SQL Server 2008连载之存储结构——聚集索引
聚集索引即基于数据行的键值在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
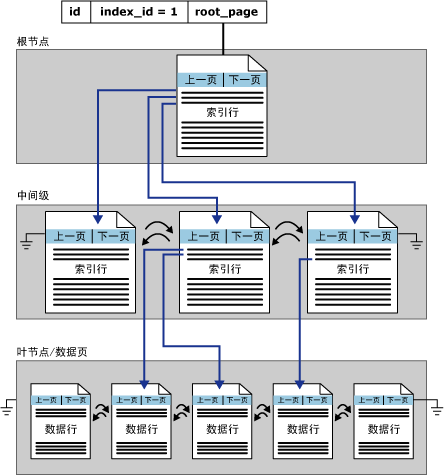
从某种程度上,聚集索引即数据,这句话是有道理的;但正如同其他索引一样,聚集索引也是按 B 树结构进行组织的。既然是B树组织,那么就有叶子结点和非叶子节点之分。聚集索引B 树的顶端节点称为根节点;聚集索引中的底层节点称为叶节点。在根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中。
因此可以这么说,聚集索引的叶子结点存储的是按聚集索引顺序排列的数据本身,而中间结点和根节点则在维护索引和其层级。
对于某个聚集索引, sys.system_internals_allocation_units 中的 root_page 列指向该聚集索引某个特定分区的顶部。SQL Server 将从索引中向下移动以查找与某个聚集索引键对应的行。为了查找键的范围,SQL Server 将在索引中移动以查找该范围的起始键值,然后用向前或向后指针在数据页中进行扫描。为了查找数据页链的首页,SQL Server 将从索引的根节点沿最左边的指针进行扫描。
drop table testUniqueCluster
drop table testNonUniqueCluster
CREATE TABLE testUniqueCluster
(
name CHAR(900),
remark CHAR(1100)
)
CREATE UNIQUE CLUSTERED INDEX ix_testUniqueCluster
ON testUniqueCluster(name)
INSERT INTO testUniqueCluster VALUES('B','BBB1')
INSERT INTO testUniqueCluster VALUES('A','AAA1')
CREATE TABLE testNonUniqueCluster
(
name CHAR(900),
remark CHAR(1100)
)
CREATE CLUSTERED INDEX ix_testNonUniqueCluster
ON testNonUniqueCluster(name)
INSERT INTO testNonUniqueCluster VALUES('B','BBB2')
INSERT INTO testNonUniqueCluster VALUES('B','BBB1')
INSERT INTO testNonUniqueCluster VALUES('A','AAA1')
SELECT c.name,a.type_desc,
total_pages,used_pages,data_pages,
testdb.dbo.f_get_page(first_page) first_page_address,
testdb.dbo.f_get_page(root_page) root_address,
testdb.dbo.f_get_page(first_iam_page) IAM_address
FROM sys.system_internals_allocation_units a,sys.partitions b,sys.objects c
WHERE a.container_id=b.partition_id and b.object_id=c.object_id
AND c.name in ('testUniqueCluster','testNonUniqueCluster')
TRUNCATE TABLE tablepage;
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testUniqueCluster,1)');
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testNonUniqueCluster,1)');
SELECT
b.name table_name,
CASE WHEN c.type=0 THEN '堆'
WHEN c.type=1 THEN '聚集'
WHEN c.type=2 THEN '非聚集'
ELSE '其他'
END index_type,
c.name index_name,
PagePID,IAMPID,ObjectID,IndexID,Pagetype,IndexLevel,
NextPagePID,PrevPagePID
FROM tablepage a,sys.objects b,sys.indexes c
WHERE A.ObjectID=b.object_id
AND A.ObjectID=c.object_id
AND a.IndexID=c.index_id
name Type_desc used_pages data_pages first_page_address root_address IAM_address
testUniqueCluster IN_ROW_DATA 2 1 1:233 1:233 1:234
testNonUniqueCluster IN_ROW_DATA 2 1 1:235 1:235 1:236
下面我们用dbcc命令介绍一下聚集索引的构造。
DBCC TRACEON(3604)
DBCC PAGE(testDB,1,233,1)
m_type = 1
5E3BC060: 1000d407 42202020 20202020 20202020 ?....B
....
