写错了,1000万
昨天有位高手提到“如果数据量不大的话要走Index Seek” 我这边的实际情况是从4亿条数据中频繁的查询出100万条以内的数据 用现在的方案会不会适得其反? 因为我不知道100万的数据量算大还是算小
27,579
社区成员
68,558
社区内容
加载中
试试用AI创作助手写篇文章吧
 热情的菜鸟 2013-10-12 10:15:15
热情的菜鸟 2013-10-12 10:15:15 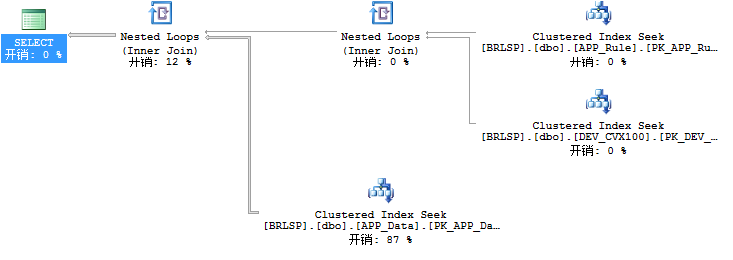


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


