5,007
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


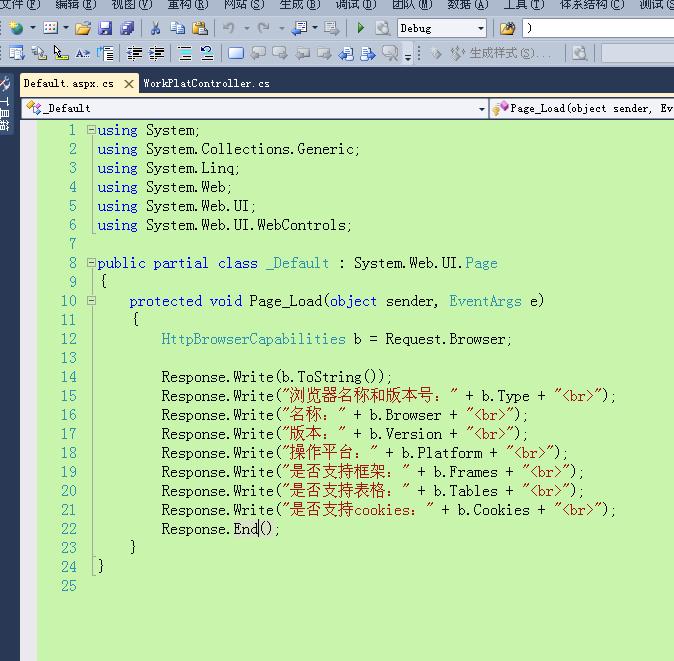
protected void Page_Load(object sender, EventArgs e)
{
HttpBrowserCapabilities b = Request.Browser;
Response.Write(b.ToString());
Response.Write("浏览器名称和版本号:" + b.Type + "<br>");
Response.Write("名称:" + b.Browser + "<br>");
Response.Write("版本:" + b.Version + "<br>");
Response.Write("操作平台:" + b.Platform + "<br>");
Response.Write("是否支持框架:" + b.Frames + "<br>");
Response.Write("是否支持表格:" + b.Tables + "<br>");
Response.Write("是否支持cookies:" + b.Cookies + "<br>");
Response.End();
}