其中比值是采用CUBLAS的时间与采用MKL的时间之比。
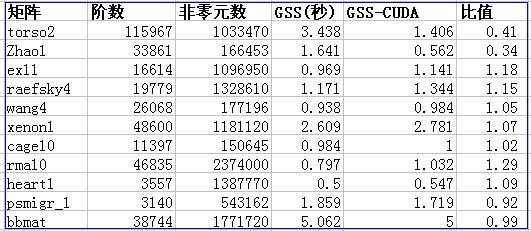
就测试结果看,CUBLAS和MKL-BLAS总体上相当,都有占优的例子。例如ZHAO1算例,GSS采用CUBLAS速度提高3倍;而rma10算例,采用CUBLAS后要慢30%。这是由于采用CUBLAS需要一些额外的开销,这里主要是把计算结果从显卡复制到内存的时间。在某些情况下,这些额外的开销抵消了CUBLAS本身节省的时间。
在这个初步的测试中,GPU的潜力并未被充分挖掘,例如可以将更多的模块转化为kernel。但在进一步优化之前,我宁可等待双精度CUBLAS的发布。对于矩阵求解来说,单精度版本只有参考价值,例如INTEL PARDISO等商业求解器甚至不提供单精度版本。
结论:
1、部分密集型运算的科学计算,仍可通过GPU提高性能。
2、双精度GPU运算是急需解决的问题。比如要从一辆老爷车和一架带炸弹的飞机中选择,我想大多数人会选择前者出行。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