5E3BC3E0: 20202020 20202020 42424231 20202020 ? BBB1
...
5E3BC830: 20202020 0200fc10 00d40741 20202020 ? .......A
...
5E3BCBB0: 20202020 20202020 20202020 20202041 ? A
5E3BCBC0: 41413120 20202020 20202020 20202020 ?AA1
...
5E3BD000: 20202020 20202020 20202002 00fc0000 ? .....
OFFSET TABLE:
Row - Offset
1 (0x1) - 96 (0x60)
0 (0x0) - 2103 (0x837)
DBCC PAGE(testDB,1,235,1)
5E3BC060: 1000d407 42202020 20202020 20202020 ?....B
...
5E3BC3E0: 20202020 20202020 42424232 20202020 ? BBB2
...
5E3BC830: 20202020 0300f830 00d40742 20202020 ? ...0...B
...
5E3BCBB0: 20202020 20202020 20202020 20202042 ? B
5E3BCBC0: 42423120 20202020 20202020 20202020 ?BB1
...
5E3BD000: 20202020 20202020 20202003 00f80100 ? .....
5E3BD010: df070100 00001000 d4074120 20202020 ?..........A
...
5E3BD390: 20202020 20202020 20202020 20204141 ? AA
5E3BD3A0: 41312020 20202020 20202020 20202020 ?A1
...
5E3BD7E0: 20202020 20202020 20200300 f8000021 ? .....!
OFFSET TABLE:
Row - Offset
2 (0x2) - 2103 (0x837)
1 (0x1) - 96 (0x60)
0 (0x0) - 4118 (0x1016)
其中红颜色的部分为每行的行头部分,蓝颜色部分为每行的结尾部分。
大家可以看到m_type=1即数据页面,大家应该很奇怪吧,为什么明明是聚集索引,却是数据页面呢?正如上面所提到,聚集索引的叶子页面即数据页面。因为这个表只有2~3条记录,所以root页面还达不到需要分为B树的程度,所以该root页面也是叶子页面。
我们首先来看一下1000d407的行头部如何解释
第0位 第1-3位 第4位 第5位 第6-7位 1个字节 2个字节
0 000 1 0 00 00 d407
10 00 2004
始终为0 0表示主记录
3表示索引记录
5表示幻影索引记录 存在NULL位图 存在变长字段 保留 状态B保留 字段长度
即该行为不存在变长字段的主记录,且字段长度为2004个字节。
那30 00d407该如何解释呢?即00001100即存在变长字段的主记录,我们的testNonUniqueCluster怎么会存在变长字段呢?
在该非唯一聚集索引表中,我们首先插入记录B、BBB2记录,再插入B、BBB1记录,这个时候对于非唯一索引如何去识别呢?SQL Server在重复行的行尾增加了8个额外的字节,稍后我们再分析行尾。
在testUniqueCluster表中正常的行尾为0200fc,其解释如下0200表示该表有2个字段,fc则为1111 1100,即前2个字段不为空。
而对于testNonUniqueCluster表正常的行尾应为0300 f8,其解释如下0300表示该表有3个字段,f8则为1111 1000,即前3个字段不为空;很显然SQL Server把非唯一索引的标识符也当做字段了;但的的确确因为B、BBB2和A、AAA1在插入的时候是唯一的,所以不需要这个字段。
我们接下来看看B、BBB1行的尾部03 00f8 0100 df070100 0000,0300f8解释同上,0100即1表示该表一共有1个变长字段,df07即2015变长字段结束的位置,最后四个字节0100 0000为非唯一索引的标识符,换算成10进制即1。
从页面中记录的顺序我们其实可以看得出来,聚集索引的行的物理顺序与行的实际存储没有太大关系,而是与记录槽的顺序的有关。
既然我们再谈论聚集索引,那就不能不说聚集索引的中间节点和根节点了,
为了简化处理,我们使用testUniqueCluster来做进一步的研究。
该表包含2个定长字段,合计2000字节,加上相应的头部的4个管理字节和尾部的3个管理字节,共计2007个字节,页头还需要96个字节,每行的偏移量需要2个字节,所以单页8192字节只能容纳大概4条记录。也就是说当我们完成第五条记录时就应该产生分页现象了。
