62,614
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
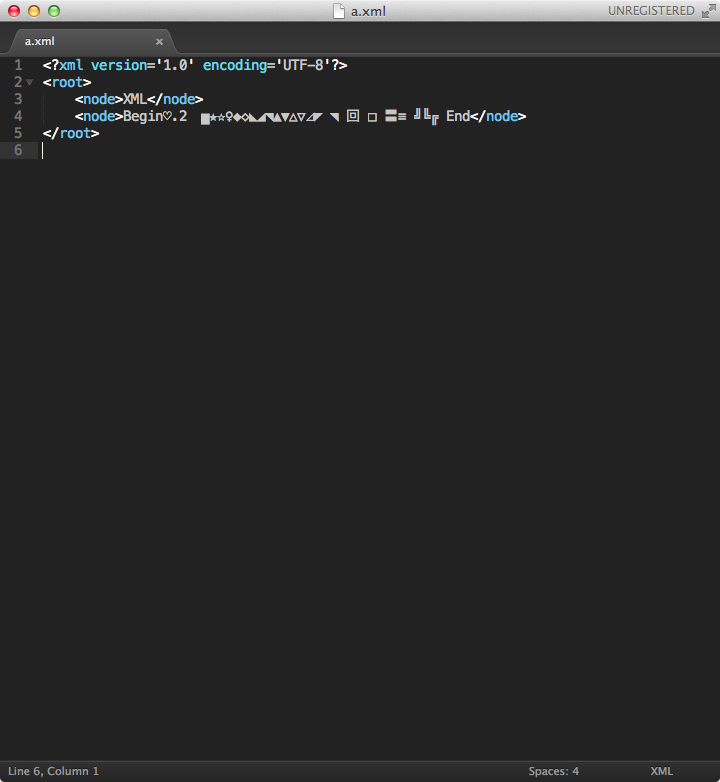
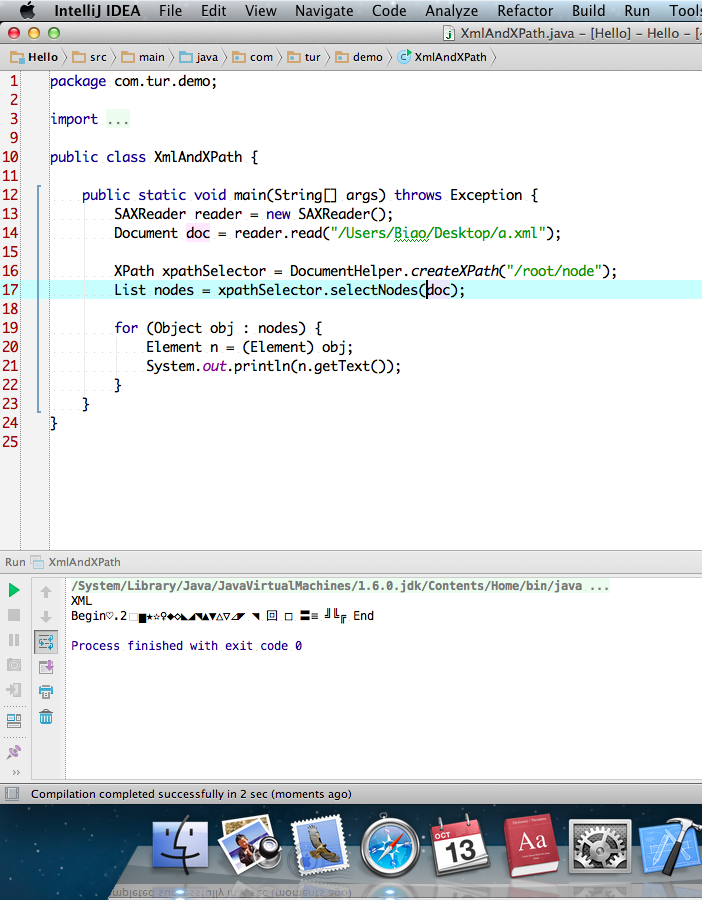
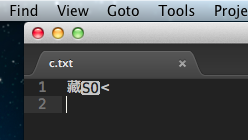
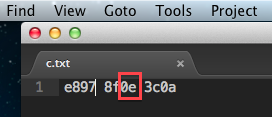
分享 这样的字符。现在由于xml文件太大,不可能把所有的无效字符都找出来,替换掉。现在怎样解析这个xml文件?
这样的字符。现在由于xml文件太大,不可能把所有的无效字符都找出来,替换掉。现在怎样解析这个xml文件?


<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE PERSONS [
<!ENTITY nbsp " ">
<!ENTITY copy "©">
<!ENTITY reg "®">
<!ENTITY trade "™">
<!ENTITY mdash "—">
<!ENTITY ldquo "“">
<!ENTITY rdquo "”">
<!ENTITY pound "£">
<!ENTITY yen "¥">
<!ENTITY euro "€">
]>
<PERSONS>
<person>
<summary>L仔,Worldwide,Bboyworld DJ成員,美國Dragon Diggers
DJ團長,『壹陆叁』創辦人,廣州Energy音樂總監,周館弟子,KC劍球隊員,唱盤主義,老巨蟹,黑膠收藏</summary>
</person>
</PERSONS>