


33,025
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

#include<iostream>
#include<unordered_map>
#include<set>
#include<windows.h>
#include<ctime>
using namespace std;
const int MAX=1500;
const int MAXN=5000000;
int main()
{
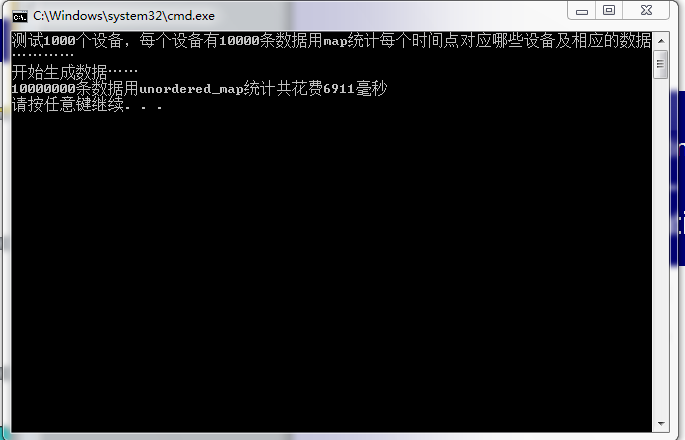
cout<<"测试1000个设备,每个设备有10000条数据用map统计每个时间点对应哪些设备及相应的数据…………"<<endl;
int i;
set<long long> nset;
unordered_map<long long,unordered_map<int,float>> nmap;
set<long long>::const_iterator iter;
unordered_map<long long,float>::iterator iter1;
unordered_map<long long,unordered_map<int,float>>::iterator iter2;
//产生1000个时间间隔,保存在set中
srand(time(NULL));
while(nset.size()!=1000)
{
nset.insert(((rand()*rand())%MAX));
}
cout<<"开始生成数据……"<<endl;
DWORD stime = GetTickCount();
for(i=0,iter=nset.begin();i<1000&&iter!=nset.end();i++,iter++)
{
unordered_map<long long,float> map1;
srand(time(NULL));
for(int j=0;j<10000;j++)
{
map1.insert(pair<long long,float>((*iter)*j,((rand()*rand())%MAXN)));
}
for(iter1=map1.begin();iter1!=map1.end();iter1++)
{
if((iter2=nmap.find(iter1->first))!=nmap.end())
iter2->second.insert(pair<int,float>(i+1,iter1->second));
else
{
unordered_map<int,float> map2;
map2.insert(pair<int,float>(i+1,iter1->second));
nmap.insert(pair<long long,unordered_map<int,float>>(iter1->first,map2));
}
}
}
DWORD etime = GetTickCount();
cout<<"10000000条数据用unordered_map统计共花费"<<etime-stime<<"毫秒"<<endl;
}


 关键是你要用release跑,debug会慢很多很多很多
关键是你要用release跑,debug会慢很多很多很多 [/quote]
能给一下你机子的配置吗?我在我自己的机子上跑了半天都没出来时间……你13秒已经算很快了[/quote]
Intel(R) Core(TM)2 Quad CPU[/quote]
能给一下你机子的配置吗?我在我自己的机子上跑了半天都没出来时间……你13秒已经算很快了
[/quote]
能给一下你机子的配置吗?我在我自己的机子上跑了半天都没出来时间……你13秒已经算很快了[/quote]
Intel(R) Core(TM)2 Quad CPU[/quote]
能给一下你机子的配置吗?我在我自己的机子上跑了半天都没出来时间……你13秒已经算很快了