INSERT INTO testUniqueCluster VALUES('C','CCC1')
INSERT INTO testUniqueCluster VALUES('D','DDD1')
INSERT INTO testUniqueCluster VALUES('E','EEE1')
TRUNCATE TABLE tablepage;
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testUniqueCluster,1)');
SELECT
b.name table_name,
CASE WHEN c.type=0 THEN '堆'
WHEN c.type=1 THEN '聚集'
WHEN c.type=2 THEN '非聚集'
ELSE '其他'
END index_type,
c.name index_name,
PagePID,IAMPID,ObjectID,IndexID,Pagetype,IndexLevel,
NextPagePID,PrevPagePID
FROM tablepage a,sys.objects b,sys.indexes c
WHERE A.ObjectID=b.object_id
AND A.ObjectID=c.object_id
AND a.IndexID=c.index_id
以下为该表的详细页面分布
index_name PagePID IAMPID IndexID Pagetype IndexLevel NextPagePID PrevPagePID
… 234 NULL 1 10 NULL 0 0
… 233 234 1 1 0 248 0
… 239 234 1 2 1 0 0
… 248 234 1 1 0 0 233
我们再用sys.system_internals_allocation_units来看一下该表的页面概要信息。
name total_pages used_pages data_pages first_address root_address IAM_address
testUniqueCluster 4 4 2 1:233 1:239 1:234
从以上两个表格,我们可以看出IAM页面未发生变化,仍旧是第234页面。
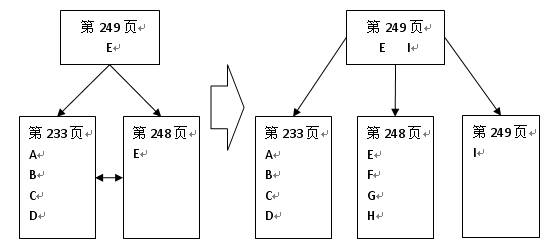
根节点页面发生了变化,现在是第239页面,pagetype=2,即索引页面,新增加了一个数据页面第248页面,第233页面仍继续存在;同时在第248和233个页面之间存在着互链的关系。
同时观察一下数据,发现在第233页中存在A、AAA1;B、BBB1;C、CCC1;D、DDD1等4条记录,而第248页中则存在E、EEE1记录,也就是说对于SQL Server来说索引的分裂应该是以最小代价进行,而不是完全均衡策略。
再让我们用DBCC PAGE(1,testDB,239,3)观察一下根节点的内容。
FileId PageId Row Level ChildFileId ChildPageId name (key) KeyHashValue
1 239 0 1 1 233 NULL (6f4251ce1f81)
1 239 1 1 1 248
(201c8aeace10)
因为这是个索引的非叶子节点,所以连表现形式都简化了。
FieldId为当前页面的文件ID
PageId为当前页面的页面ID
Row表示为当前的slot槽
Level为1表示为当前为非叶子节点
ChildFieldId表示为插槽号指向的页面的文件ID
ChildPageId表示为插槽号指向的页面的页面ID
Name表示为当前索引的键值
KeyHashValue为SQL Server键值的内部表示的hash值。
即E右侧的数据指向第248页面,而左侧的则指向第233页面。
那么再让我们插入4条记录看看根页面的变化。
INSERT INTO testUniqueCluster VALUES('C','CCC1')
INSERT INTO testUniqueCluster VALUES('D','DDD1')
INSERT INTO testUniqueCluster VALUES('E','EEE1')
DBCC PAGE(1,testDB,239,3)
FileId PageId Row Level ChildFileId ChildPageId name (key) KeyHashValue
1 239 0 1 1 233 NULL (6f4251ce1f81)
1 239 1 1 1 248
(201c8aeace10)
1 239 2 1 1 249
(201cbd800c11)
现在我们可以看到在根节点上又增加了一个新的键值I,凡是大于等于I的记录均指向第249页;结合前面的描述,我们可以得到下面的索引结构变化示意图。




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享













