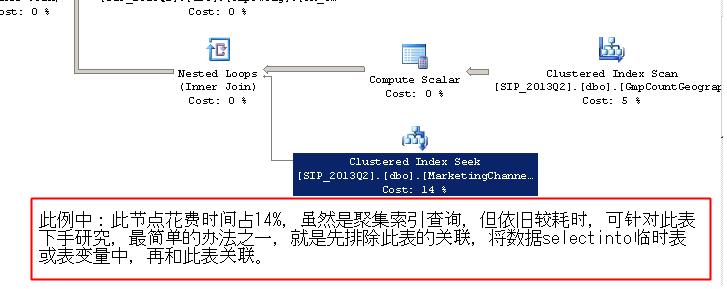
如果不“推到了重新设计”,而你的问题如果可以模式化地解决的话,那么我认为你可以把你的模式推广到各个国营企业计算中心去了,一定可以出名。 因此你的问题描述具有普遍性,我们经常看到那些原本用3万块钱就能搞定的计算,用80万元买来的小型机也要比人家计算速度慢20倍,而这些人还天天嚷着要增加机器否则年底就无法再支持业务报表了。 如果你的问题可以按照某种模式来统一解决,那么可以去宣传一下。
111,131
社区成员
642,542
社区内容
加载中
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享